Neural Graph Matching Networks for Chinese Short Text Matching
https://aclanthology.org/2020.acl-main.547.pdf
1.摘要
对于中文短文本匹配,通常基于词粒度而不是字粒度。但是分词结果可能是错误的、模糊的或不一致的,从而损害最终的匹配性能。比如下图:字符序列“南京市长江大桥”经过不同的分词可能表达为不同的意思。
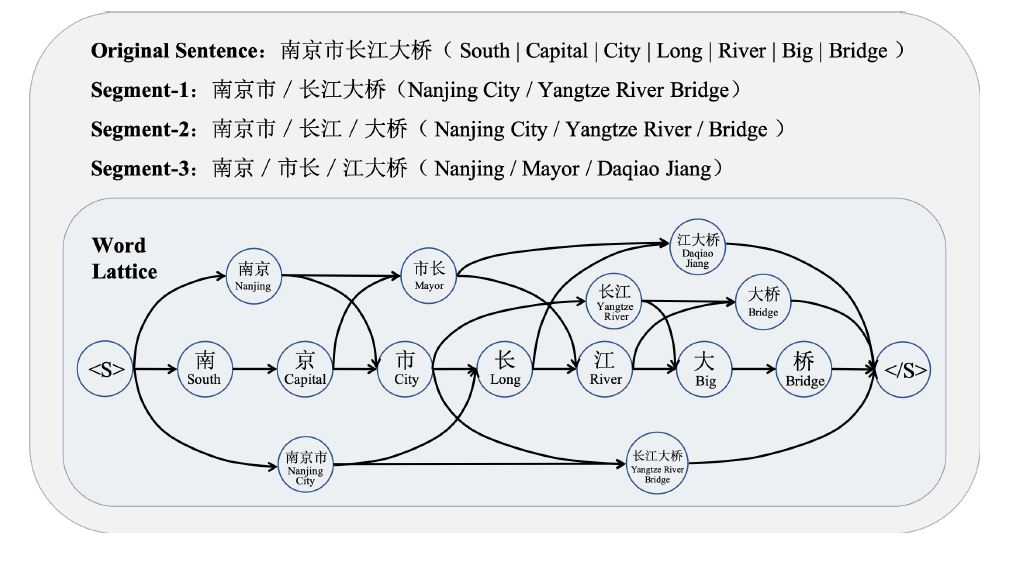
为了解决这个问题,作者提出了一种基于图神经网络的中文短文本匹配方法。不是将句子分割成一个单词序列,而是保留所有可能的分割路径,形成一个Lattice(segment1,segment2,segment3),如上图所示。
2.问题定义
将两个待匹配中文短文本分别定义为$S_a=\left \{ C_1^a,C_2^a,…,C_{t_a}^a \right \}$,$S_b=\left \{ C_1^b,C_2^b,…,C_{t_b}^b \right \}$,其中$C_i^a$表示句子$a$第$i$个字,$C_j^b$表示句子$b$第$j$个字,$t_a$,$t_b$分别表示两个句子的长度。$f(S_a,S_b)$是目标函数,输出为两个文本的匹配度。词格图用$G=(\nu,\xi)$表示,其中$\nu$是节点集,包括所有字符序列。$\xi$表示边集,如果$\nu$中两个顶点$v_i$和$v_j$相邻,那么就存在一个边为$e_{ij}$。$N_{fw}(v_i)$表示节点$v_i$ 正向的所有可达节点的集合,$N_{bw}(v_i)$表示节点$v_i$ 反向的所有可达节点的集合。句子$a$的词格图为$G^a(\nu_a,\xi_a)$,句子$b$的词格图为$G^b(\nu_b,\xi_b)$。
3.模型结构
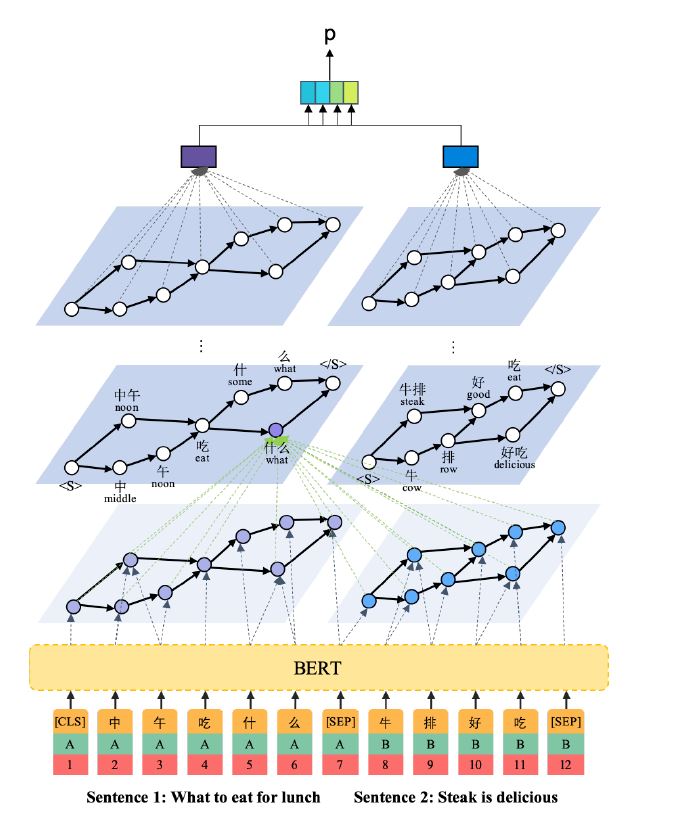
模型分成3个部分,1.语言节点表示 2.图神经匹配 3.相关性分类器
3.1 语言节点表示
这一部分基于BERT的结构。BERT的token表示基于字粒度,可以得到$\left \{ [CLS],C_1^a,C_2^a,…,C_{ta}^a,[SEP],C_1^b,C_2^b,…,C_{t_b}^b,[SEP] \right \}$,如上图所示。BERT的输出为各个字的Embedding,$ \left \{\textbf{C}^{CLS},\textbf{C}_1^a,\textbf{C}_2^a,…,\textbf{C}_{t_a}^a,\textbf{C}^{SEP},\textbf{C}_1^b,\textbf{C}_2^b,…,\textbf{C}_{t_b},\textbf{C}^{SEP} \right \}$。
3.2 图神经匹配
初始化:假设节点$v_i$包含$n_i$个连续字符,起始字符位置为$s_i$,即$ \left \{C_{s_i},C_{s_{i+1}},…,C_{s_{i}+n_i-1} \right \}$,这里$v_i$表示句子$a$或者$b$的结点。$V_i=\sum_{k=0}^{n_i-1}\textbf{U}_{s_i+k}\odot\textbf{C}_{s_i+k}$,其中$\odot$表示两个向量对应各个元素相乘。特征识别分数向量$\textbf{U}_{s_i+k}=softmax(FFN(\textbf{C}_{s_i+k}))$,$FFN$为两层。$h$为结点的向量表示,将$h_i^0$等于$V_i$
Message Propagation : 对于第$l$次迭代,$G_a$中某个结点$v_i$由如下四个部分组成
其中$\alpha_{ij},\alpha_{ik},\alpha_{im},\alpha_{iq}$是注意力系数,$W^{fw},W^{bw}$是注意力系数参数
然后定义两种信息为$m_i^{self}\triangleq[m_i^{fw},m_i^{bw}],m_i^{cross}\triangleq[m_i^{b1},m_i^{b2}]$
Representation Updating:得到两种信息后,需要更新结点$ v_i$的向量表示
其中$w_k^{cos}$为参数,$d_k$为multi-perspective cosine distance,可以衡量两种信息的距离,$k \in \left \{ 1,2,3,…P\right\}$,$P$是视角的数量。
其中$\textbf{d}_i\triangleq[d_1,d_2,…,d_P]$,$FFN$两层。
句子的图级别表示:
总共经历了$L$次迭代(layer),得到$h_i^L$为结点$v_i$最终的向量表示($h_i^L$includes not only the information from its reachable nodes but also information of pairwise comparison with all nodes in another graph)
最终,两个句子的图级别表示分别为
3.3 分类器
得到$g^a,g^b$后,两句子的相似度可以用分类器衡量:
其中$P \in [0,1]$。
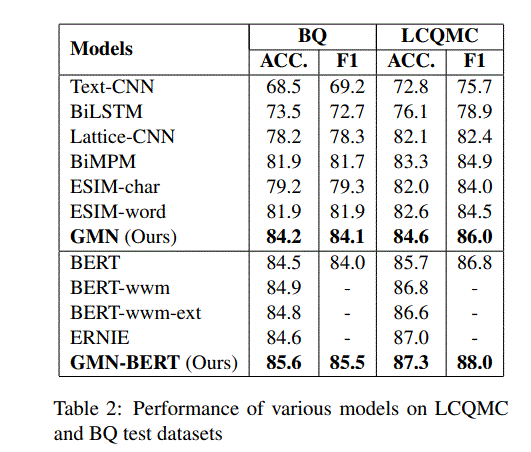
4.实验结果
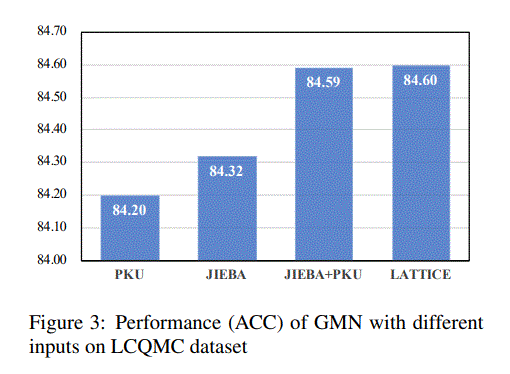
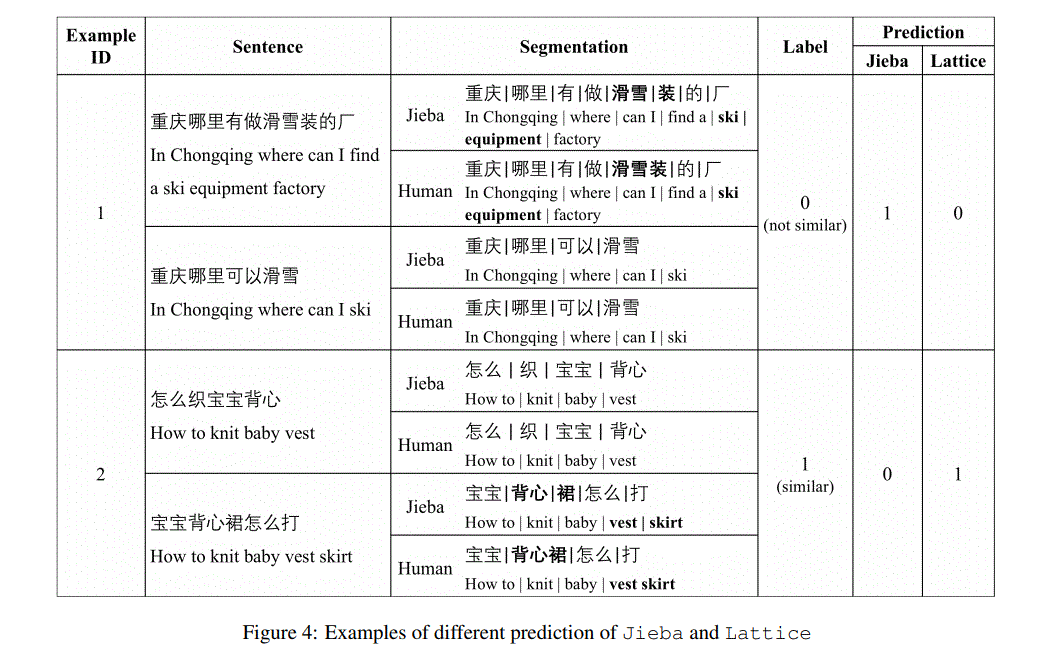
lattice和JIEBA+PKU的区别?
JIEBA+PKU is a small lattice graph generated by merging two word segmentation results
lattice:overall lattice,应该是全部的组合
两者效果差不多是因为Compared with the tiny graph, the overall lattice has more noisy nodes (i.e. invalid words in the corresponding sentence).