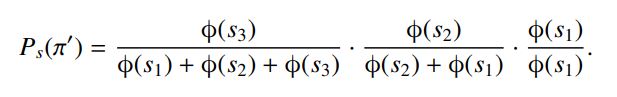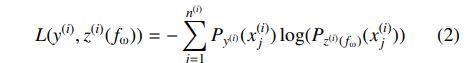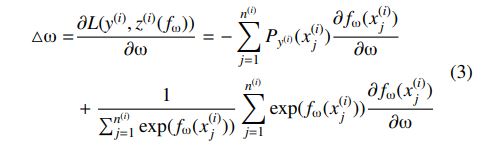1.RankNet
RankNet采用pairwise的方法进行模型训练。
loss推导
给定特定$query$下的两个文档$U_i$和$U_j$,其特征向量分别为$x_i$和$x_j$,经过RankNet进行前向计算得到对应的分数为$s_i=f(x_i)$和$s_j=f(x_j)$。用$U_i \rhd U_j$表示$U_i$比$U_j$排序更靠前。继而可以用下面的公式来表示$U_i$应该比$U_j$排序更靠前的概率:
定义$S_{ij} \in \{0,\pm1\}$为文档$i$和文档$j$被标记的标签之间的关联,即
定义$\overline{P}_{ij}=\frac{1}{2}(1+S_{ij})$表示$U_i$应该比$U_j$排序更靠前的已知概率,则可以用交叉熵定义优化目标的损失函数:
注意:$\sigma$是超参数
ranknet 加速
2.LambdaRank
ranket缺陷为只考虑pair的相对位置没有考虑二者在列表的整体位置
LambdaRank本质为ranknet基础上加入Listwise的指标,因此有人将LambdaRank归为listwise方法,也有归到pairwise方法
2.1 RankNet的局限
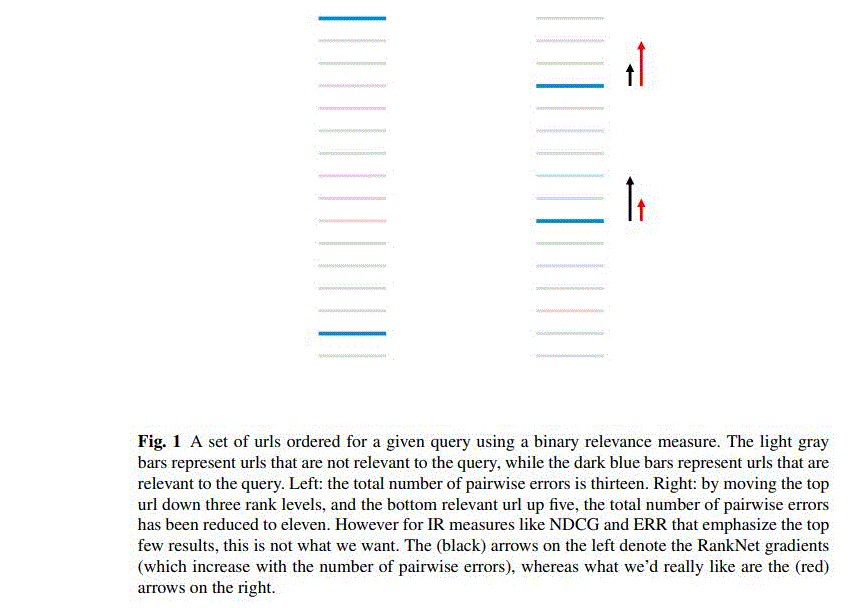
2.2 LambdaRank定义
上述公式可以进一步简化,即只考虑$S_{ij}=1$ (为什么可以?????)
那么Lambda,$\lambda$,就是梯度
为了加强排序中前后顺序的重要性,Lambda在原基础上引入评价指标Z(如NDCG),把交换两个文档的位置引起的评价指标的变化$|\Delta Z_{ij}|$作为其中一个因子:
反推出 LambdaRank 的损失函数:
3.LambdaMART
属于listwise,也有说pairwise。
LambdaMART=lambda($\lambda$)+mart(gbdt)
$\lambda$就是梯度,lambdarank就是一种loss,gbdt就是模型
lambdamart说白了就是利用gbdt计算lambdarank中s,或者说将lambdarank作为gbdt的loss
gbdt,lambdamart算法流程差异在于step1
GBDT:
- 初始化: $f_0(x) = \mathop{\arg\min}\limits_\gamma \sum\limits_{i=1}^N L(y_i, \gamma)$
- for m=1 to M:
(a). 计算负梯度: $\tilde{y}_i = -\frac{\partial L(y_i,f_{m-1}(x_i))}{\partial f_{m-1}(x_i)}, \qquad i = 1,2 \cdots N$
(b). $\left \{ R_{jm} \right\}_1^J = \mathop{\arg\min}\limits_{\left \{ R_{jm} \right\}_1^J}\sum\limits_{i=1}^N \left [\tilde{y}_i - h_m(x_i\,;\,\left \{R_{jm},b_{jm} \right\}_1^J) \right]^2$
(c). $\gamma_{jm} = \mathop{\arg\min}\limits_\gamma \sum\limits_{x_i \in R_{jm}}L(y_i,f_{m-1}(x_i)+\gamma)$
(d). $f_m(x) = f_{m-1}(x) + \sum\limits_{j=1}^J \gamma_{jm}I(x \in R_{jm})$
- 输出$f_M(x)$
LambdaMART:

参考
https://blog.csdn.net/laolu1573/article/details/87372514
https://liam.page/uploads/slides/lambdamart.pdf
https://blog.csdn.net/zpalyq110/article/details/79527653
https://zhuanlan.zhihu.com/p/86354141
https://www.cnblogs.com/genyuan/p/9788294.html
https://blog.csdn.net/huagong_adu/article/details/40710305
https://zhuanlan.zhihu.com/p/270608987
https://www.cnblogs.com/bentuwuying/p/6690836.html
paper原文: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/MSR-TR-2010-82.pdf
https://www.jianshu.com/p/a78b3f52c221
https://blog.csdn.net/zhoujialin/article/details/46697409
https://blog.csdn.net/w28971023/article/details/45849659
https://zhuanlan.zhihu.com/p/270608987