bert词向量服务,生成词向量并聚类可视化
细粒度NLP任务
AMBERT: A Pre-trained Language Model with Multi-Grained Tokenization (ByteDance AI Lab)
https://arxiv.org/pdf/2008.11869.pdf
参考
bertviz:attention可视化工具
看不同layer,不同head的attention
注意:
1 | from bertviz.neuron_view import show |
参考
prompt trick
目的
通过模板使得预测任务与预训练模型的训练任务相统一,拉近预训练任务目标与下游微调目标的差距
和finetune差异
finetune:PTM向下兼容specific task
prompt:specific task向上兼容PTM
应用场景
由于其当前预测任务与预训练模型的训练任务相统一,所以我们可以在训练数据较少,甚至没有的情况下去完成当前任务,总结一下,其比较适合的应用场景:
- zero-shot
- few-shot
- 冷启动
参考
ChineseBERT Chinese Pretraining Enhanced by Glyph and Pinyin Information
考虑字形和拼音的中文PTM
1 模型结构
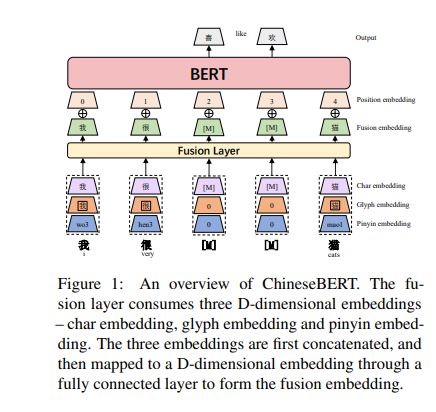
变动在bert的输入
原来Char embedding+Position embedding+segment embedding-> 现在 Fusion embedding+Position embedding (omit the segment embedding)
Char embedding +Glyph ( 字形 ) embedding +Pinyin (拼音)embedding -》Fusion embedding
2 预训练任务
Whole Word Masking (WWM) and Char Masking (CM)
3 使用
1 | >>> from datasets.bert_dataset import BertDataset |
参考
finetune
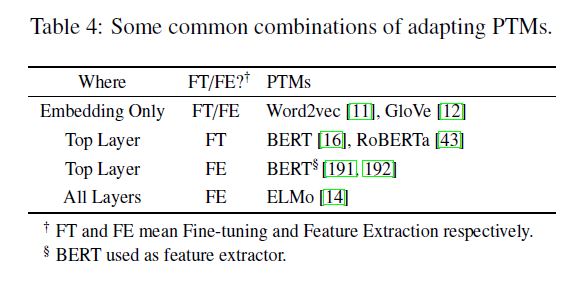
1 使用哪些层参与下游任务
使用哪些层参与下游任务
选择的层model1+下游任务model2
对于深度模型的不同层,捕获的知识是不同的,比如说词性标注,句法分析,长期依赖,语义角色,协同引用。对于RNN based的模型,研究表明多层的LSTM编码器的不同层对于不同任务的表现不一样。对于transformer based 的模型,基本的句法理解在网络的浅层出现,然而高级的语义理解在深层出现。
用$\textbf{H}^{l}(1<=l<=L)$表示PTM的第$l$层的representation,$g(\cdot)$为特定的任务模型。有以下几种方法选择representation:
a) Embedding Only
choose only the pre-trained static embeddings,即$g(\textbf{H}^{1})$
b) Top Layer
选择顶层的representation,然后接入特定的任务模型,即$g(\textbf{H}^{L})$
c) All Layers
输入全部层的representation,让模型自动选择最合适的层次,然后接入特定的任务模型,比如ELMo,式子如下
其中$\alpha$ is the softmax-normalized weight for layer $l$ and $\gamma$ is a scalar to scale the vectors output by pre-trained model
2 参数是否固定
总共有两种常用的模型迁移方式:feature extraction (where the pre-trained parameters are frozen), and fine-tuning (where the pre-trained parameters are unfrozen and fine-tuned).
3 Fine-Tuning Strategies
Two-stage fine-tuning
第一阶段为中间任务,第二阶段为目标任务
Multi-task fine-tuning
multi-task learning and pre-training are complementary technologies.
Fine-tuning with extra adaptation modules
The main drawback of fine-tuning is its parameter ineffciency: every downstream task has its own fine-tuned parameters. Therefore, a better solution is to inject some fine-tunable adaptation modules into PTMs while the original parameters are fixed.
Others
self-ensemble ,self-distillation,gradual unfreezing,sequential unfreezing
参考
text Span抽取
基于问题在段落中寻找答案
1 | 1 问题:苏轼是哪里人? |
bert中的SQuAD问答任务
标签
引入start 和 end 标签
结构
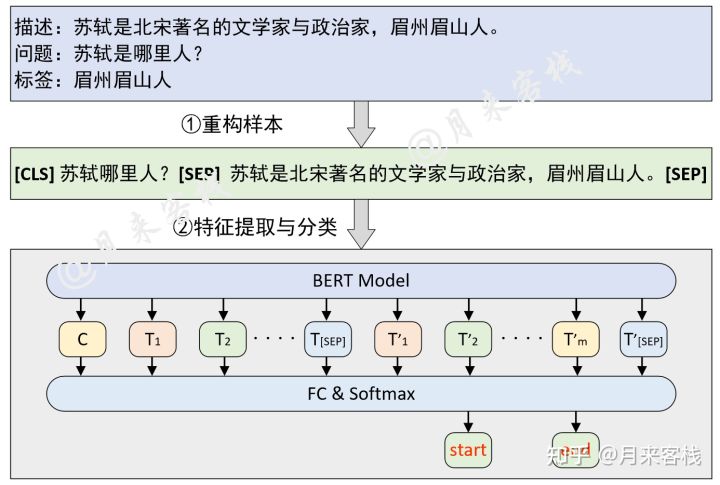
损失
1 | sequence_output = all_encoder_outputs[-1] #[src_len, batch_size, hidden_size] |
模型输出为: [src_len, batch_size,2]
两个(start 和 end )src_len分类的平均
预测
假设候选文本长度为n,输出n个2分类结果,选出最大的start概率和end概率最为start和end label
参考
https://zhuanlan.zhihu.com/p/77868938
序列标注
序列标注(Sequence Tagging)是NLP中最基础的任务,应用十分广泛,如分词、词性标注(POS tagging)、命名实体识别(Named Entity Recognition,NER)、关键词抽取、语义角色标注(Semantic Role Labeling)、槽位抽取(Slot Filling)等实质上都属于序列标注的范畴。
标注方式
https://zhuanlan.zhihu.com/p/147537898#