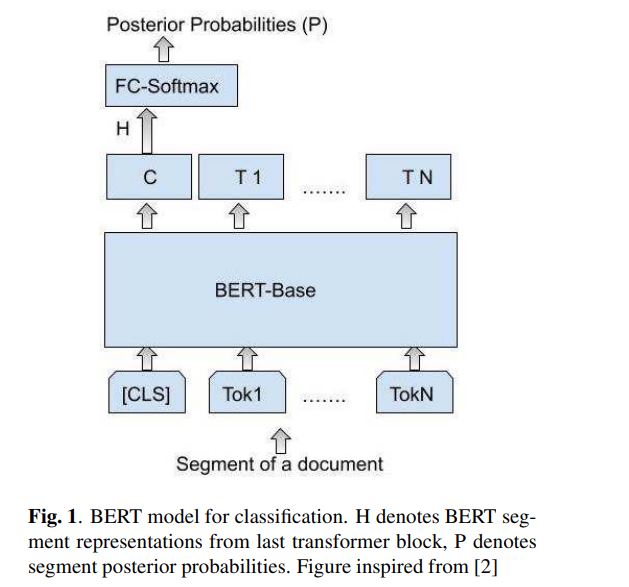
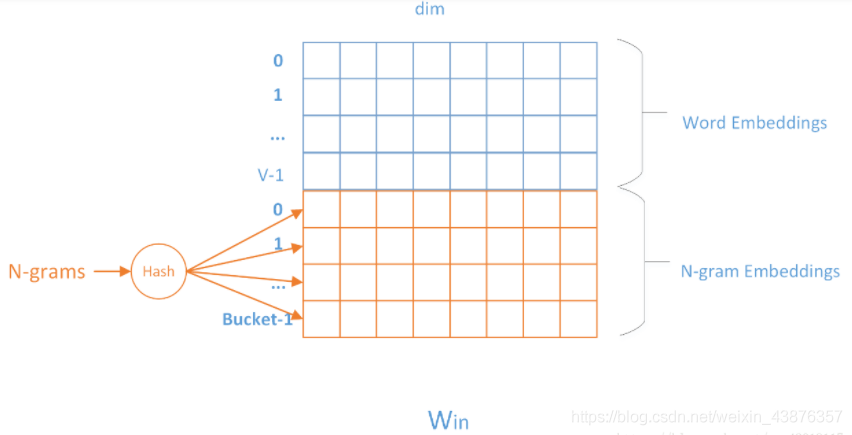
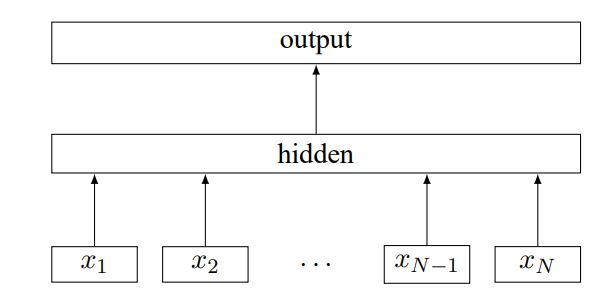
1.TextCNN (Convolutional Neural Networks for Sentence Classification)
原文 https://arxiv.org/abs/1408.5882
调参论文 https://arxiv.org/abs/1510.03820
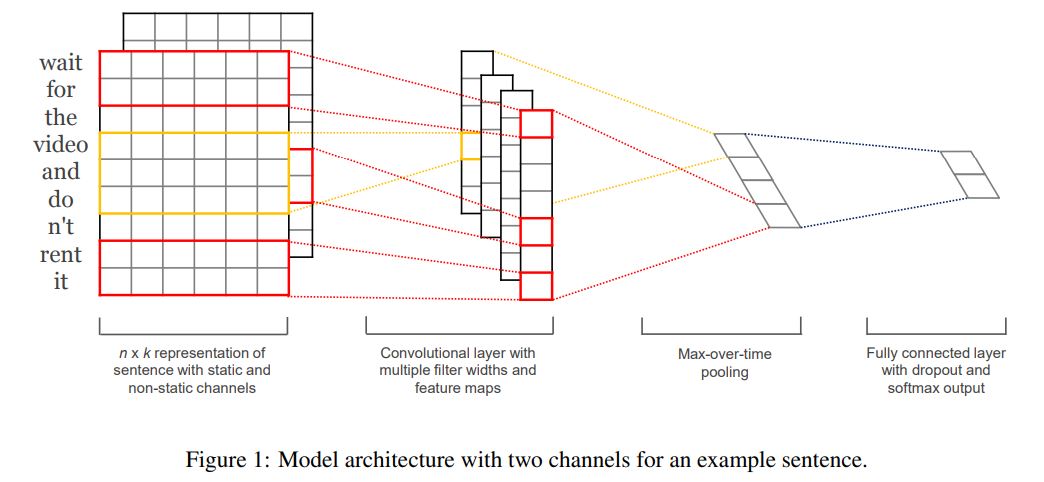
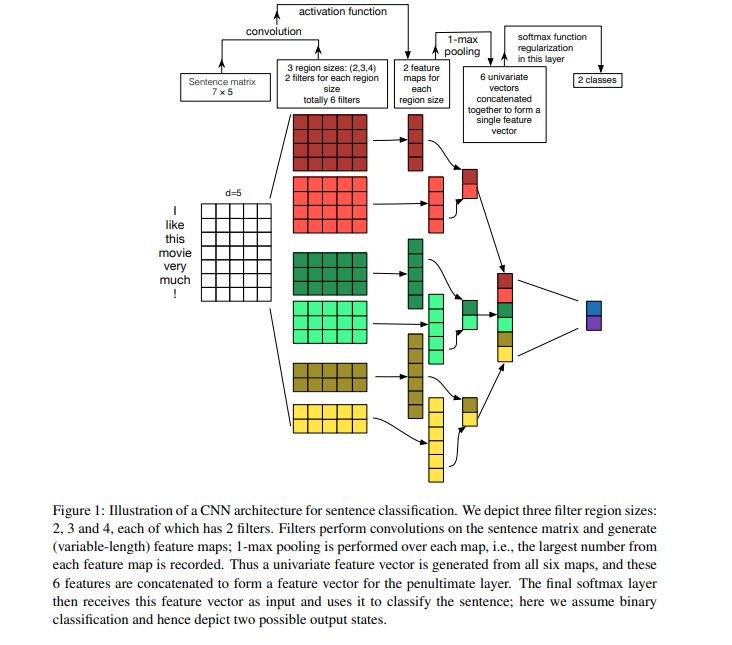
模型的整体结构如上所示。Feature Map是输入图像经过神经网络卷积产生的结果,filter是卷积核。
输入表示:
假设输入文本的长度为$n$,对于长度不够的需要做padding,任意一个单词可以用一个$k$维的向量表示,即$X_i \in \mathbb{R}^{k}$,那么一个句子可以表示为
其中$\oplus$是向量拼接操作,$X_{1:n} \in \mathbb{R}^{nk\times 1}$。
卷积:
对于某个滑窗$X_{i,i+h-1}=\{X_i,X_{i+1},…,X_{i+h-1}\}$经过某个卷积核$W_j$可得
其中$f=tanh(\cdot)$,$W_j\in \mathbb{R}^{ 1\times hk},c_{i,j} $是标量
假设卷积通道数为$m$,在NLP中,卷积滑动步伐$k=1$,那么经过卷积层后得到的完整的特征矩阵为
其中$C \in \mathbb{R}^{(n-h+1)\times m}$
maxpooling:
全连接:
然后将$\hat{C}$接个全连接,就可以做分类或者回归任务了。
2.TextRNN (Recurrent Neural Network for Text Classification with Multi-Task Learning)
原文 https://www.ijcai.org/Proceedings/16/Papers/408.pdf
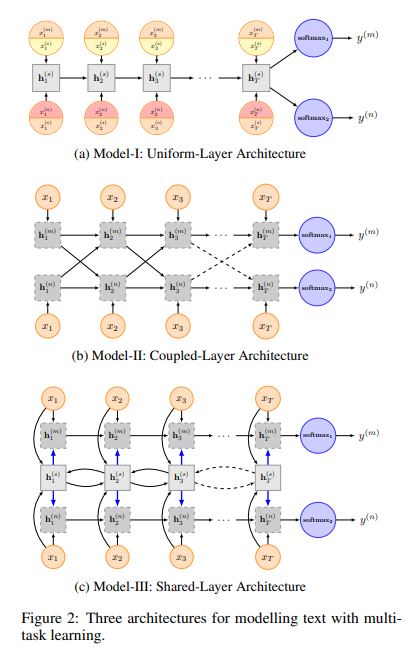
该文的场景为Recurrent Neural Network for Text Classification with Multi-Task Learning,就是论文的题目。文中给出了三种结构,如上图所示,图中的RNN单元为LSTM。
Model-I: Uniform-Layer Architecture
对于任务$m$,输入$\hat X_t$包含两个部分
其中$X_{t}^{(m)}$表示特定任务的词向量,$X_{t}^{(s)}$表示共享的词向量,$\oplus$表示向量拼接的操作。
Model-II: Coupled-Layer Architecture
Model-III: Shared-Layer Architecture
3.TextRCNN(Recurrent Convolutional Neural Networks for Text Classification)
原文 https://www.deeplearningitalia.com/wp-content/uploads/2018/03/Recurrent-Convolutional-Neural-Networks-for-Text-Classification.pdf
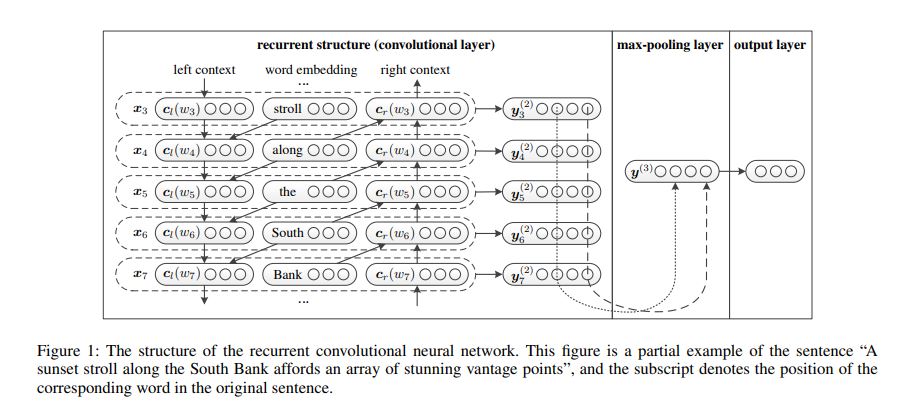
整体结构如上图所示,解释一下为啥叫RCNN,一般的 CNN 网络,都是卷积层 + 池化层,这里是将卷积层换成了双向 RNN,所以结果是,双向 RNN + 池化层。作者原话为:From the perspective of convolutional neural networks, the recurrent structure we previously mentioned is the convolutional layer.
词语表示
对于一个词语$w_i$,可以用一个三元组表示为
其中$e(w_i)$表示$w_i$的词向量,$c_l(w_i)$表示$w_i$句子左边的内容的向量表示,$c_r(w_i)$表示$w_i$句子右边的内容的向量表示,用式子表示如下
然后将$x_i$经过全连接得到$y_i^{(2)}$,$y_i^{(2)}$is a latent semantic vector
语句表示
获取众多的词语表示后,通过max-pooling得到句子表示
然后接全连接和softmax
参考
https://www.cnblogs.com/wangduo/p/6773601.html