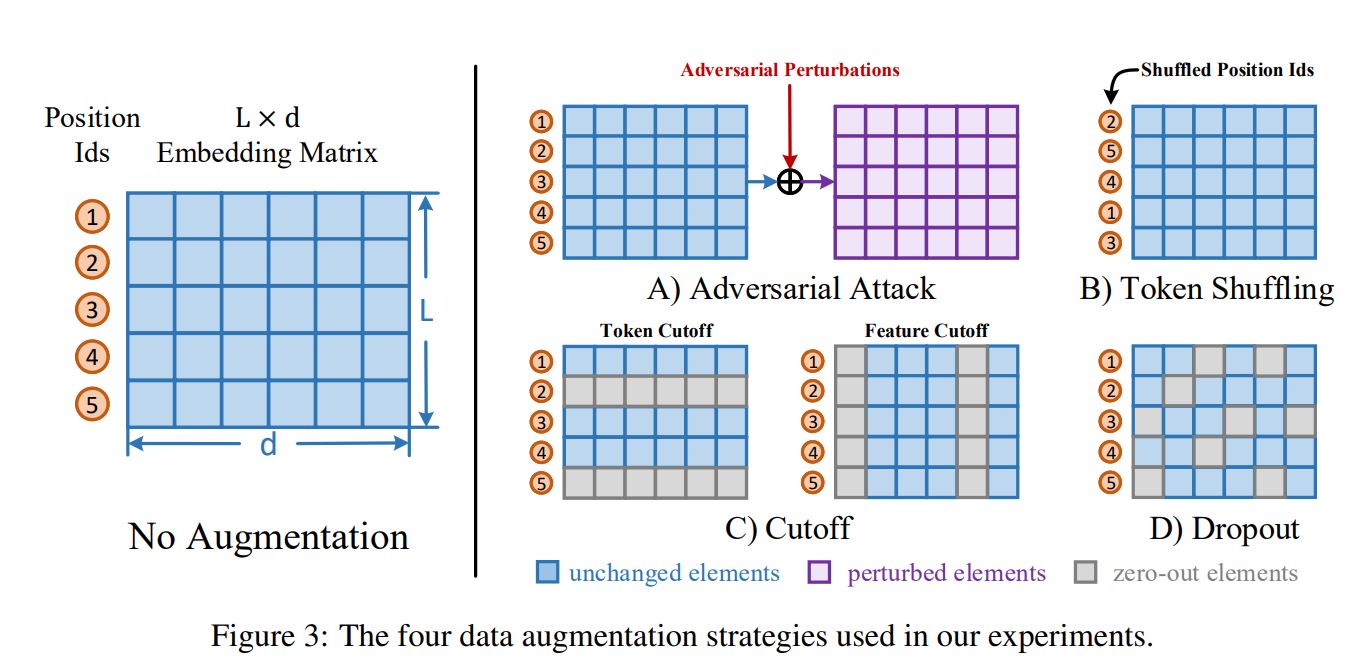
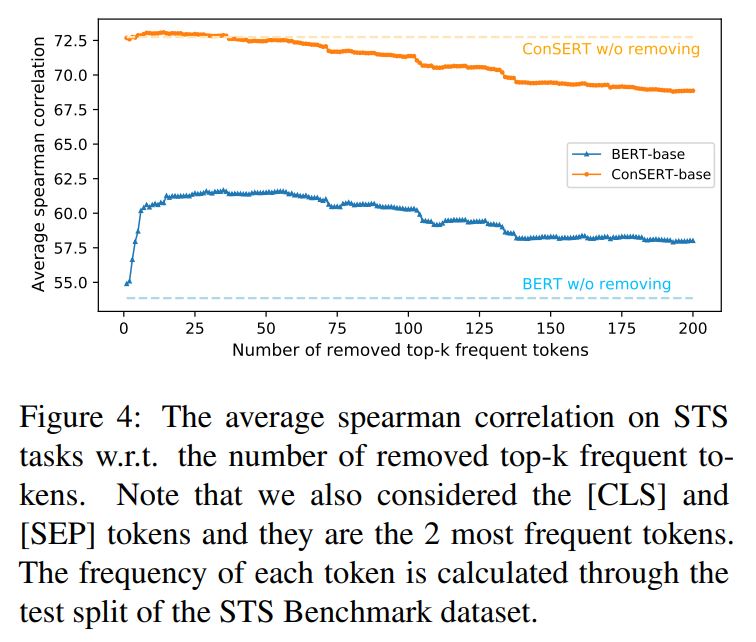
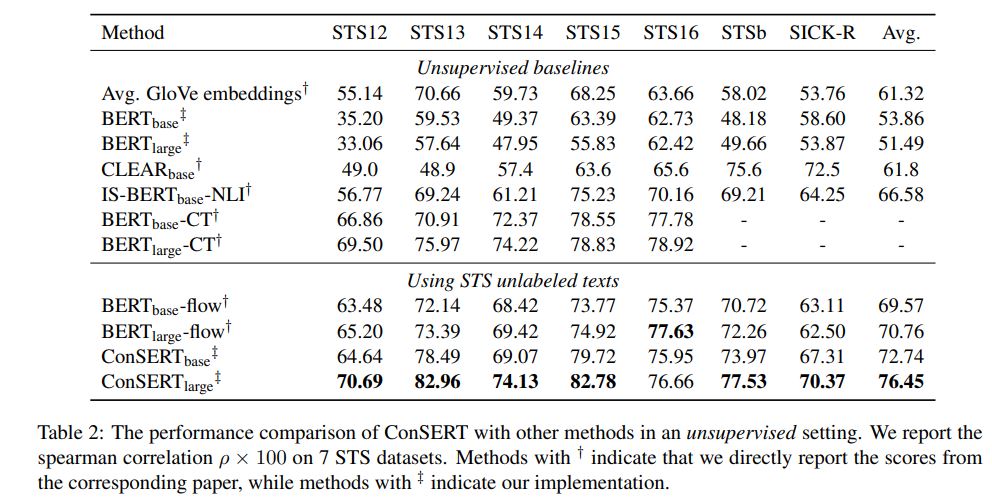
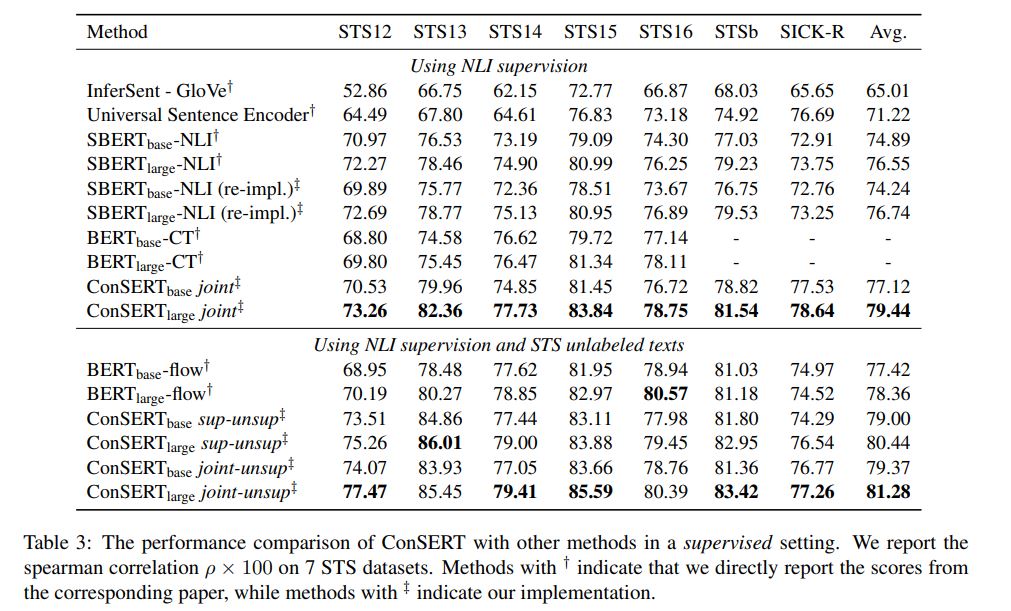
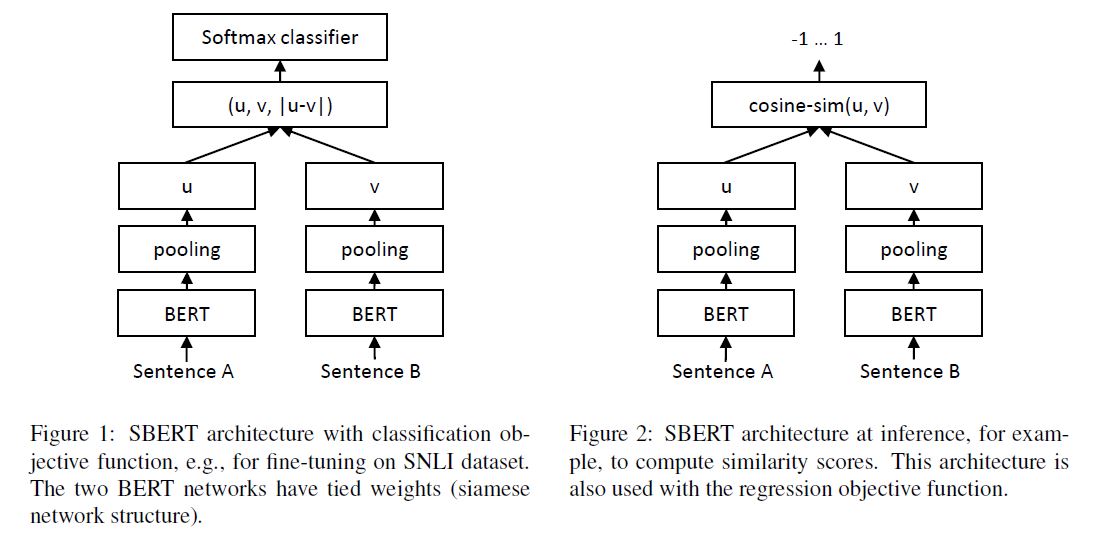
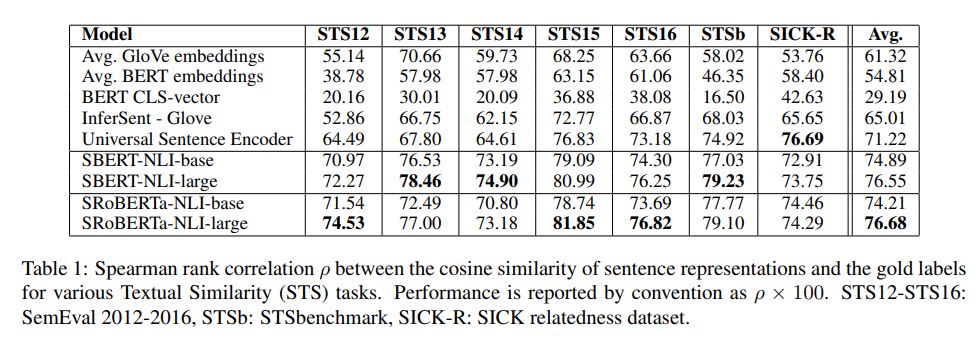
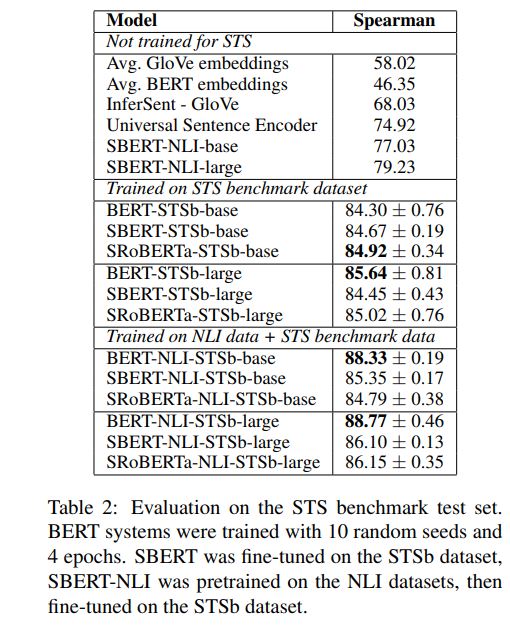
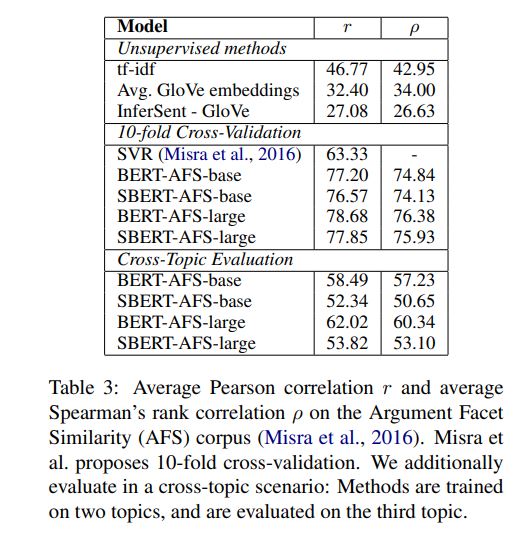
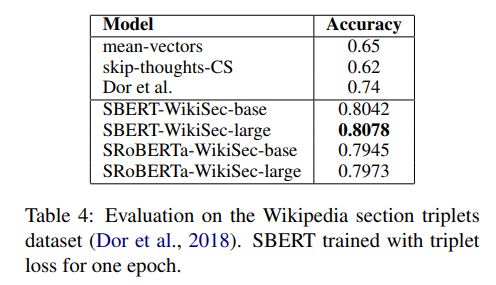
1
2
3
4
5
| array([[-1.3980628e+00, -4.6281612e-01, 5.8368486e-01, ..., 5.3952241e-01, 4.4697687e-01, 1.3505782e+00], [ 4.9143720e-01, -1.4818899e-01, -2.8366420e-01, ..., 1.1110669e+00, 2.1992767e-01, 7.0457202e-01], [-8.5650706e-01, 8.2832746e-02, -8.4218192e-01, ..., 2.1654253e+00, 6.4846051e-01, -5.7714492e-01], ..., [ 7.5072781e-03, -1.3543828e-02, 2.3101490e-02, ..., 4.2363801e-03, -5.6749382e-03, 6.3404259e-03], [-2.6244391e-04, -3.0459568e-02, 5.9752418e-03, ..., 1.7844304e-02, -4.7109672e-04, 7.7916058e-03], [ 7.2062697e-04, -6.5988898e-03, 1.1346856e-02, ..., -3.7340564e-03, -1.8825980e-02, 2.7245486e-03]], dtype=float32)
[',', '的', '。', '、', '0', '1', '在', '”', '2', '了', '“', '和', '是', '5', ...]
array([ 4.9143720e-01, -1.4818899e-01, -2.8366420e-01, -3.6405793e-01, 1.0851435e-01, 4.9507666e-02, -7.1219063e-01, -5.4614645e-01, -1.3581418e+00, 3.0274218e-01, 6.1700332e-01, 3.5553512e-01, 1.6602433e+00, 7.5298291e-01, -1.4151905e-01, -2.1077128e-01, -2.6325354e-01, 1.6108564e+00, -4.6750236e-01, -1.6261842e+00, 1.3063166e-01, 8.0702168e-01, 4.0011466e-01, 1.2198541e+00, -6.2879241e-01, ... 2.1928079e-01, 7.1725255e-01, -2.3430648e-01, -1.2066336e+00, 9.7590965e-01, -1.5906478e-01, -3.5802779e-01, -3.8005975e-01, 1.9056025e-01, 1.1110669e+00, 2.1992767e-01, 7.0457202e-01], dtype=float32)
|