细粒度NLP任务
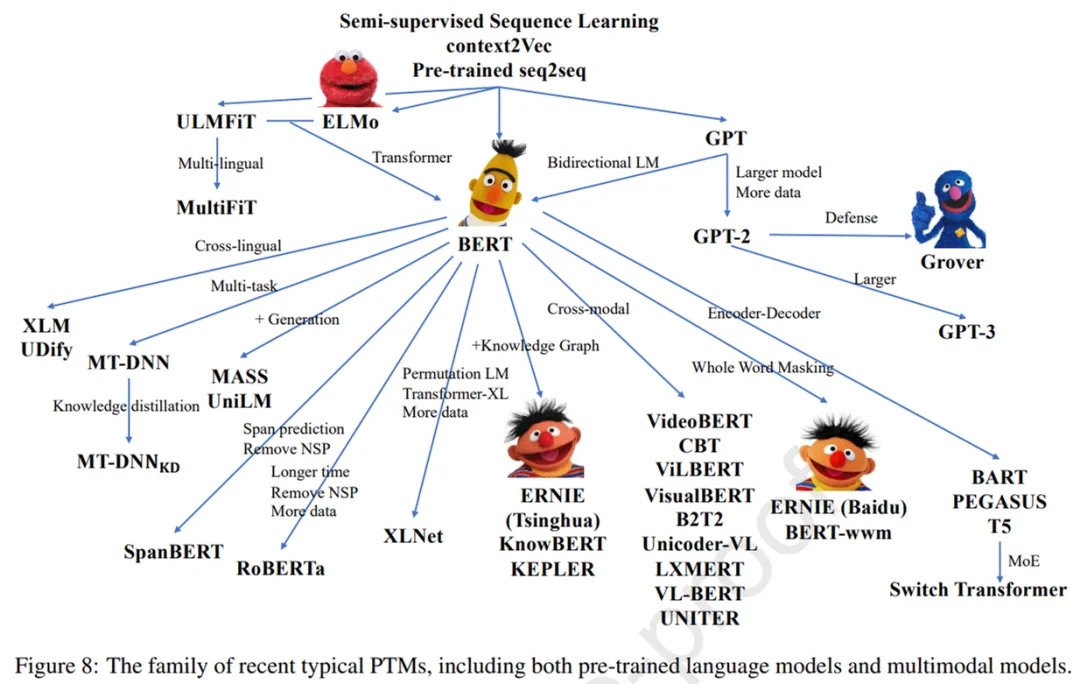
AMBERT: A Pre-trained Language Model with Multi-Grained Tokenization (ByteDance AI Lab)
https://arxiv.org/pdf/2008.11869.pdf
AMBERT: A Pre-trained Language Model with Multi-Grained Tokenization (ByteDance AI Lab)
https://arxiv.org/pdf/2008.11869.pdf
考虑字形和拼音的中文PTM
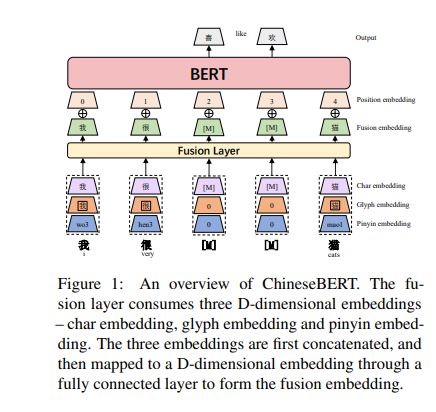
变动在bert的输入
原来Char embedding+Position embedding+segment embedding-> 现在 Fusion embedding+Position embedding (omit the segment embedding)
Char embedding +Glyph ( 字形 ) embedding +Pinyin (拼音)embedding -》Fusion embedding
Whole Word Masking (WWM) and Char Masking (CM)
1 | >>> from datasets.bert_dataset import BertDataset |
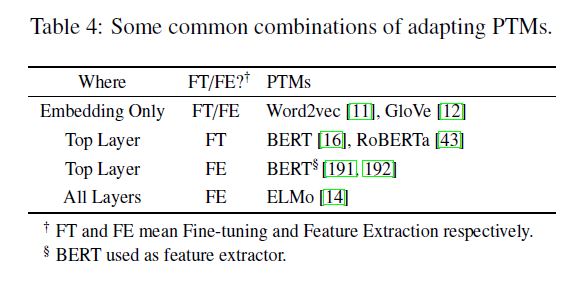
使用哪些层参与下游任务
选择的层model1+下游任务model2
对于深度模型的不同层,捕获的知识是不同的,比如说词性标注,句法分析,长期依赖,语义角色,协同引用。对于RNN based的模型,研究表明多层的LSTM编码器的不同层对于不同任务的表现不一样。对于transformer based 的模型,基本的句法理解在网络的浅层出现,然而高级的语义理解在深层出现。
用$\textbf{H}^{l}(1<=l<=L)$表示PTM的第$l$层的representation,$g(\cdot)$为特定的任务模型。有以下几种方法选择representation:
a) Embedding Only
choose only the pre-trained static embeddings,即$g(\textbf{H}^{1})$
b) Top Layer
选择顶层的representation,然后接入特定的任务模型,即$g(\textbf{H}^{L})$
c) All Layers
输入全部层的representation,让模型自动选择最合适的层次,然后接入特定的任务模型,比如ELMo,式子如下
其中$\alpha$ is the softmax-normalized weight for layer $l$ and $\gamma$ is a scalar to scale the vectors output by pre-trained model
总共有两种常用的模型迁移方式:feature extraction (where the pre-trained parameters are frozen), and fine-tuning (where the pre-trained parameters are unfrozen and fine-tuned).
Two-stage fine-tuning
第一阶段为中间任务,第二阶段为目标任务
Multi-task fine-tuning
multi-task learning and pre-training are complementary technologies.
Fine-tuning with extra adaptation modules
The main drawback of fine-tuning is its parameter ineffciency: every downstream task has its own fine-tuned parameters. Therefore, a better solution is to inject some fine-tunable adaptation modules into PTMs while the original parameters are fixed.
Others
self-ensemble ,self-distillation,gradual unfreezing,sequential unfreezing
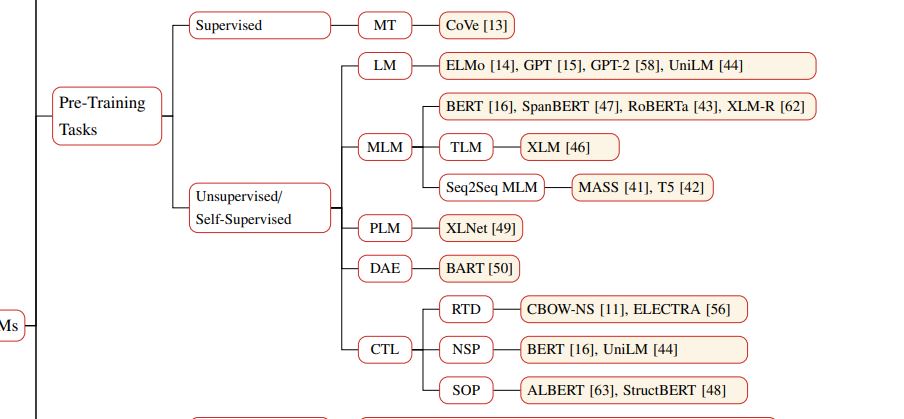
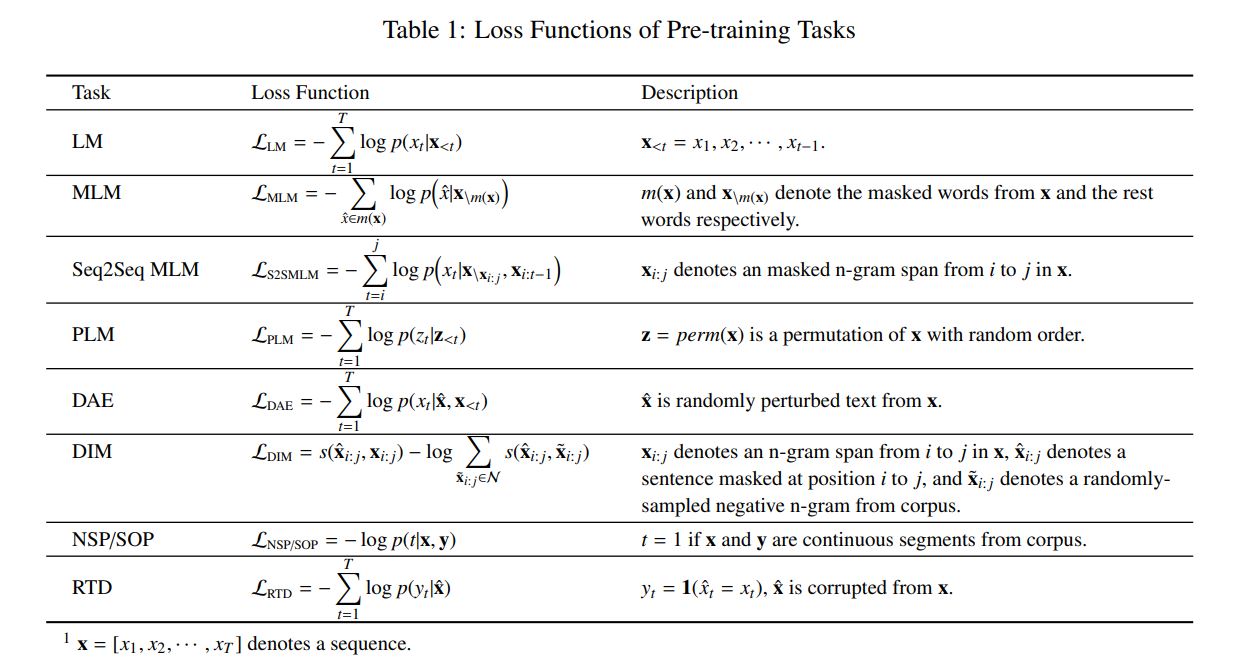
TLM : Translation Language Modeling
DAE: Denoising Autoencoder
CTL: Contrastive Learning
RTD: Replaced Token Detection
SOP:Sentence Order Prediction
DIM:Deep InfoMAx
BERT-wwm-ext
wwm:whole word mask
ext: we also use extended training data (mark with ext in the model name)
1 改变mask策略
Whole Word Masking,wwm
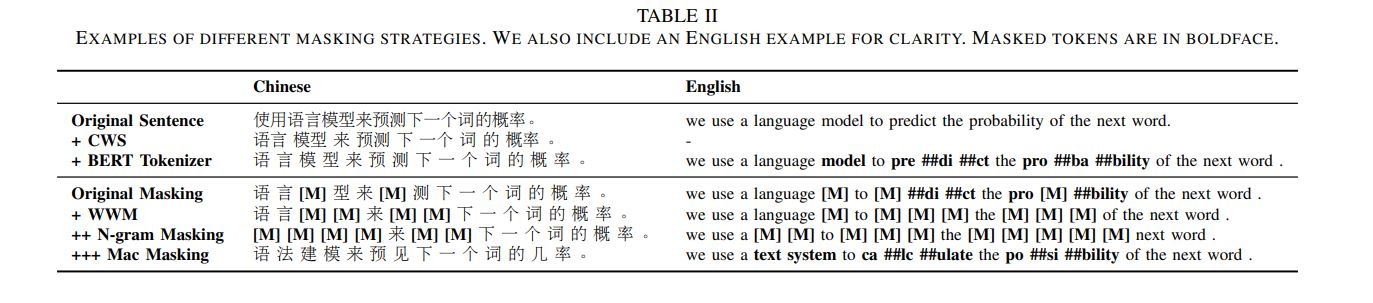
cws: Chinese Word Segmentation
对比四种mask策略
Pre-Training with Whole Word Masking for Chinese BERT
https://arxiv.org/abs/1906.08101v3
Revisiting Pre-trained Models for Chinese Natural Language Processing
There are three main contributions that ALBERT makes over the design choices of BERT:
1 Factorized embedding parameterization
原来embedding层是一个矩阵$M_{emb[V\times H]} $,现在变为两个$M_{emb1[V\times E]}$和$M_{emb2[E\times H]}$,参数量从VH变为VE+EH(This parameter reduction is significant when H >> E.)
2 Cross-layer parameter sharing
The default decision for ALBERT is to share all parameters across layers(attention,FFN))
3 Inter-sentence coherence loss
原来的NSP改为现在的sop,正例的构建和NSP是一样的,不过负例则是将两句话反过来。
https://zhuanlan.zhihu.com/p/88099919
https://blog.csdn.net/weixin_37947156/article/details/101529943
1 Is Word Segmentation Necessary for Deep Learning of Chinese Representations?
we find that charbased(字粒度) models consistently outperform wordbased (词粒度)models.
We show that it is because word-based models are more vulnerable to data sparsity and the presence of out-of-vocabulary (OOV) words, and thus more prone to overfitting.
2 腾讯中文词模型
词模型在公开数据集的表现逊于字模型
在结构上和原版BERT没有差异,主要的改动在于:
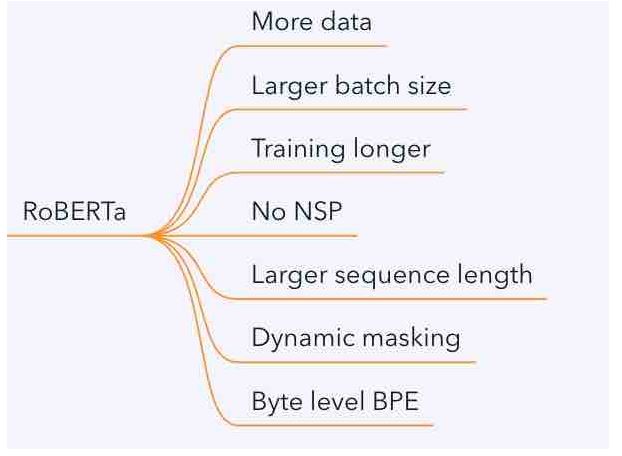
static masking: 原本的BERT采用的是static mask的方式,就是在create pretraining data中,先对数据进行提前的mask
dynamic masking: 每一次将训练example喂给模型的时候,才进行随机mask。
结果对比:
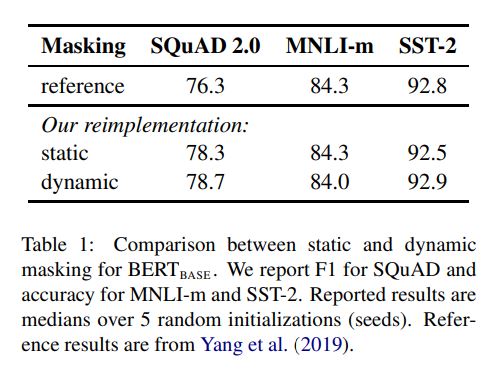
结论:动态占优
做了结果对比试验,结果如下:
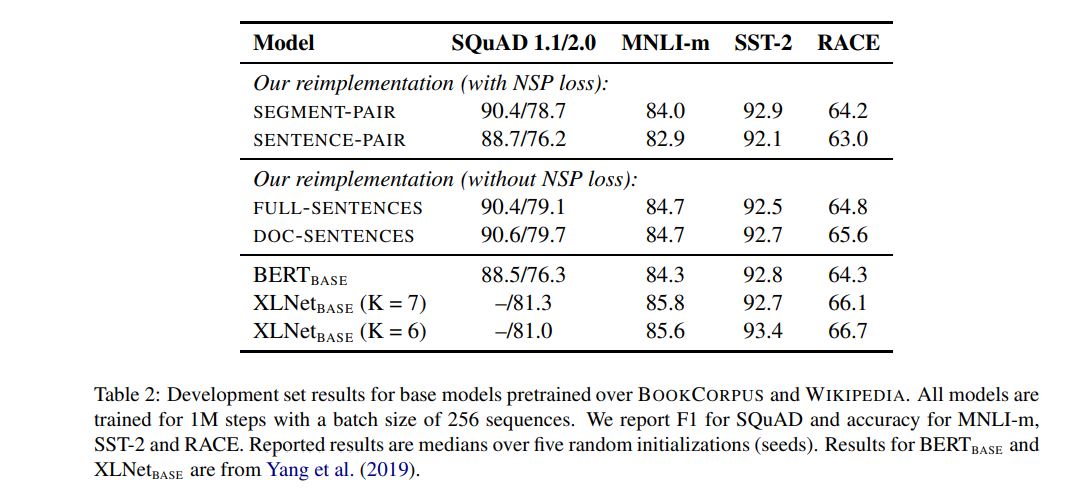
结论:
Model Input Format:
1.find that using individual sentences hurts performance on downstream tasks
Next Sentence Prediction:
1.removing the NSP loss matches or slightly improves downstream task performance
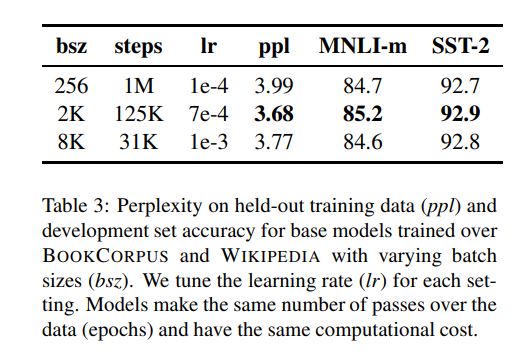
采用BBPE而不是wordpiece
1 roberta tokenizer 没有token_type_ids?
roberta 取消了NSP,所以不需要segment embedding 也就不需要token_type_ids,但是使用的时候发现中文是有token_type_ids的,英文没有token_type_ids的。没有token_type_ids,两句话怎么区别,分隔符sep还是有的,只是没有segment embedding
2 使用避坑
https://blog.csdn.net/zwqjoy/article/details/107533184
https://hub.fastgit.org/ymcui/Chinese-BERT-wwm
https://zhuanlan.zhihu.com/p/103205929
https://zhuanlan.zhihu.com/p/143064748