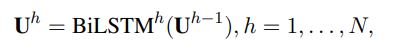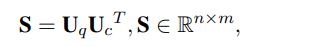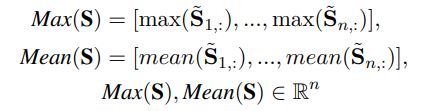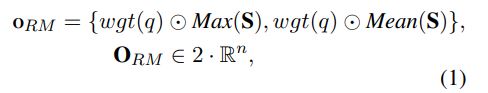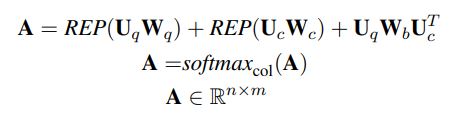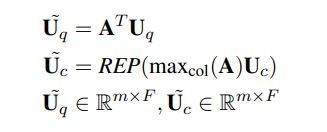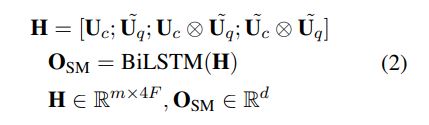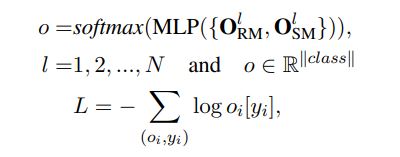Prompt-learning小帮手-openprompt
清华NLP实验室推出OpenPrompt开源工具包
1 结构
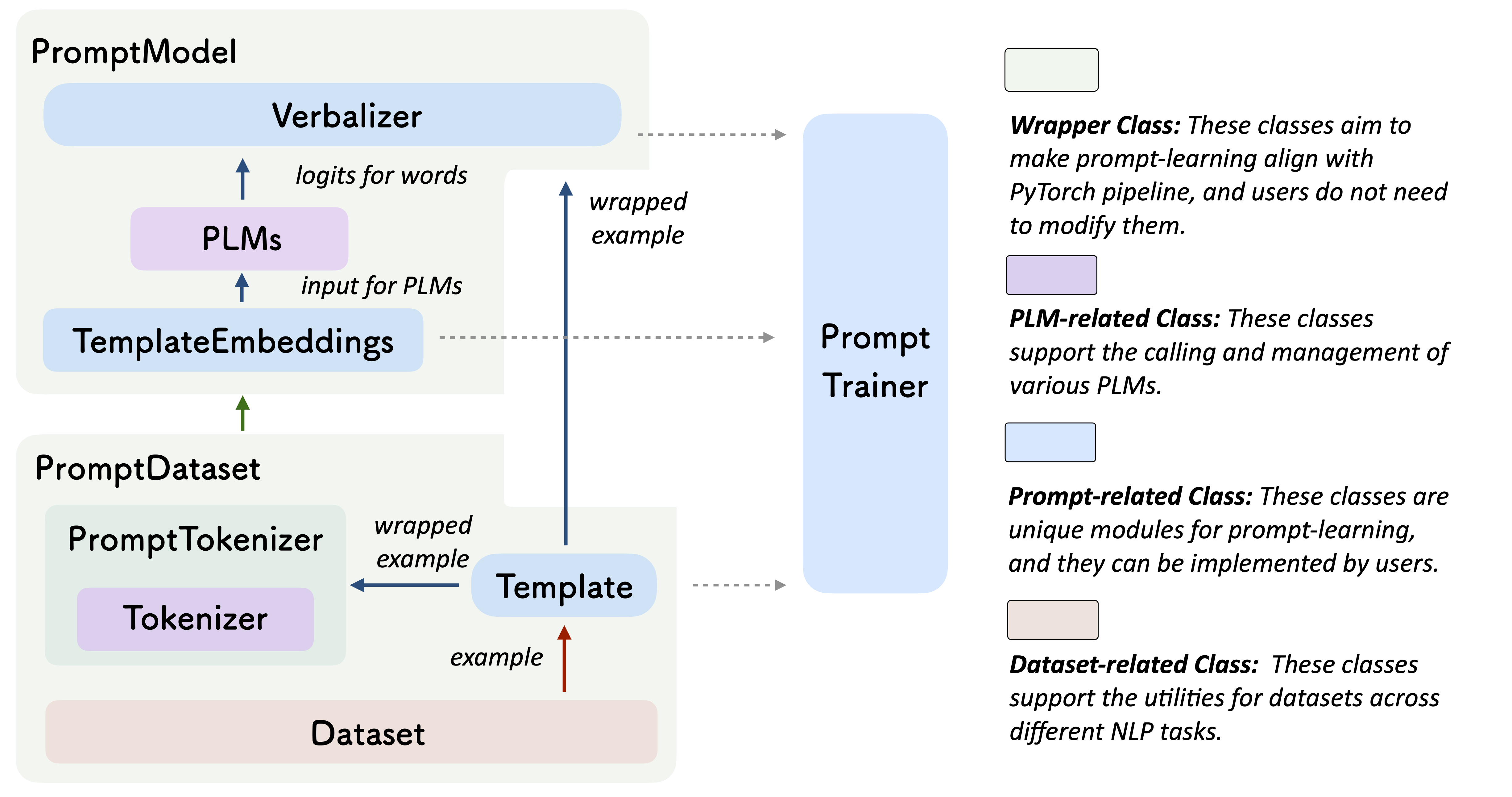
2 教程
可以参考官方https://hub.fastgit.xyz/thunlp/OpenPrompt
有详细的步骤和case
参考
https://hub.fastgit.xyz/thunlp/OpenPrompt
清华NLP实验室推出OpenPrompt开源工具包
可以参考官方https://hub.fastgit.xyz/thunlp/OpenPrompt
有详细的步骤和case
https://hub.fastgit.xyz/thunlp/OpenPrompt
https://zhuanlan.zhihu.com/p/444346578
sts任务,数据分为sts无标签数据,sts有标签数据,nli有标签
无监督,有监督loss一样,文中有3种loss,区别在于数据集
无监督:nli有标签;有监督:sts有标签数据
sts任务,数据分为sts无标签数据,sts有标签数据
无监督,有监督区别在于:样本构造不同
无监督样本正负来源于sts无标签数据数据增强,有监督样本正负来源于sts有标签数据
sts任务,数据分为sts无标签数据,sts有标签数据,还有nli数据集(有标签)
相同
和simcse相同之处:都是在finetune引入对比
不同
1 无监督
和simces loss一样为NT-Xent,不同在于sts无标签数据数据增强方式不同
2 有监督
区别在于loss和数据源
simcse loss为NT-Xent,数据源为sts有标签数据
consert loss为 NT-Xent + 别的有监督loss(比如cross entropy),数据源为sts无标签数据和nli数据集(有标签),+表示融合 ,论文有3种融合方式
特点:非预训练,参数量少
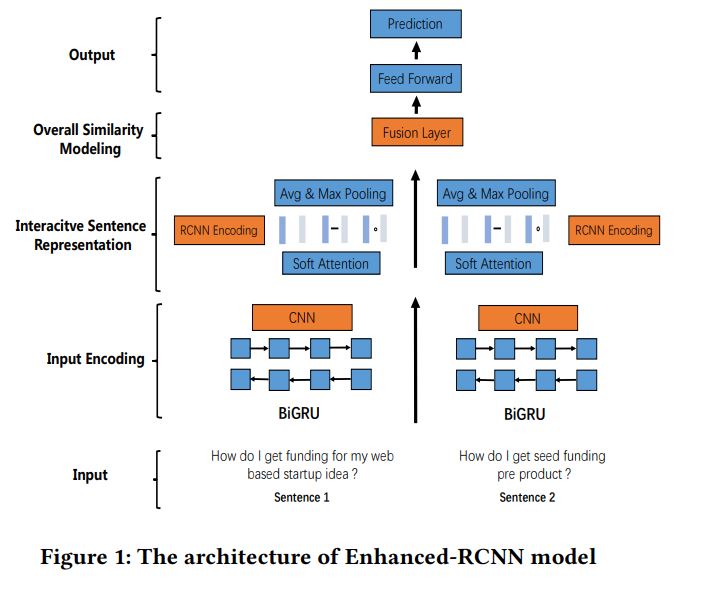
得到两个encoding,RNN Encoding,RCNN Encoding
1 BiGRU
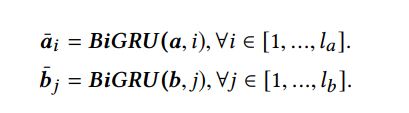
$\textbf{a}=\{a_1,a_2,…,a_{l_a}\},\textbf{a}$ 是句子,$l_a$ 是句子1的长度
得到RNN Encoding,$\overline{\textbf{p}}_i$统一表示$\overline{\textbf{a}}_i,\overline{\textbf{b}}_i$
2 CNN
在 BiGRU 编码的基础上,使用 CNN 来进行二次编码
结构如下,“newtork in network”,k 是卷积核的kernel size,比如k=1,卷积核为$1 \times 1$
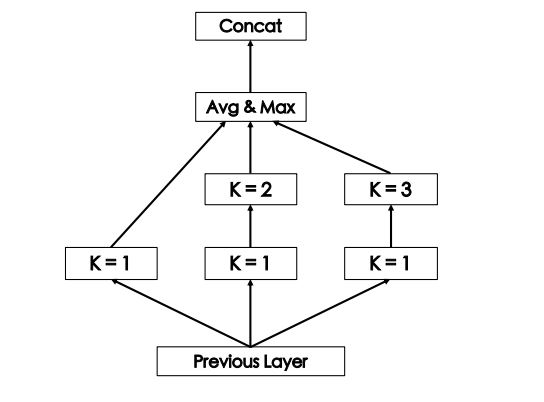
对于每个 CNN 单元,具体的计算过程如下:
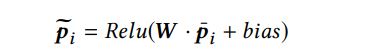
得到 RCNN Encoding $\widetilde{\textbf{p}}_i$
1 Soft-attention Alignment
attention:
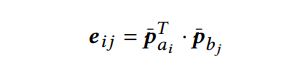
加了attention的rnn encoding:
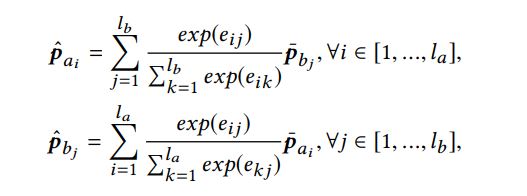
2 Interaction Modeling
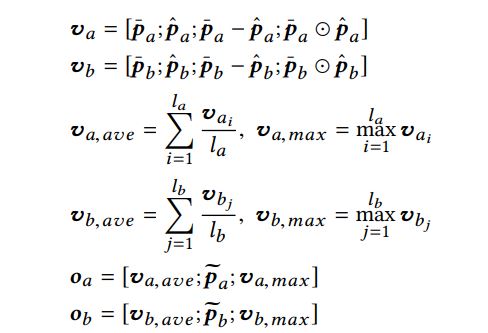
$\overline{\textbf{p}}$是rnn encoding
$\hat{}$是加了attention的rnn encoding
$\widetilde{}$是rcnn encoding
最终得到Interactive Sentence Representation为$\textbf{o}_a,\textbf{o}_b$
1 Fusion Layer
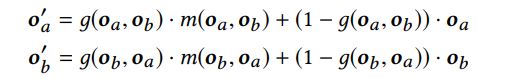
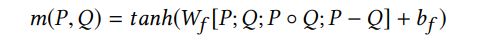
g是门控函数
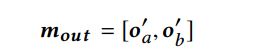
2 Label Prediction
全连接层
交叉熵
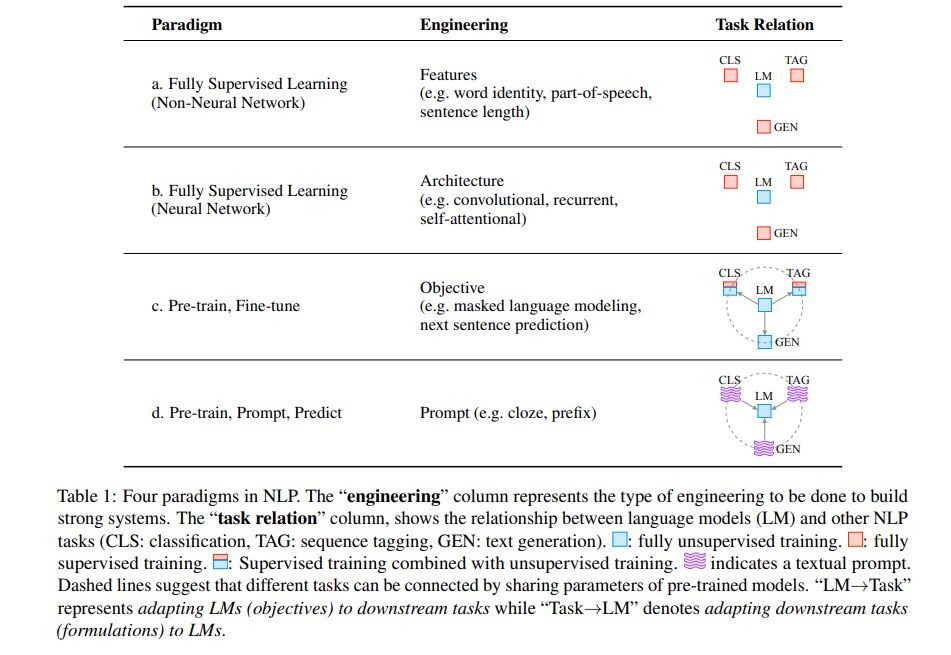

prompt感觉是一种特殊的finetune方式,还是先pre-train然后prompt tuning
目的:prompt narrowing the gap between pre-training and fine-tuning
3步

$x^{‘}=f_{prompt}(x)$ x是input text
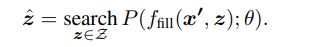
f:fills in the location [Z] in prompt $x^{‘}$ with the potential answer z
Z:a set of permissible values for z
因为上面的 $\hat{z}$ 还不是 $\hat{y}$,比如情感分析,“excellent”, “fabulous”, “wonderful” -》positive
go from the highest-scoring answer $\hat{z}$ to the highest-scoring output $\hat{y}$
原来
“ I love this movie.” -》 positive
现在
1 $x=$ “ I love this movie.” -》模板为: “ [x] Overall, it was a [z] movie.” -》$x^{‘}$为”I love this movie. Overall ,it was a [z] movie.”
2 下一步会进行答案搜索,顾名思义就是LM寻找填在[z] 处可以使得分数最高的文本 $\hat{z}$(比如”excellent”, “great”, “wonderful” )
3 最后是答案映射。有时LM填充的文本并非任务需要的最终形式(最终为positive,上述为”excellent”, “great”, “wonderful”),因此要将此文本映射到最终的输出$\hat{y}$

1 one must first consider the prompt shape,
2 then decide whether to take a manual or automated approach to create prompts of the desired shape
Prompt的形状主要指的是[X]和[Z]的位置和数量。
如果在句中,一般称这种prompt为cloze prompt;如果在句末,一般称这种prompt为prefix prompt。
在实际应用过程中选择哪一种主要取决于任务的形式和模型的类别。cloze prompts和Masked Language Model的训练方式非常类似,因此对于使用MLM的任务来说cloze prompts更加合适;对于生成任务来说,或者使用自回归LM解决的任务,prefix prompts就会更加合适;Full text reconstruction models较为通用,因此两种prompt均适用。另外,对于文本对的分类,prompt模板通常要给输入预留两个空,[x1]和[x2]。
the prompt 作用在文本上
D1: Prompt Mining
D2: Prompt Paraphrasing
D3: Gradient-based Search
D4: Prompt Generation
D5: Prompt Scoring
the prompt 直接作用到模型的embedding空间
C1: Prefix Tuning
C2: Tuning Initialized with Discrete Prompts
C3: Hard-Soft Prompt Hybrid Tuning
two dimensions that must be considered when performing answer
engineering:1 deciding the answer shape and 2 choosing an answer design method.
和Prompt Shape啥区别???
之前在讨论single prompt,现在介绍multiple prompts

1 Training Settings
full-data
few-shot /zero-shot
2 Parameter Update Methods
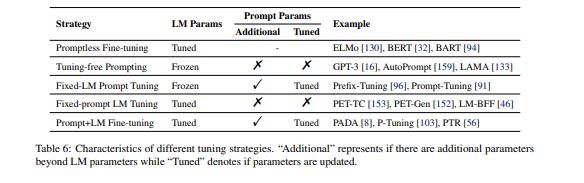
https://arxiv.org/abs/2107.13586
刘鹏飞博士 https://zhuanlan.zhihu.com/p/395115779
https://zhuanlan.zhihu.com/p/399295895
paper: https://arxiv.org/abs/1904.05046
git: https://github.com/tata1661/FSL-Mate/tree/master/FewShotPapers#Applications
原文按应用对FSL做了总结,与NLP相关的有:
NLP小帮手,huggingface的transformer
git: https://github.com/huggingface/transformers
paper: https://arxiv.org/abs/1910.03771v5
整体结构
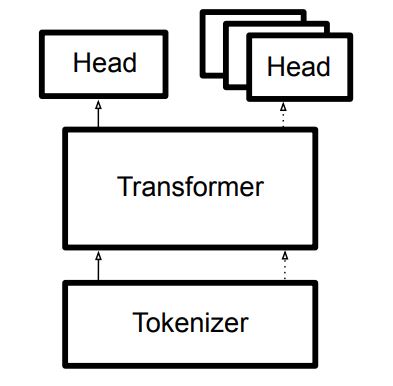
简单教程:
https://blog.csdn.net/weixin_44614687/article/details/106800244
底层为load_state_dict
1 | Some weights of the model checkpoint at ../../../../test/data/chinese-roberta-wwm-ext were not used when initializing listnet_bert: ['cls.predictions.transform.dense.weight', 'cls.seq_relationship.bias', 'cls.predictions.transform.dense.bias', 'cls.predictions.decoder.weight', 'cls.predictions.transform.LayerNorm.bias', 'cls.seq_relationship.weight', 'cls.predictions.bias', 'cls.predictions.transform.LayerNorm.weight'] |
BertModel -> our model
1 加载transformers中的模型
1 | from transformers import BertPreTrainedModel, BertModel,AutoTokenizer,AutoConfig |
2 基于1中的模型搭建自己的结构
https://arxiv.org/abs/1901.02860
Transformers have a potential of learning longer-term dependency, but are limited by a fixed-length context in the setting of language modeling ( memory and computation受限,长度不可能很大 ). propose a novel neural architecture Transformer-XL that enables learning dependency beyond a fixed length without disrupting temporal coherence.

问题:In order to apply Transformer or self-attention to language modeling, the central problem is how to train a Transformer to effectively encode an arbitrarily long context into a fixed size representation.通常做法为vanilla model。 vanilla model就是说把长文本分隔成固定长度的seg来处理,如上图。
During training,There are two critical limitations of using a fixed length context. First, the largest possible dependency length is upper bounded by the segment length. Second. simply chunking a sequence into fixed-length segments will lead to the context fragmentation problem
During evaluation, As shown in Fig. 1b, this procedure ensures that each prediction utilizes the longest possible context exposed during training, and also relieves context fragmentation issue encountered in training. However, this evaluation procedure is extremely expensive.
introduce a recurrence mechanism to the Transformer architecture.
定义变量

转换过程
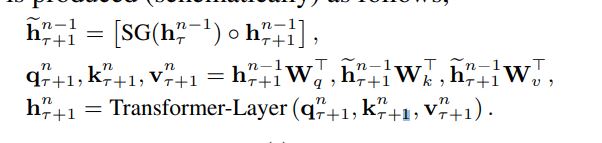
SG() stands for stop-gradient,$\circ$ 表示矩阵拼接
具体过程如下图
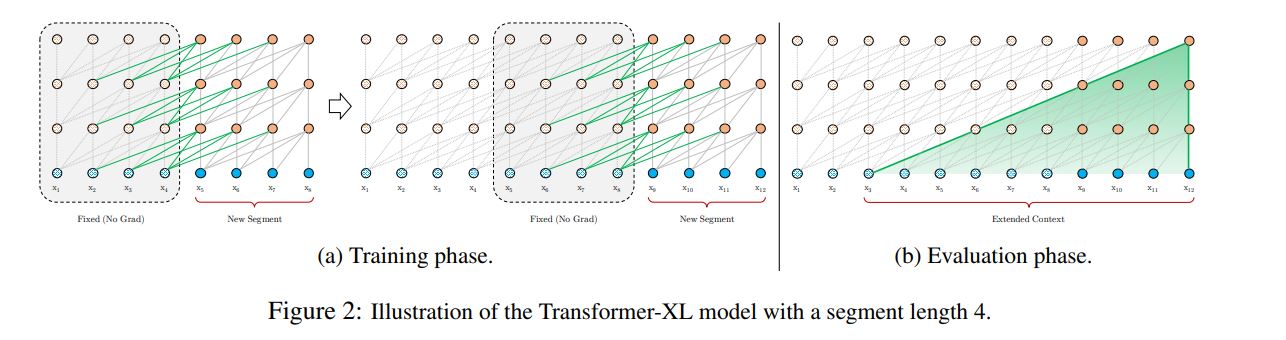
During training, the hidden state sequence computed for the previous segment is fixed and cached to be reused as an extended context when the model processes the next new segment, as shown in Fig. 2a.
during evaluation, the representations from the previous segments can be reused instead of being computed from scratch as in the case of the vanilla model.
how can we keep the positional information coherent when we reuse the states? 如果保留原来的位置编码形式,可以得到如下
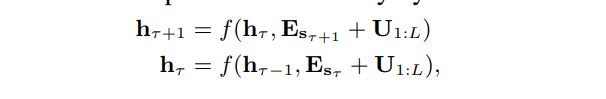
这种方式存在问题:

为了解决这个问题提出了relative positional information。
standard Transformer
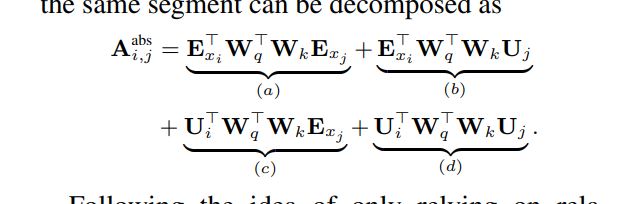
we propose
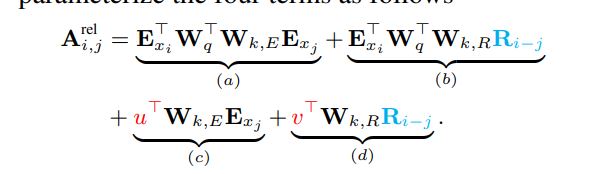

https://cs.uwaterloo.ca/~jimmylin/publications/Rao_etal_EMNLP2019.pdf
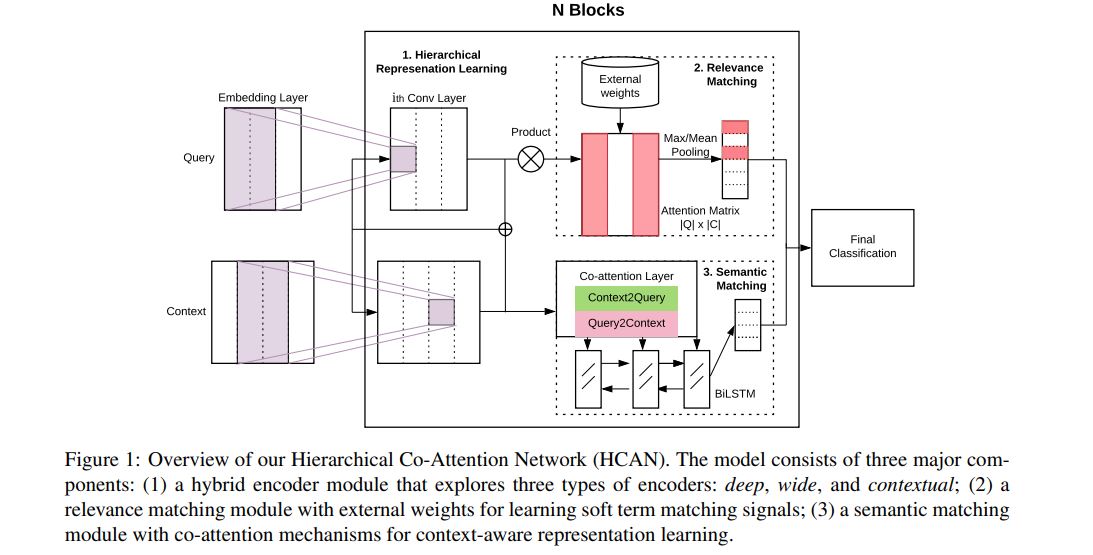
three major components: (1) a hybrid encoder (2) a relevance matching module (3) a semantic matching module
hybrid encoder module that explores three types of encoders: deep, wide, and contextual
query and context words :$\{w_1^q,w_2^q,…,w_n^q\},\{w_1^c,w_2^c,…,w_m^c\}$, embedding representations $\textbf{Q}\in \mathbb{R}^{n\times L},\textbf{C}\in \mathbb{R}^{m\times L}$
Deep Encoder
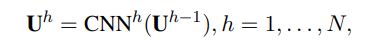
$\textbf{U}$表示$\textbf{Q},\textbf{C}$
Wide Encoder
Unlike the deep encoder that stacks multiple convolutional layers hierarchically, the wide encoder organizes convolutional layers in parallel, with each convolutional layer having a different window size k
Contextual Encoder