transformer综述
Transformer-XL
https://arxiv.org/abs/1901.02860v3
RoFormer
https://arxiv.org/pdf/2104.09864.pdf
google2020出品的transformer的综述
Transformer-XL
https://arxiv.org/abs/1901.02860v3
RoFormer
https://arxiv.org/pdf/2104.09864.pdf
google2020出品的transformer的综述
https://arxiv.org/pdf/2104.08821.pdf
1 target
对于$D=\{(x_i,x_i^{+})\}_{i=1}^{m}$,where $x_i$ and $x_i^{+}$ are semantically related. xi,xj+ are not semantically related
x->h
Contrastive learning aims to learn effective representation by pulling semantically close neighbors together and pushing apart non-neighbors
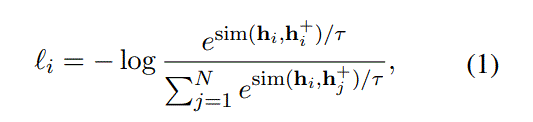
N is mini-batch size,分子是正样本,分母为负样本(有一个正样本,感觉是可以忽略)
分母会包含分子的项吗?从代码看,会的
loss
https://www.jianshu.com/p/d73e499ec859
1 | def loss(self,y_pred,y_true,lamda=0.05): |
2 representations评价指标
Alignment: calculates expected distance between embeddings of the paired instances(paired instances就是正例)
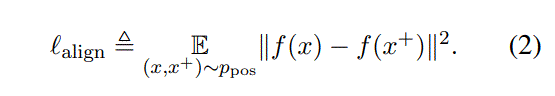
uniformity: measures how well the embeddings are uniformly distributed
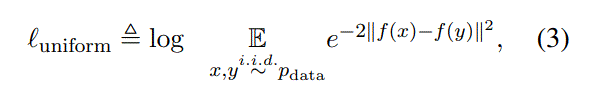
$x_i->h_i^{z_i},x_i->h_i^{z_i^{‘}}$
z is a random mask for dropout,loss为
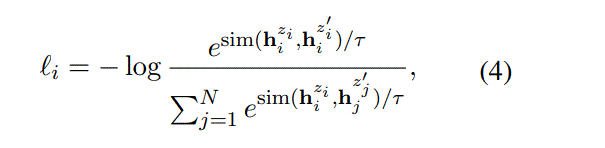
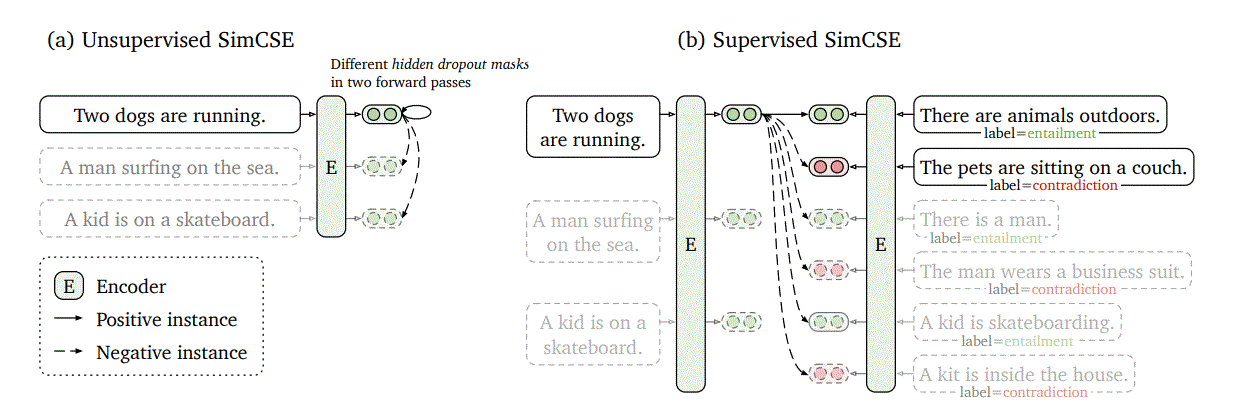
引入非目标任务的有标签数据集,比如NLI任务,$(x_i,x_i^{+},x_i^{-})$,where $x_i$ is the premise, $x_i^{+}$and $x_i^{-}$are entailment and contradiction hypotheses.
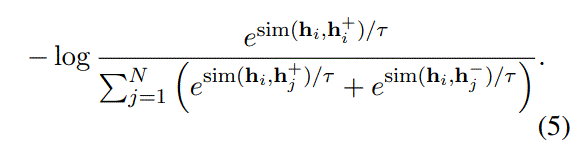
$(h_i,h_j^{+})$为normal negatives,$(h_i,h_j^{-})$为hard negatives
采用分类任务的评价指标,比如accuracy,recall,F1等
重点说下一些paper的sts(Semantic Textual Similarity)任务,为什么采用相关系数(Pearson correlation或者spearman correlation)来衡量,比如 S-bert https://arxiv.org/abs/1908.10084 ,consert https://arxiv.org/abs/2105.11741 。 这是因为S-bert和consert 都是文本表示的方法,最后计算文本相似度是利用余弦相似度计算的,相似度的值域为0-1,但是sts数据集的相似度值域为0-5。值域范围不同,不能直接进行比较,用相关系数来间接评价。
https://zhuanlan.zhihu.com/p/144182853
https://arxiv.org/pdf/2006.14799.pdf
文本改写(算是特殊的生成)
https://aclanthology.org/2020.findings-emnlp.111.pdf
https://arxiv.org/pdf/1909.01187.pdf
Exact score: percentage of exactly correctly predicted fusions
SARI: the average F1 scores of the added, kept, and deleted n-grams
https://arxiv.org/pdf/1908.10084.pdf
SentEval (Conneau and Kiela, 2018) is a popular toolkit to evaluate the quality of sentence embeddings.
https://easyai.tech/ai-definition/attention/#type
1.Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
提出了两种 attention 模式,即 hard attention 和 soft attention
2.Effective Approaches to Attention-based Neural Machine Translation
文章提出了两种 attention 的改进版本,即 global attention 和 local attention。
3.Attention Is All You Need
提出self attention
4.Hierarchical Attention Networks for Document Classification
提出了Hierarchical Attention用于文档分类
5.Attention-over-Attention Neural Networks for Reading Comprehension
提出了Attention Over Attention的Attention机制
6.Convolutional Sequence to Sequence Learning
论文中还采用了 Multi-step Attention
google继lasertagger之后的又一篇text edit paper
In contrast to conventional sequence-to-sequence (seq2seq) models, FELIX is efficient in low-resource settings and fast at inference time, while being capable of modeling flexible input-output transformations. We achieve this by decomposing the text-editing task into two sub-tasks: tagging to decide on the subset of input tokens and their order in the output text and insertion to in-fill the missing tokens in the output not present in the input.
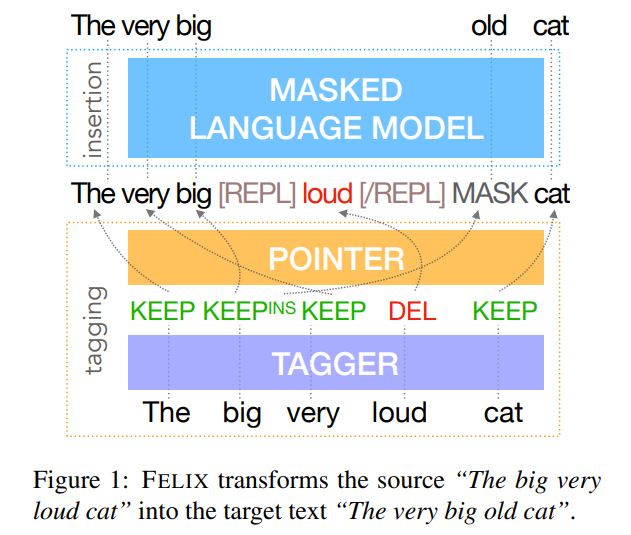
In particular, we have designed FELIX with the following requirements in mind: Sample efficiency, Fast inference time, Flexible text editing
FELIX decomposes the conditional probability of generating an output sequence $y$ from an input
$x$ as follows:
trained to optimize both the tagging and pointing loss:
Tagging :
tag sequence $\textbf{y}^t$由3种tag组成:$KEEP$,$DELETE$,$INSERT (INS)$
Tags are predicted by applying a single feedforward layer $f$ to the output of the encoder $\textbf{h}^L$ (the source sentence is first encoded using a 12-layer BERT-base model). $\textbf{y}^t_i=argmax(f(\textbf{h}^L_i))$
Pointing:
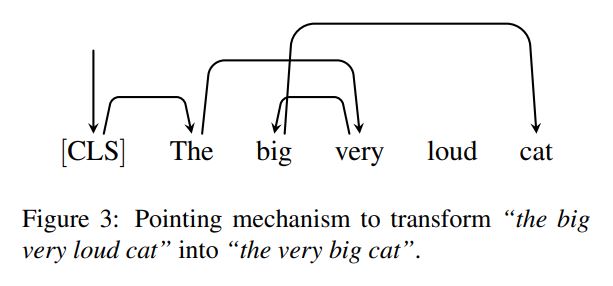
Given a sequence $\textbf{x}$ and the predicted tags $\textbf{y}^t$ , the re-ordering model generates a permutation $\pi$ so that from $\pi$and $\textbf{y}^t$ we can reconstruct the insertion model input $\textbf{y}^m$. Thus we have:
Our implementation is based on a pointer network. The output of this model is a series of predicted pointers (source token → next target token)
The input to the Pointer layer at position $i$:
其中$e(\textbf{y}_i^t)$is the embedding of the predicted tag,$e(\textbf{p}_i)$ is the positional embedding
The pointer network attends over all hidden states, as such:
其中$\textbf{h}_i^{L+1}$ as $Q $, $\textbf{h}_{\pi(i)}^{L+1}$ as $K$
When realizing the pointers, we use a constrained beam search

To represent masked token spans we consider two options: masking and infilling. In the former case the tagging model predicts how many tokens need to be inserted by specializing the $INSERT$ tag into $INS_k$, where $k$ translates the span into $ k$ $MASK$ tokens. For the infilling case the tagging model predicts a generic $INS$ tag.
Note that we preserve the deleted span in the input to the insertion model by enclosing it between $[REPL]$ and $[/REPL]$ tags.
our insertion model is also based on a 12-layer BERT-base and we can directly take advantage of the BERT-style pretrained checkpoints.
原版BERT的最大输入为512,为了使得BERT能解决超长文本的问题,作者在finetune阶段提出了两种策略来弥补这个问题,即利用BERT+LSTM或者BERT+transformer。
核心步骤:
1.split the input sequence into segments of a fixed size with overlap.
2.For each of these segments, we obtain H or P from BERT model.
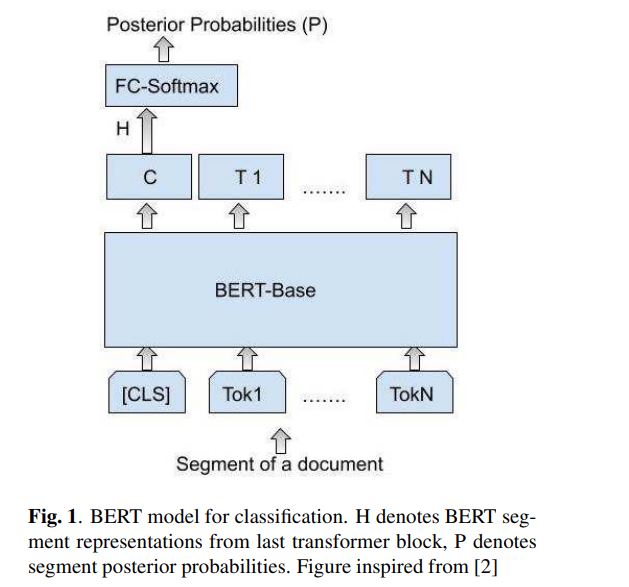
3.We then stack these segment-level representations into a sequence, which serves as input to a small (100-dimensional) LSTM layer.//replacing the LSTM recurrent layer in favor of a small Transformer model
4.Finally, we use two fully connected layers with ReLU (30-dimensional) and softmax (the same dimensionality as the number of classes) activations to obtain the final predictions.
在结构上和原版BERT没有差异,主要的改动在于:
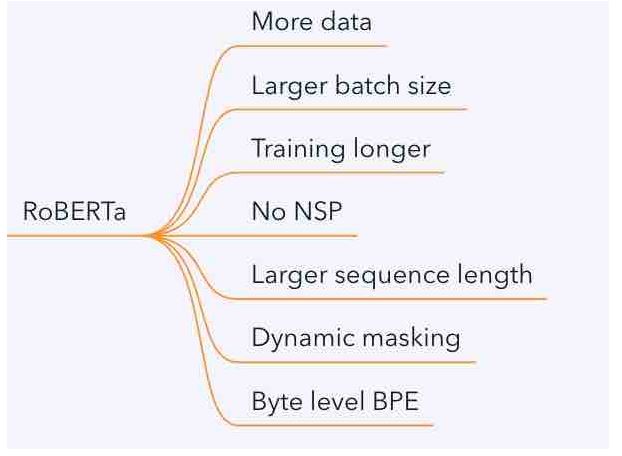
static masking: 原本的BERT采用的是static mask的方式,就是在create pretraining data中,先对数据进行提前的mask
dynamic masking: 每一次将训练example喂给模型的时候,才进行随机mask。
结果对比:
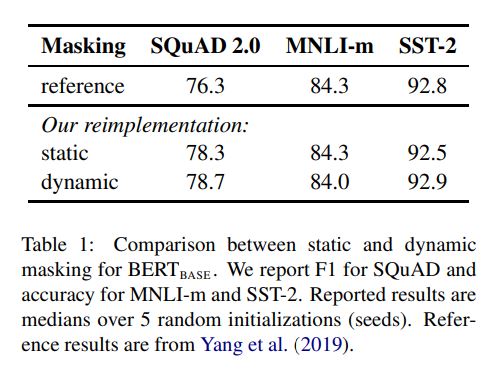
结论:动态占优
做了结果对比试验,结果如下:
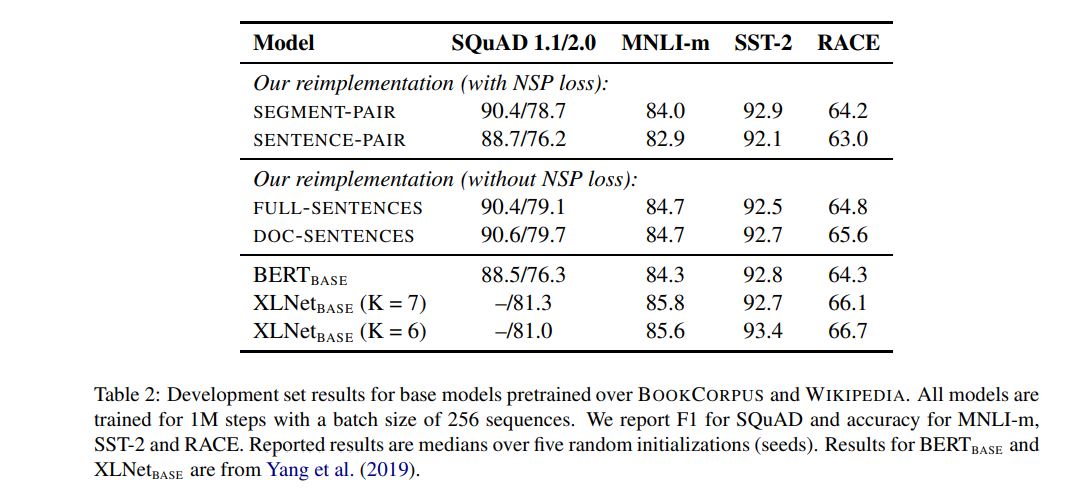
结论:
Model Input Format:
1.find that using individual sentences hurts performance on downstream tasks
Next Sentence Prediction:
1.removing the NSP loss matches or slightly improves downstream task performance
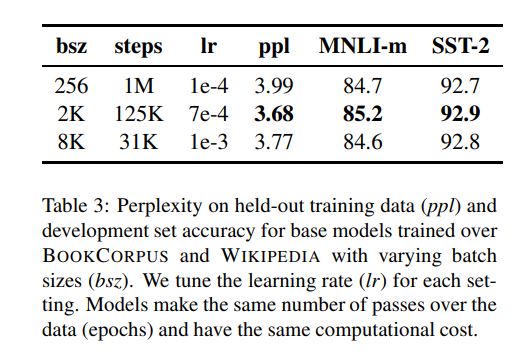
采用BBPE而不是wordpiece
1 roberta tokenizer 没有token_type_ids?
roberta 取消了NSP,所以不需要segment embedding 也就不需要token_type_ids,但是使用的时候发现中文是有token_type_ids的,英文没有token_type_ids的。没有token_type_ids,两句话怎么区别,分隔符sep还是有的,只是没有segment embedding
2 使用避坑
https://blog.csdn.net/zwqjoy/article/details/107533184
https://hub.fastgit.org/ymcui/Chinese-BERT-wwm
https://zhuanlan.zhihu.com/p/103205929
https://zhuanlan.zhihu.com/p/143064748
relying on corrupting the input with masks, BERT neglects dependency between the masked positions and suffers from a pretrain-finetune discrepancy.
propose XLNet, a generalized autoregressive pretraining method that (1) enables learning bidirectional contexts by maximizing the expected likelihood over all permutations of the factorization order and (2) overcomes the limitations of BERT thanks to its autoregressive formulation. (3) , XLNet integrates ideas from Transformer-XL
example:[New, York, is, a, city] . select the two tokens [New, York] as the prediction targets and maximize log p (New York | is a city)
In this case, BERT and XLNet respectively reduce to the following objectives:
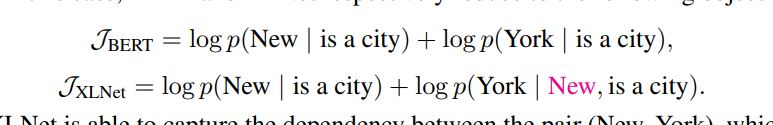
1 AR language modeling
对于给定的句子$\textbf{x}=[x_1,…,x_T]$,AR language modeling performs pretraining by maximizing the likelihood under the forward autoregressive factorization
其中$h_{\theta}(\textbf{x}_{1:t-1})$是考虑上下文的文本表示,$e(x_t)$为$x_t$的词向量
2 AE anguage modeling
对于BERT这种AE模型,首先利用$\textbf{x}$构造遮盖的tokens$\overline{\textbf{x}}$和未遮盖的tokens$\hat{\textbf{x}}$,然后the training objective is to reconstruct $\overline{\textbf{x}}$ from $\hat{\textbf{x}}$:
其中$m_t=1$表示$x_t$被遮盖了,AR语言模型$t$时刻只能看到之前的时刻,因此记号是$h_{\theta}(\textbf{x}_{1:t-1})$;而AE模型可以同时看到整个句子的所有Token,因此记号是$H_{\theta}(\hat{\textbf{x}})_t$
这两个模型的优缺点分别为:
3 对比
1.AE因为遮盖词只是假设相互独立不是严格相互独立,因此为$\approx$。
2.AE在预训练时会出现特殊的token为[MASK],但是它在下游的fine-tuning中不会出现,这就出现了预训练 — finetune的不一致问题。而AR语言模型不会有这个问题。
3.AR语言模型只能参考一个方向的上下文,而AE可以参考双向的上下文。
we propose the permutation language modeling objective that not only retains the benefits of AR models but also allows models to capture bidirectional context
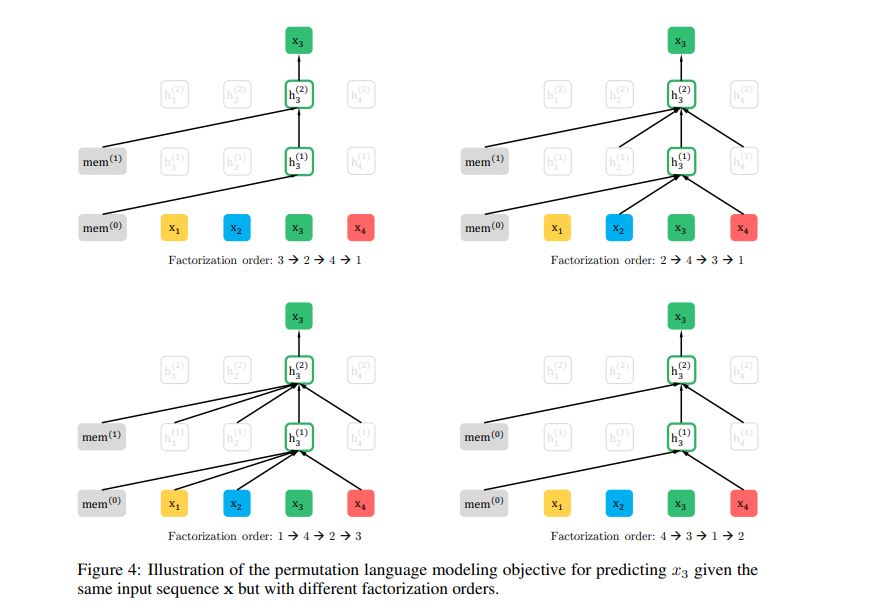
给定长度为$T$的序列,总共有$T!$种排列方法。注意输入顺序是不会变的,因为模型在微调期间只会遇到具有自然顺序的文本序列。作者就是通Attention Mask,把其它没有被选到的单词Mask掉,不让它们在预测单词$x_i$的时候发生作用,看着就类似于把这些被选中的单词放到了上文。
举个例子,如下图,输入序列为$\{x_1,x_2,x_3,x_4\}$,总共有4!,24种情况,作者取了其中4个。假如预测$x_3$,第一个排列为$x_3 \rightarrow x_2 \rightarrow x_4 \rightarrow x_1 $,没有排在$x_3$前面对象,所以只连接了mem,对于真实情况就是输入还是$x_1 \rightarrow x_2 \rightarrow x_3 \rightarrow x_4 $,然后mask掉全部输入,即只利用mem预测$ x_3 $;第二个排列为$x_2 \rightarrow x_4 \rightarrow x_3 \rightarrow x_1 $,$x_2,x_4$排在$x_3$前面,所以连接了$x_2,x_4$对应的向量表示,对于真实情况就是输入还是$x_1 \rightarrow x_2 \rightarrow x_3 \rightarrow x_4 $,然后mask掉$x_1,x_3$,剩余$x_2,x_4$,即利用mem,$x_2,x_4$预测$ x_3 $。
排列语言模型的目标是调整模型参数使得下面的似然概率最大
其中$\textbf{z}$为随机变量,表示某个位置排列,$\mathcal{Z}_T$表示全部的排列,$z_t$,$\textbf{z}_{<t}$分别表示某个位置排列的第$t$个元素和与其挨着的前面$t-1$个元素。
Target-Aware Representations
采用AE原来的表达形式来描述下一个token的分布$p_{\theta}(X_{z_t}|\textbf{x}_{\textbf{z}_{<t}})$如下
这样表达有一个问题就是没有考虑预测目标词的位置,即没有考虑$ z_t$,这会导致ambiguity in target prediction。证明如下:假设有两个不同的排列$\textbf{z}^{(1)}$和$\textbf{z}^{(2)}$,并且满足如下关系:
可以推导出
但是$p_{\theta}(X_{z_t^{(1)}}=x|\textbf{x}_{\textbf{z}_{<t}^{(1)}}),p_{\theta}(X_{z_t^{(2)}}=x|\textbf{x}_{\textbf{z}_{<t}^{(2)}})$应该不一样,因为目标词的位置不同
为了解决这个问题,提出了Target-Aware Representations,其实就是考虑了目标词的位置
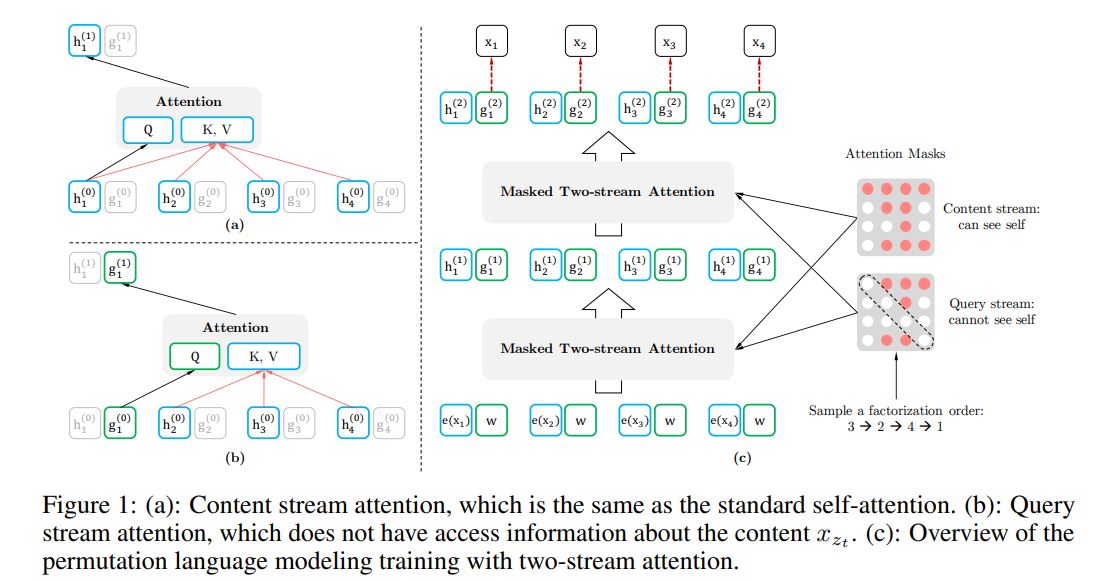
Two-Stream Self-Attention
contradiction

To resolve such a contradiction,we propose to use two sets of hidden representations instead of one:

假设有self-attention的层号为$m=1,2,…,M$,$g_i^{(0)}=w$,$h_i^{(0)}=e(x_i)$,Two-Stream Self-Attention可以表示为
举个例子,如下图
预训练最终使用$g_{z_t}^{(M)}$计算公式(4),during finetuning, we can simply drop the query stream and use the content stream
during pretrain, we can use the last-layer query representation $g_{z_t}^{(M)}$ to compute Eq. (4).
during finetuning, we can simply drop the query stream and use the content stream as a normal Transformer(-XL).
因为排序很多,计算量很大,所以需要采样。将$z$分隔成$z_{t_\le c}$和 $z_{t_>c}$,$c$为分隔点,我们选择预测后面的词语,因为后面的词语包含的信息更加丰富。引入超参数$K$调整$c$,使得需要预测$\frac{1}{K}$的词($\frac{|z|-c}{|z|}\approx\frac{1}{K}$),优化目标为:
We integrate two important techniques in Transformer-XL, namely the relative positional encoding scheme and the segment recurrence mechanism
Relative Segment Encodings
recurrence mechanism
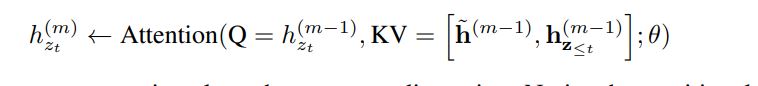
the input to our model is the same as BERT: [CLS, A, SEP, B, SEP], where “SEP” and “CLS” are two special symbols and “A” and “B” are the two segments. Although we follow the two-segment data format, XLNet-Large does not use the objective of next sentence prediction
BERT that adds an absolute segment embedding,这里采用Relative Segment Encodings
There are two benefits of using relative segment encodings. First, the inductive bias of relative encodings improves generalization [9]. Second, it opens the possibility of finetuning on tasks that have more than two input segments, which is not possible using absolute segment encodings.
这里有个疑问,对于多于两个seg的情况,比如3个seg,输入格式是否变成[CLS, A, SEP, B, SEP,C,SEP]
https://zhuanlan.zhihu.com/p/107350079
https://blog.csdn.net/weixin_37947156/article/details/93035607
https://www.cnblogs.com/nsw0419/p/12892241.html
https://www.cnblogs.com/mantch/archive/2019/09/30/11611554.html
https://cloud.tencent.com/developer/article/1492776