CDC是 Change Data Capture(变更数据获取 )的简称。 核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入 、 更新 以及 删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
Flink社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、 PostgreSQL 等数据库直接 读取全量数据 和 增量变更数据 的 source 组件。
说白了就是连接数据库,然后实时监控变化
CDC是 Change Data Capture(变更数据获取 )的简称。 核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入 、 更新 以及 删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
Flink社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、 PostgreSQL 等数据库直接 读取全量数据 和 增量变更数据 的 source 组件。
说白了就是连接数据库,然后实时监控变化
概念
正向代理:代理的是客户端
反向代理:代理的是服务器端
作用
https://zhuanlan.zhihu.com/p/54793789
1、静态HTTP服务器
2、反向代理服务器
3、负载均衡
ranker-> nginx ->qr
4、虚拟主机
5、FastCGI
配置
conf/vhosts
监听老的端口 生成新的端口
启动
./nginx
1 nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address already in use)
1 | lsof -i :80 |grep nginx |grep -v grep|awk '{print $2}' |
https://blog.csdn.net/hongzhen91/article/details/90812686
一个任务的并行实例(线程)数目就被称为该任务的并行度
并行度设置层次
1 Operator Level(算子层次)
1 | setParallelism |
2Execution Environment Level(执行环境层次)
3Client Level(客户端层次)
4System Level(系统层次)
优先级1>2>3>4
https://www.cnblogs.com/wdh01/p/16038278.html
首先和逻辑分区区别开,逻辑分区包括keyBy等算子
逻辑分区只不过将数据按照key分组,哪个key分到哪个task,系统自动控制,万一分配不均,会发生数据倾斜
物理分区就是按一定逻辑将数据分配到不同Task,可以缓解数据倾斜
source(1)-》不同物理分区方式(3)-》slot
分类
1 随机分区 random
2 轮询分区round-robin
3 重缩放分区 rescale
4 分局分区 global
5 自定义 custom
6 广播
不完全算物理分区方式
之前版本
1 | //流 |
现在版本
通过执行模式 execution mode选择
1 流处理 streaming 默认
2 批处理 batch
3 自动 automatic
(1) 通过命令行
1 | flink run -Dexecution.runtime-mode=BATCH/../.. |
(2)代码
1 | env.setRuntimeMode(RuntimeExecutionMode.STREAMING); |
1 | CREATE TABLE IF NOT EXISTS `runoob_tbl`( |
https://www.w3school.com.cn/sql/sql_datatypes.asp
array
https://www.educba.com/array-in-sql/
AUTO INCREMENT
1 | CREATE TABLE Persons |
开始值是 1,每条新记录递增 1
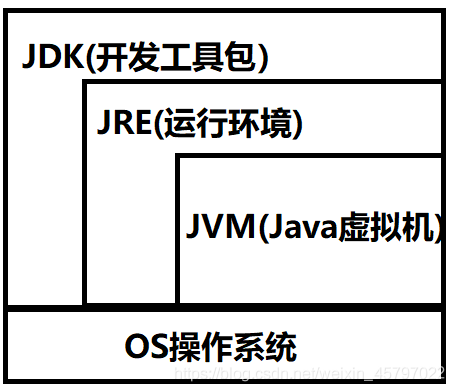
https://blog.csdn.net/m0_37568814/article/details/81288756
https://zhuanlan.zhihu.com/p/138523723
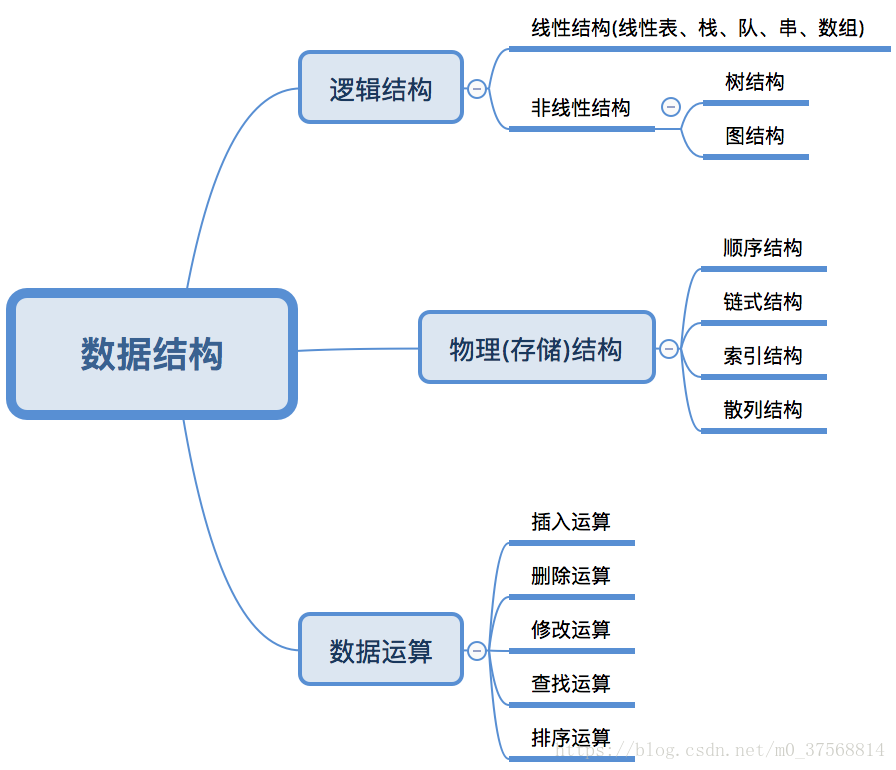
数据结构包括:逻辑结构,存储结构,数据运算
数据的逻辑结构主要分为线性结构和非线性结构。
数据的存储结构,表示数据元素之间的逻辑关系,一种数据结构的逻辑结构根据需要可以表示成多种存储结构,常用的存储结构有: