实时数仓案例(电商)
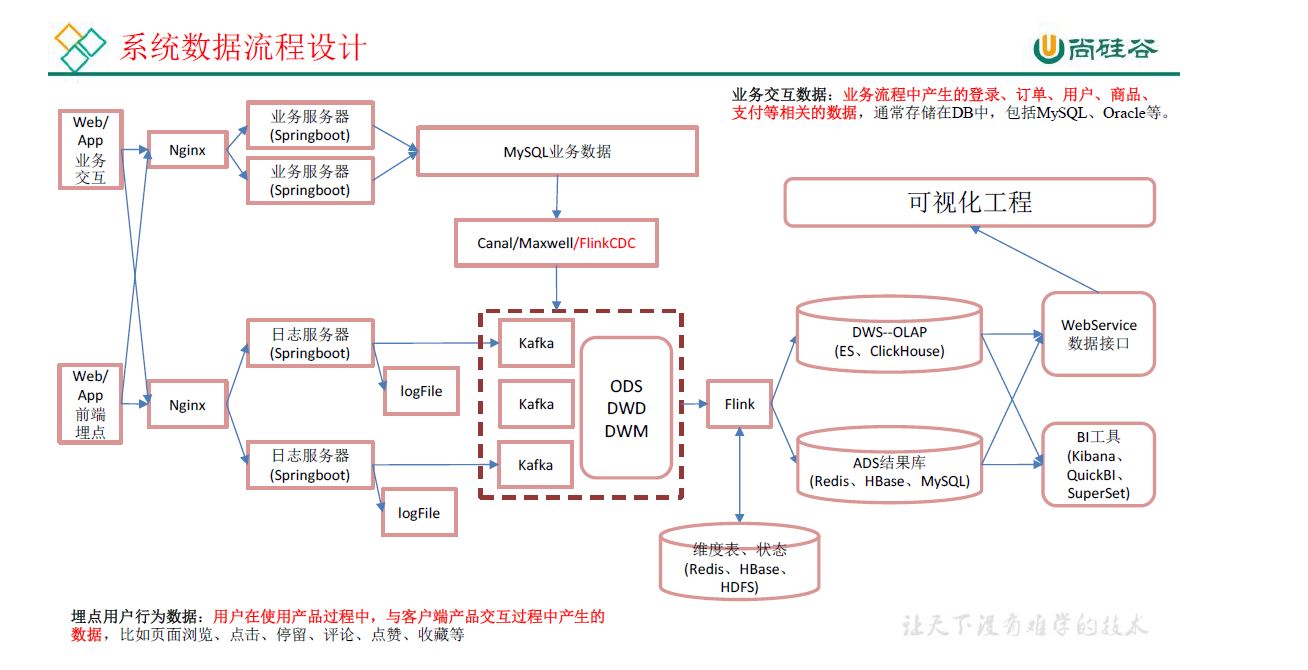
0 架构
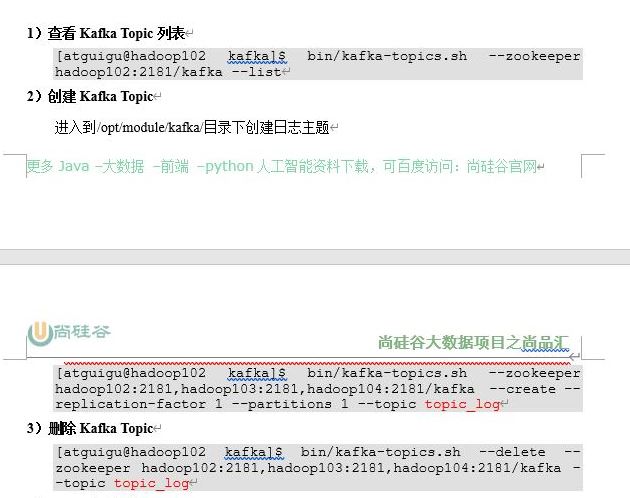
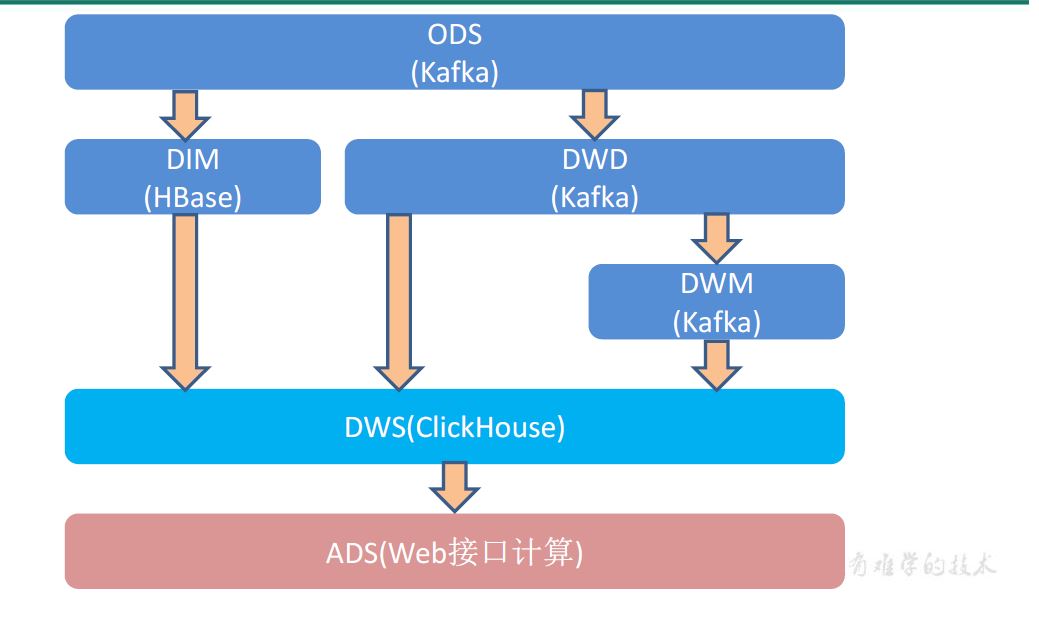
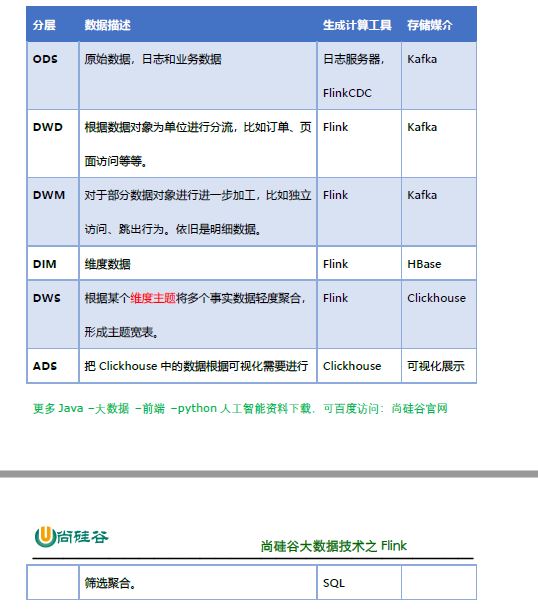
1 ods
1 日志数据
前端(jar,产生日志数据)-》Nginx(集群间负载均衡)-》日志服务器(springboot,采集数据,jar)-》log,ods(kafka)
本地测试,本地起应用 -》 单机部署,单服务器起应用 -》 集群部署,集群起应用
2 业务数据
前端,jar,产生业务数据-》mysql,配置什么同步-》flinkcdc-》ods(kafka)
2 dim、dwd
1 用户行为日志
ods(Kafka)-> flink -> dwd(kafka)
1 识别新老用户
业务需要
2 日志数据拆分
这3类日志,结构不同,写回Kafka不同主题
2 业务数据
ods(kafka) -> flink -> 1 维度数据,dim(HBASE) 2 事实数据 dwd(kafka)
1 ETL
过滤控制
2 动态分流
维度数据到hbase 事实数据到kafka
怎么分流?
ods的表里面哪些是维度表,哪些是事实表,需要提前知道表的分类信息,后面才可以分流。业务库的表会变化,表的分类信息实时更新,需要动态同步。这里将表的分类信息存在mysql,利用广播流发送。
3 dwm
dmd(kafka)-> flink -> dwm(kafka)
1 访问uv计算
UV,unique visitor
2 跳出明细计算
跳出率=跳出次数 / 访问次数
3 订单主题表
4 支付主题表
4 dws
dwm(kafka)-> flink -> dws(clickhouse)
1 访客主题宽表
2 商品主题宽表
3 地区主题表
4 关键词主题表