collections
1 Counter
1 |
|
1 Counter
1 |
|
https://par.nsf.gov/servlets/purl/10277191
So a generalized LTR problem is to find the optimal ranking function f ∗ by minimizing the loss function over some labeled dataset
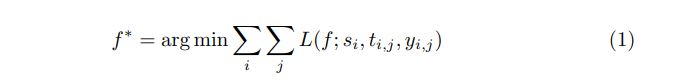
f 是ranking function,s是query,t是候选集,y is the label set where labels represent grades
Without loss of generality, the ranking function f could be further abstracted by the following unified formulation
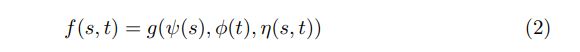
ψ, ϕare representation functions which extract features from s and t respectively η is the interaction function which extracts features from (s, t) pair, and g is the evaluation function which computes the relevance score based on the feature representations.
Symmetric Architecture: The inputs s and t are assumed to be homogeneous, so that symmetric network structure could be applied over the inputs
Asymmetric Architecture: The inputs s and t are assumed to be heterogeneous, so that asymmetric network structures should be applied over the inputs
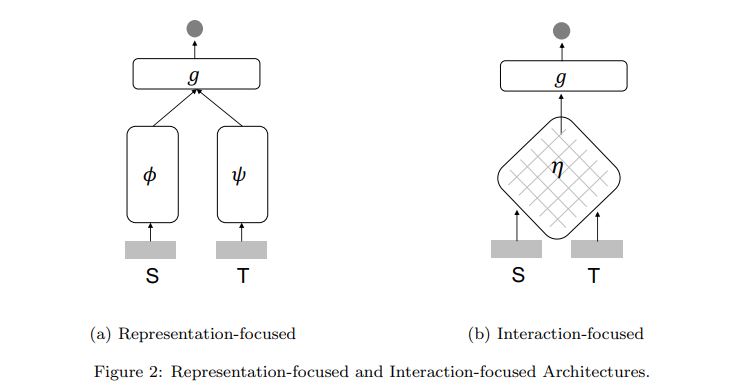
Representation-focused Architecture: The underlying assumption of this type of architecture is that relevance depends on compositional meaning of the input texts. Therefore, models in this category usually define complex representation functions ϕ and ψ (i.e., deep neural networks), but no interaction function η
Interaction-focused Architecture: The underlying assumption of this type of architecture is that relevance is in essence about the relation between the input texts, so it would be more effective to directly learn from interactions rather than from individual representations. Models in this category thus define the interaction function η rather than the representation functions ϕ and ψ
Hybrid Architecture: In order to take advantage of both representation focused and interaction-focused architectures, a natural way is to adopt a hybrid architecture for feature learning. We find that there are two major hybrid strategies to integrate the two architectures, namely combined strategy and coupled strategy.
Single-granularity Architecture: The underlying assumption of the single granularity architecture is that relevance can be evaluated based on the high level features extracted by ϕ, ψ and η from the single-form text inputs.
Multi-granularity Architecture: The underlying assumption of the multigranularity architecture is that relevance estimation requires multiple granularities of features, either from different-level feature abstraction or based on different types of language units of the inputs
Similar to other LTR algorithms, the learning objective of neural ranking models can be broadly categorized into three groups: pointwise, pairwise, and listwise.
1 loss
The idea of pointwise ranking objectives is to simplify a ranking problem to a set of classification or regression problems
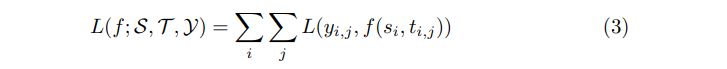
a. Cross Entropy
For example, one of the most popular pointwise loss functions used in neural ranking models is Cross Entropy:
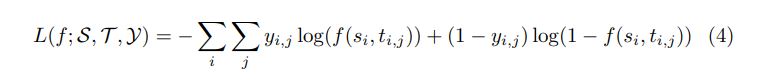
b. Mean Squared Error
There are other pointwise loss functions such as Mean Squared Error for numerical labels, but they are more commonly used in recommendation tasks.
2 优缺点
a.advantages
First, it simple and easy to scale. Second, the outputs have real meanings and value in practice. For instance, in sponsored search, a model learned with cross entropy loss and clickthrough rates can directly predict the probability of user clicks on search ads, which is more important than creating a good result list in some application scenarios.
b.disadvantages
less effective ,Because pointwise loss functions consider no document preference or order information, they do not guarantee to produce the best ranking list when the model loss reaches the global minimum.
1 loss
Pairwise ranking objectives focus on optimizing the relative preferences between documents rather than their labels.
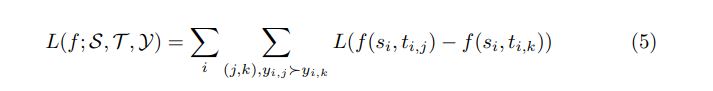
a.Hinge loss
b.cross entropy
RankNet
2 优缺点
a.advantages
effective in many tasks
b.disadvantages
pairwise methods does not always lead to the improvement of final ranking metrics due to two reasons: (1) it is impossible to develop a ranking model that can correctly predict document preferences in all cases; and (2) in the computation of most existing ranking metrics, not all document pairs are equally important.
1 loss
listwise loss functions compute ranking loss with each query and their candidate document list together
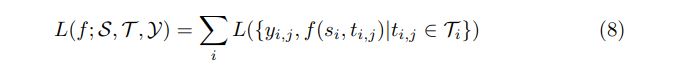
a. ListMLE
https://blog.csdn.net/qq_36478718/article/details/122598406
b.Attention Rank function
https://arxiv.org/abs/1804.05936

c. softmax-based listwise
https://arxiv.org/pdf/1811.04415.pdf
2 优缺点
a.advantages
While listwise ranking objectives are generally more effective than pairwise ranking objectives
b.disadvantages
their high computational cost often limits their applications. They are suitable for the re-ranking phase over a small set of candidate documents
the optimization of neural ranking models may include the learning of multiple ranking or non-ranking objectives at the same time.
1 Supervised learning
2 Weakly supervised learning
3 Semi-supervised learning
比较了常见模型在不同应用的效果
1 Ad-hoc Retrieval
https://blog.csdn.net/qq_44092699/article/details/106335971
Ad-hoc information retrieval refers to the task of returning information resources related to a user query formulated in natural language.
2 QA
Hive MetaStore - It is a central repository that stores all the structure information of various tables and partitions in the warehouse. It also includes metadata of column and its type information, the serializers and deserializers which is used to read and write data and the corresponding HDFS files where the data is stored.
Embedded,Local,Remote
https://blog.csdn.net/epitomizelu/article/details/117091656
https://zhuanlan.zhihu.com/p/473378621
https://blog.csdn.net/qq_40990732/article/details/80914873
1 A Survey on Open Set Recognition
https://arxiv.org/abs/2109.00893
2 Open-Set Recognition: A Good Closed-Set Classifier is All You Need
https://arxiv.org/abs/2110.06207
3 Recent Advances in Open Set Recognition: A Survey
https://blog.csdn.net/weixin_45366499/article/details/115449175
1 动态表
flink中的表是动态表
静态表:hive,mysql等
动态表:不断更新
2 持续查询
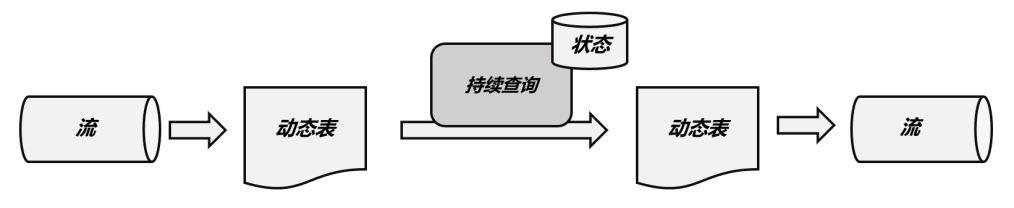
Apache Flink 有两种关系型 API 来做流批统一处理:Table API 和 SQL。
Table API 是用于 Scala 和 Java 语言的查询 API,它可以用一种非常直观的方式来 组合使用选取、过滤、join 等关系型算子。
1 | Table maryClickTable = eventTable |
SQL 是基于 Apache Calcite 来实现的标准 SQL
1 | Table urlCountTable = tableEnv.sqlQuery( |
表环境和流执行环境不同

stream 《——》table
1 | tableEnv表环境 |
可以在创建表的时候用 WITH子句指定连接器connector
./bin/sql client.sh
事件事件、处理事件
在分布式架构中,当某个节点出现故障,其他节点基本不受影响。这时只需要重启应用,恢复之前某个时间点的状态继续处理就可以了。这一切看似简单,可是在实时流处理中,我们不仅需要保证故障后能够重启继续运行,还要保证结果的正确性、故障恢复的速度、对处理性能的影响,这就需要在架构上做出更加精巧的设计。
在Flink中,有一套完整的容错机制( fault tolerance)来保证故障后的恢复,其中最重要的就是检查点( checkpoint)。在第九章中,我们已经介绍过检查点的基本概念和用途,接下来我 们就深入探讨一下检查点的原理和 Flink的容错机制。
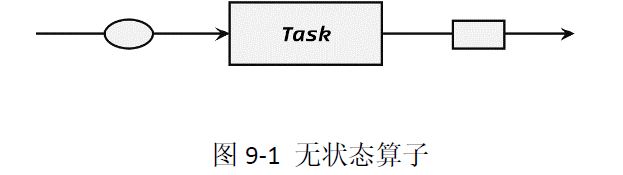
1 无状态
2 有状态
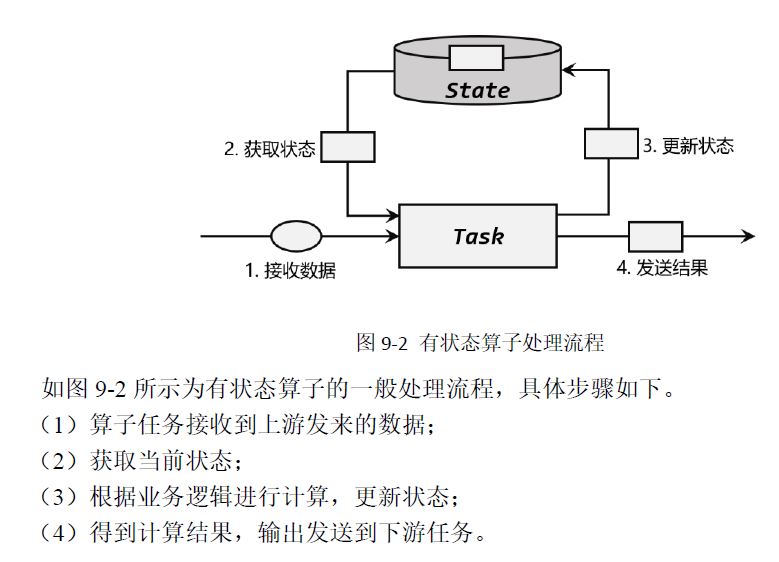
Flink 有两种状态:托管状态(Managed State)和原始状态(Raw State)。一般情况使用托管状态,只有在托管状态无法实现特殊需求,才会使用原始转态,一般情况不使用。
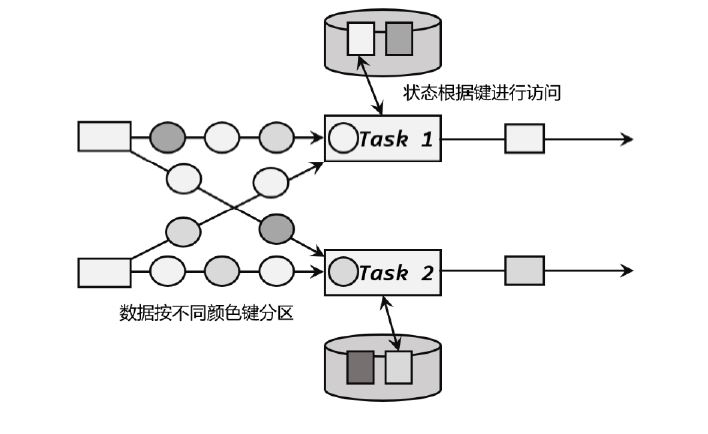
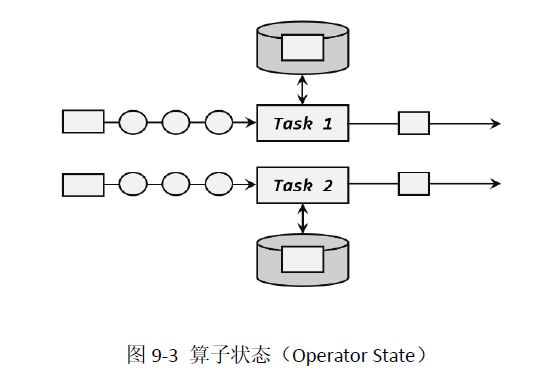
托管状态分类:算子状态(Operator State)和按键分区状态(Keyed State)
1 按键分区状态
2 算子状态
3 广播状态 Broadcast State
特殊的算子状态
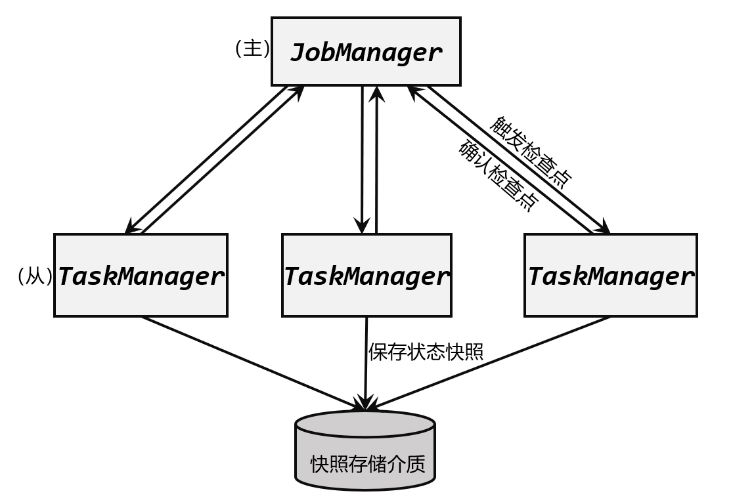
对状态进行持久化( persistence)保存,这样就可以在发生故障后进行重启恢复。
flink状态持久化方式:写入一个“检查点”( checkpoint)或者保存点 savepoint
保存到外部存储系统中。具体的存储介质,一般是分布式文件系统( distributed file system)。
在Flink中,状态的存储、访问以及维护,都是由一个可插拔的组件决定的,这个组件就
叫作状态后端( state backend)。状态后端主要负责两件事:一是本地的状态管理,二是将检查
点( checkpoint)写入远程的 持久化存储。
类似的多个事件的组合,我们把它叫作“复杂事件”。对于复杂时间的处理,由于涉及到事件的严格顺序,有时还有时间约束,我们很难直接用 SQL或DataStream API来完成。于是只好放大招 派底层的处理函数( process function)上阵了。处理函数确实可以搞定这些需求,不过对于非常复杂的组合事件,我们可能需要设置很多状态、定时器,并在代码中定义各种条件分支( if else)逻辑来处理,复杂度会非常高,很可能会使代码失去可读性。怎 样处理这类复杂事件呢? Flink为我们提供了专门用于处理复杂事件的库 CEP,可以让我们更加轻松地解决这类棘手的问题。这在企业的实时风险控制中有非常重要的作用。
Complex Event Processing,flink 专门用来处理复杂事件的库
cep底层是状态机
复杂事件可以通过设计状态机来处理,用户自己写容易出错,cep帮我们封装好,用户写顶层逻辑就可以了
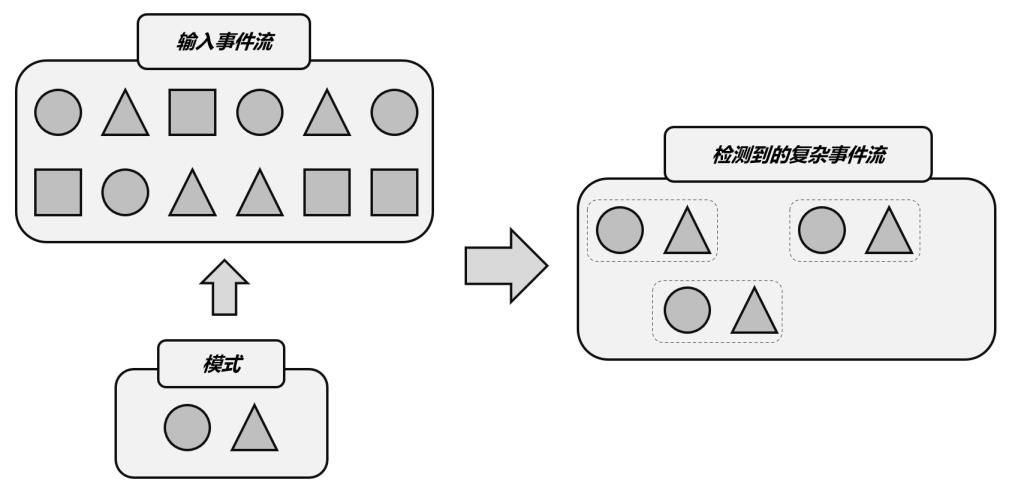
总结起来,复杂事件处理(CEP)的流程可以分成三个步骤
(1)定义一个匹配规则
(2)将匹配规则应用到事件流上,检测满足规则的复杂事件
(3)对检测到的 复杂事件进行处理,得到结果进行输出