多流转换
简单划分的话,多流转换可以分为“分流”和“合流”两大类。在 Flink中,分流操作可以通过处理函数的侧输出流( side output)很容易地实现
而合流则提供不同层级的各种 API
任务:
stream数量 ,每个stream可以有多个子任务(并行度)
keyby只能算分组,不算分流
资源:
task manager数量,slot数量
1 分流
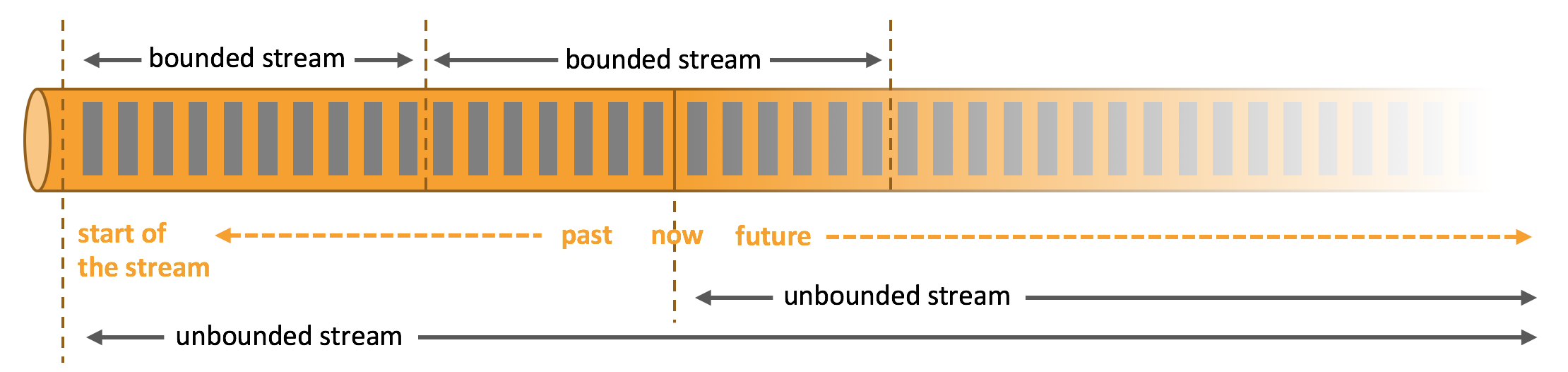
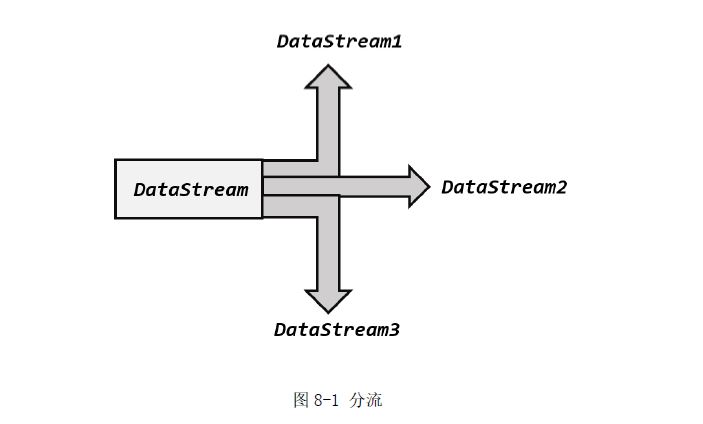
所谓“分流”,就是将一条数据流拆分成完全独立的两条、甚至多条流。也就是基于一个
DataStream,得到完全平等的多个子 DataStream,如图 8-1所示。一般来说,我们会定义一些
筛选条件,将符合条件的数据拣选出来放到对应的流里。
在Flink 1.13版本中,已经弃用了 .split()方法,取而代之的是直接用处理函数( process function)的侧输出流 (side output)。
2 合流
既然一条流可以分开,自然多条流就可以合并。在实际应用中,我们经常会遇到来源不同
的多条流,需要将它们的数据进行联合处理。所以 Flink中合流的操作会更加普遍,对应的
API也更加丰富。
2.1 基本合流
1 联合( Union)
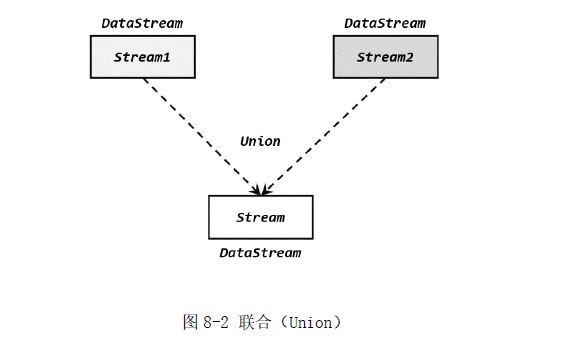
可以多条(大于2)合并,数据类型必须一致
2 连接( Connect)
必须两条,数据类型可以不同
2.2 双流联结 join
对于两条流的合并,很多情况我们并不是简单地将所有数据放在一起,而是希望根据某个
字段的值将它们联结起来,“配对”去做处理。
1 窗口联结( Window Join
2 间隔联结( Interval Join
3 窗口同组联结( Window CoGroup