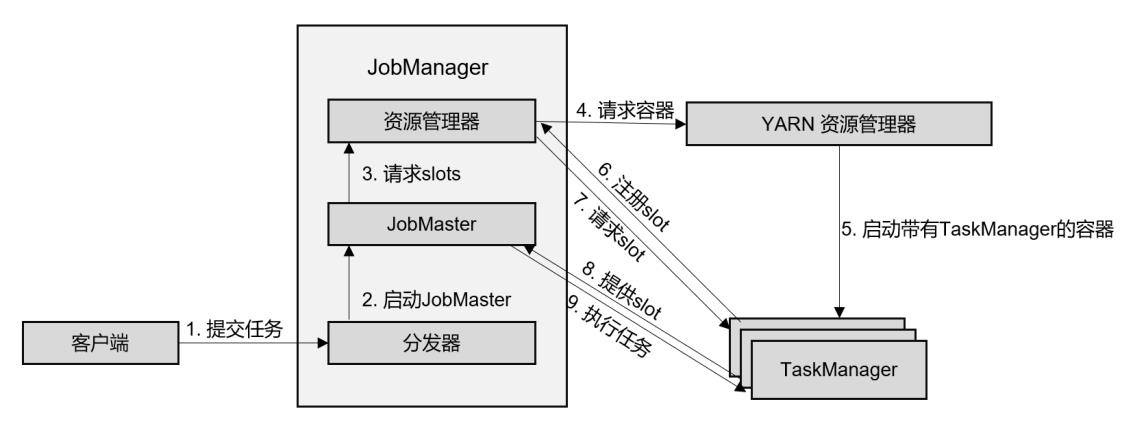
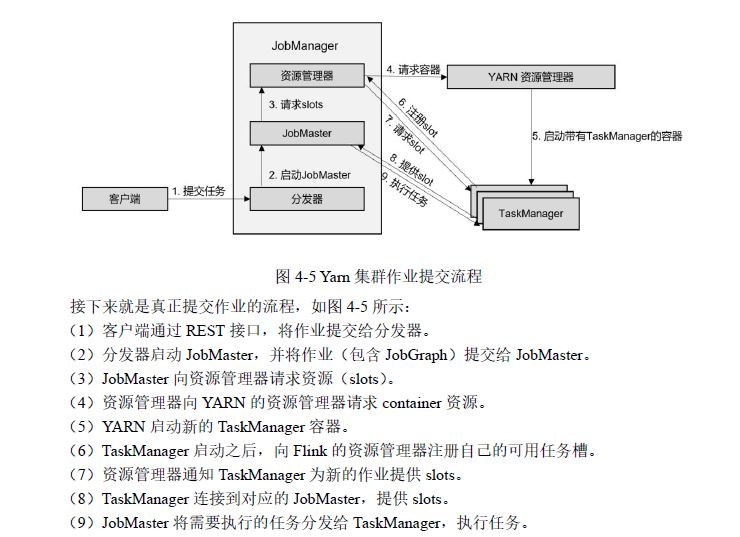
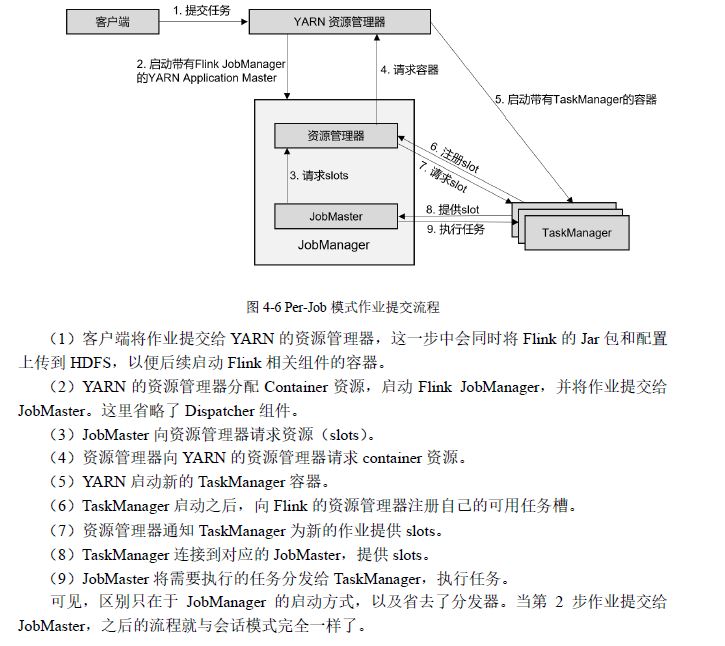
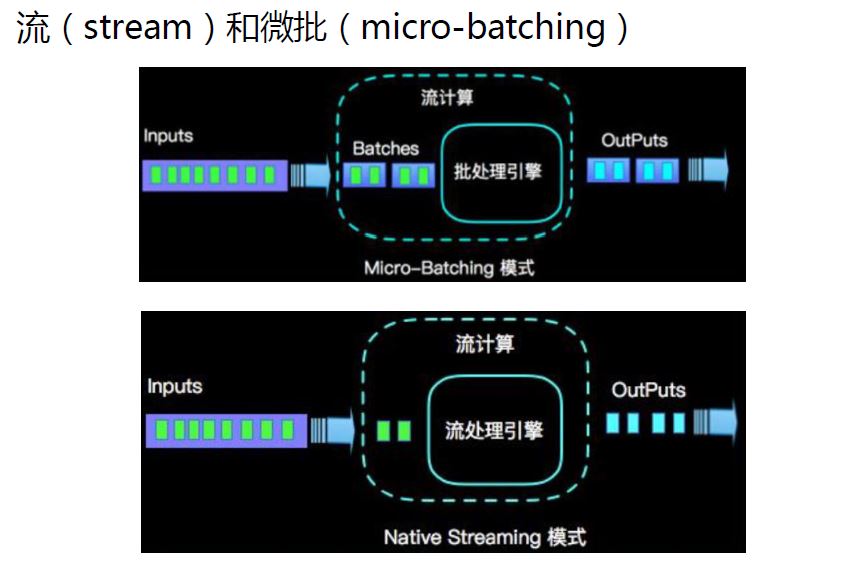
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
| 1 参数必选 :
-n,--container <arg> 分配多少个yarn容器 (=taskmanager的数量)
2 参数可选 :
-D <arg> 动态属性
-d,--detached 独立运行
-jm,--jobManagerMemory <arg> JobManager的内存 [in MB]
-nm,--name 在YARN上为一个自定义的应用设置一个名字
-q,--query 显示yarn中可用的资源 (内存, cpu核数)
-qu,--queue <arg> 指定YARN队列.
-s,--slots <arg> 每个TaskManager使用的slots数量
-tm,--taskManagerMemory <arg> 每个TaskManager的内存 [in MB]
-z,--zookeeperNamespace <arg> 针对HA模式在zookeeper上创建NameSpace
-id,--applicationId <yarnAppId> YARN集群上的任务id,附着到一个后台运行的yarn session中
3 run [OPTIONS] <jar-file> <arguments>
run操作参数:
-c,--class <classname> 如果没有在jar包中指定入口类,则需要在这里通过这个参数指定
-m,--jobmanager <host:port> 指定需要连接的jobmanager(主节点)地址,使用这个参数可以指定一个不同于配置文件中的jobmanager
-p,--parallelism <parallelism> 指定程序的并行度。可以覆盖配置文件中的默认值。
4 启动一个新的yarn-session,它们都有一个y或者yarn的前缀
例如:./bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar
连接指定host和port的jobmanager:
./bin/flink run -m SparkMaster:1234 ./examples/batch/WordCount.jar -input hdfs://hostname:port/hello.txt -output hdfs://hostname:port/result1
启动一个新的yarn-session:
./bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar -input hdfs://hostname:port/hello.txt -output hdfs://hostname:port/result1
5 注意:命令行的选项也可以使用./bin/flink 工具获得。
6 Action "run" compiles and runs a program.
Syntax: run [OPTIONS] <jar-file> <arguments>
"run" action options:
-c,--class <classname> Class with the program entry point
("main" method or "getPlan()" method.
Only needed if the JAR file does not
specify the class in its manifest.
-C,--classpath <url> Adds a URL to each user code
classloader on all nodes in the
cluster. The paths must specify a
protocol (e.g. file://) and be
accessible on all nodes (e.g. by means
of a NFS share). You can use this
option multiple times for specifying
more than one URL. The protocol must
be supported by the {@link
java.net.URLClassLoader}.
-d,--detached If present, runs the job in detached
mode
-n,--allowNonRestoredState Allow to skip savepoint state that
cannot be restored. You need to allow
this if you removed an operator from
your program that was part of the
program when the savepoint was
triggered.
-p,--parallelism <parallelism> The parallelism with which to run the
program. Optional flag to override the
default value specified in the
configuration.
-q,--sysoutLogging If present, suppress logging output to
standard out.
-s,--fromSavepoint <savepointPath> Path to a savepoint to restore the job
from (for example
hdfs:///flink/savepoint-1537).
7 Options for yarn-cluster mode:
-d,--detached If present, runs the job in detached
mode
-m,--jobmanager <arg> Address of the JobManager (master) to
which to connect. Use this flag to
connect to a different JobManager than
the one specified in the
configuration.
-yD <property=value> use value for given property
-yd,--yarndetached If present, runs the job in detached
mode (deprecated; use non-YARN
specific option instead)
-yh,--yarnhelp Help for the Yarn session CLI.
-yid,--yarnapplicationId <arg> Attach to running YARN session
-yj,--yarnjar <arg> Path to Flink jar file
-yjm,--yarnjobManagerMemory <arg> Memory for JobManager Container with
optional unit (default: MB)
-yn,--yarncontainer <arg> Number of YARN container to allocate
(=Number of Task Managers)
-ynl,--yarnnodeLabel <arg> Specify YARN node label for the YARN
application
-ynm,--yarnname <arg> Set a custom name for the application
on YARN
-yq,--yarnquery Display available YARN resources
(memory, cores)
-yqu,--yarnqueue <arg> Specify YARN queue.
-ys,--yarnslots <arg> Number of slots per TaskManager
-yst,--yarnstreaming Start Flink in streaming mode
-yt,--yarnship <arg> Ship files in the specified directory
(t for transfer)
-ytm,--yarntaskManagerMemory <arg> Memory per TaskManager Container with
optional unit (default: MB)
-yz,--yarnzookeeperNamespace <arg> Namespace to create the Zookeeper
sub-paths for high availability mode
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper
sub-paths for high availability mode
|