sparksql对比hive sql
Hive和Spark 均是“分布式SQL计算引擎”,mysql等不是,mysql跑单机上
均是构建大规模结构化数据计算的绝佳利器,同时SparkSQL拥有更好的性能。目前,企业中使用Hive仍旧居多,但SparkSQL将会在很近的未来替代Hive成为分布式SQL计算市场的顶级
Hive和Spark 均是“分布式SQL计算引擎”,mysql等不是,mysql跑单机上
均是构建大规模结构化数据计算的绝佳利器,同时SparkSQL拥有更好的性能。目前,企业中使用Hive仍旧居多,但SparkSQL将会在很近的未来替代Hive成为分布式SQL计算市场的顶级
1 union ,union all
https://www.w3school.com.cn/sql/sql_union.asp
1 | select 'mobile' as platform union |
2 join
left join 、right join、 inner join,FULL OUTER JOIN,默认join 为 inner join
https://www.cnblogs.com/ingstyle/p/4368064.html
1 | #多个left join |
1 | from Trips T1 |
3.from student A,student B,student C
将三个 student 表相互连接成一个
https://blog.csdn.net/zhangyj_315/article/details/2249209
1 group by
1.group by columns1,columns2
按照字段分组,多个字段看成整体, 分完每组就一行,取每组第一行数据
2.+条件判断
Having
having 子句的作用是筛选满足条件的组,不是在组内选行
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
3.注意
有时候不能取第一行,怎么解决?1070. 产品销售分析 III
a 可以先排序,把目标行变成第一行 可以参考https://blog.csdn.net/shiyong1949/article/details/78482737 好像不行
b 使用开窗函数解决,可以
嵌套
http://c.biancheng.net/sql/sub-query.html
1 | select a.Score as Score, |
as后加别名,也可不要as
关键字like
通配符
https://www.cnblogs.com/Leophen/p/11397621.html
1 | select * from table where name like "%三%" |
1.IF
表达式:IF( condition, valua1, value2 )
条件为true,则值是valua1,条件为false,值就是value2
2 case
input几行output几行
一行一行来
https://zhuanlan.zhihu.com/p/240717732
两种形式:
1 | --type1 |
then后面多个值
then 1 可
then (1,1) 不可
where xx in (1,1)可
3 where
1 | # Write your MySQL query statement below |
4 判断
1 in
(E1.id , E1.month) in ((1,8))
2 BETWEEN AND
BETWEEN ‘2019-06-28’ AND ‘2019-07-27’
3 EXISTS
用于判断查询子句是否有记录,如果有一条或多条记录存在返回 True,否则返回 False。
1 | SELECT column_name(s) |
1.空字符和null的区别
https://blog.csdn.net/weixin_42214393/article/details/80463912
2.判断NULL
is not NULL
!=NULL 有问题
ifnull(sum(quantity), 0)
3 和 in、not in结合时
https://blog.csdn.net/qq_22592457/article/details/108024521
1 大小判断
available_from < ‘2019-05-23’
datediff(date1,date2)
2 格式转化
DATE_FORMAT()
https://www.w3school.com.cn/sql/func_date_format.asp
1 distinct
https://blog.csdn.net/zhangzehai2234/article/details/88361586
1 | select distinct expression[,expression...] from tables [where conditions]; |
在使用distinct的过程中主要注意一下几点:
distinct , count 一起用
1 | ##建表 |
https://blog.csdn.net/qq_29168493/article/details/79149132
查看当前数据库状态,可以统计当前数据库不同语句的执行频次
获取sql执行计划,结果明细参考
https://cloud.tencent.com/developer/article/1093229
http://m.biancheng.net/sql/transaction.html
https://zhuanlan.zhihu.com/p/372330656
https://medium.com/swlh/recursion-in-sql-explained-graphically-679f6a0f143b
https://www.sqlservertutorial.net/sql-server-basics/sql-server-recursive-cte/
1 | WITH expression_name (column_list) |
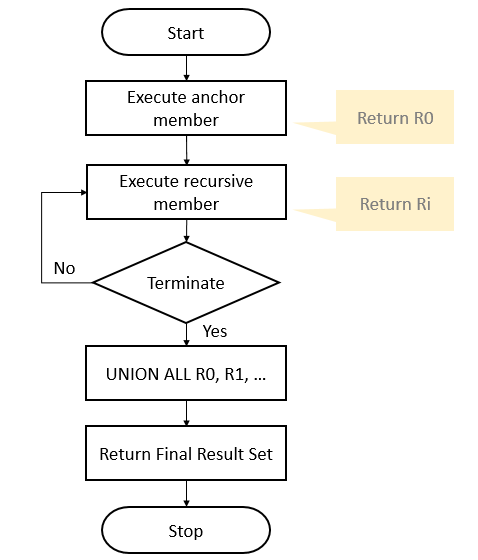
分析 https://zhuanlan.zhihu.com/p/372330656
R0 :
1 | SELECT UserID,ManagerID,Name,Name AS ManagerName |
| userid | managerid | name | managername |
|---|---|---|---|
| 1 | -1 | boss | boss |
R1:
1 | SELECT c.UserID,c.ManagerID,c.Name,p.Name AS ManagerName |
此时Employee为完整的,cte为
| userid | managerid | name | managername |
|---|---|---|---|
| 1 | -1 | boss | boss |
得到结果为
| c.userid | c.managerid | c.name | c.managername | p.userid | p.managerid | p.name | p.managername |
|---|---|---|---|---|---|---|---|
| 11 | 1 | A1 | A1 | 1 | -1 | boss | boss |
| 12 | 1 | A2 | A2 | 1 | -1 | boss | boss |
| 13 | 1 | A3 | A3 | 1 | -1 | boss | boss |
1 | SELECT c.UserID,c.ManagerID,c.Name,p.Name AS ManagerName |
| userid | managerid | name | name |
|---|---|---|---|
| 11 | 1 | A1 | boss |
| 12 | 1 | A2 | boss |
| 13 | 1 | A3 | boss |
R2,R3…
最后union all R0,R1,R2,。。。
1 | SELECT 1,-1,N'Boss' |
1 -1 Boss —字段
1 -1 Boss
11 1 A1
12 1 A2
13 1 A3
111 11 B1
112 11 B2
121 12 C1
Common Table Expression
with …as…
就是做了某些操作,自动触发的行为
触发器是自动执行的,当用户对表中数据作了某些操作之后立即被触发。
https://blog.csdn.net/weixin_48033173/article/details/111713117
https://blog.csdn.net/hguisu/article/details/5731629
https://www.analyticsvidhya.com/blog/2021/10/a-detailed-guide-on-sql-query-optimization/
https://blog.devart.com/how-to-optimize-sql-query.html#sql-query-optimization-basics
https://www.cnblogs.com/feiling/p/3393356.html
https://www.jianshu.com/p/03968ac9d8ad
https://blog.csdn.net/happyheng/article/details/53143345
https://www.runoob.com/mysql/mysql-index.html
https://blog.csdn.net/wangfeijiu/article/details/113409719
可以提高查询效率
和主键的区别,主键是特殊的索引,索引不一定是主键
https://blog.csdn.net/krismile__qh/article/details/98477484
https://blog.csdn.net/weixin_33375360/article/details/113371197
既然有主键为啥还要索引,关键在于这是两个东西,一个是为了唯一表示,一个是为了提高查询效率,底层也不同
https://cache.one/read/17347789
聚集索引与非聚集索引
http://c.biancheng.net/view/7366.html
1、创建索引
创建表时指定索引
1 | drop TABLE if EXISTS s1; |
创建表后
CREATE INDEX 索引名 ON 表名(列的列表);/ALTER TABLE 表名 ADD INDEX 索引名 (列名1,列名2,…);
在navicat也可以指定索引
2、删除索引
DROP INDEX index_name ON talbe_name
ALTER TABLE table_name DROP INDEX index_name
3、查看索引
SHOW INDEX FROM table_name;
4、使用索引
建立了索引,底层查询效率变高了
查询语句编写上和原来一样,没有区别
https://blog.csdn.net/lenux2017/article/details/80086265
https://www.cnblogs.com/technologykai/articles/14172224.html
https://blog.csdn.net/talentluke/article/details/6420197
http://m.biancheng.net/sql/create-view.html
视图为虚拟的表,包含的不是数据而是sql查询
视图和表的主要区别在于:
作用
使用视图的时候跟表一样
和cte的区别
https://blog.csdn.net/happyboy53/article/details/2731420
子查询包含的是数据,将数据存在内存,而视图包含的不是数据而是sql查询
SQL 语言层面的代码封装与重用
单行函数:单入单出
多行函数:多入单出,最常见的就是聚合函数
应该不存在单入多出,多入多出可以简化为单入单出的多次
https://blog.csdn.net/lailai186/article/details/12570899
注意:
多行,单行结果组合返回一行
例子:select column1 ,count(column2) ,只返回一行
问题来了,多多不一样呢,比如3和2,应该不存在
https://blog.csdn.net/qq_23833037/article/details/53170789
顾名思义,将数据聚集返回单一的值
https://blog.csdn.net/qq_40456829/article/details/83657396
https://segmentfault.com/a/1190000040088969
https://www.51cto.com/article/639541.html
https://blog.csdn.net/weixin_43412569/article/details/107992998
作用
行数保持不变
输入多行(一个窗口)、返回一个值
计算过程

当前行-》分区-》排序-》范围-》计算-》结果填入当前行
语法
1 | window_function ([expression]) OVER ( |
expression
PARTITION BY
表示将数据按 part_list 进行分区, 不加partition by 默认用全部(一个分区)
partition by columns1,columns2
ORDER BY
表示将各个分区内的数据按 order_list进行排序
ROWS / RANGE 决定数据范围
分类
https://www.cnblogs.com/52xf/p/4209211.html
可以分为以下 3 类:
AVG(), COUNT(), MIN(), MAX(), SUM()… 1 | sum(frequency) over(partiton by num ) --分组累加 |
https://blog.csdn.net/qq_54494937/article/details/119537881
https://leetcode-cn.com/problems/find-median-given-frequency-of-numbers/
https://blog.csdn.net/qq_54494937/article/details/119537881
取值(Value):FIRST_VALUE(), LAST_VALUE(), LEAD(), LAG()…
排序(Ranking):RANK(), DENSE_RANK(), ROW_NUMBER(), NTILE()…
1 | rank() OVER (PARTITION BY Id ORDER BY Month DESC) |
https://leetcode-cn.com/problems/find-cumulative-salary-of-an-employee/
https://blog.csdn.net/a_lllll/article/details/87880389
1 | select distinct C1.seat_id as seat_id |
1 | # Write your MySQL query statement below |
https://www.jianshu.com/p/3aa52ee3a802
https://blog.csdn.net/hjw199089/article/details/77938688
https://blog.csdn.net/mys_35088/article/details/80864092
https://blog.csdn.net/dmy1115143060/article/details/82620715
https://blog.csdn.net/xxd1992/article/details/85254666
https://blog.csdn.net/m0_46657040/article/details/108737350
https://blog.csdn.net/heiren_a/article/details/111954523
https://blog.csdn.net/u011564172/article/details/53611109
https://blog.csdn.net/qq_22473611/article/details/107822168
https://www.jianshu.com/p/3aa52ee3a802
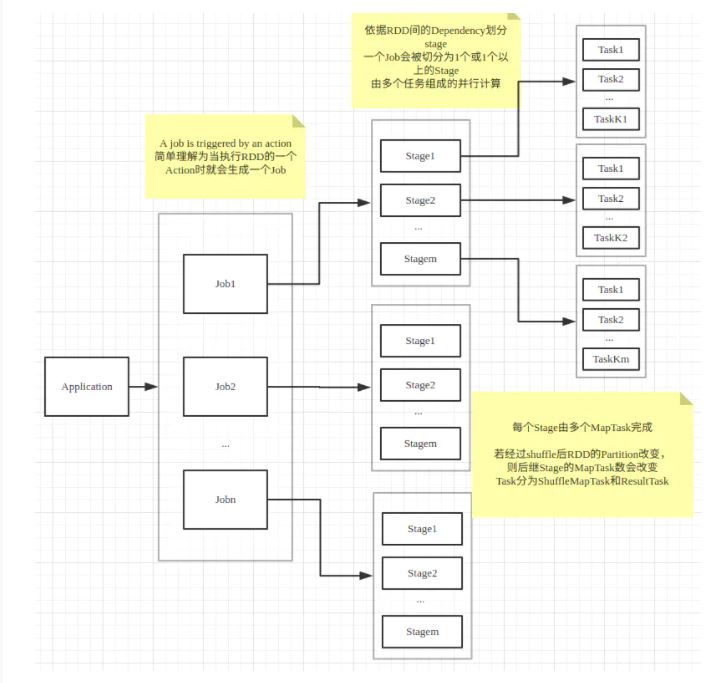
任务
一个action 一个job
一个job根据rdd的依赖关系构建dag,根据dag划分stage,一个job包含一个或者多个stage
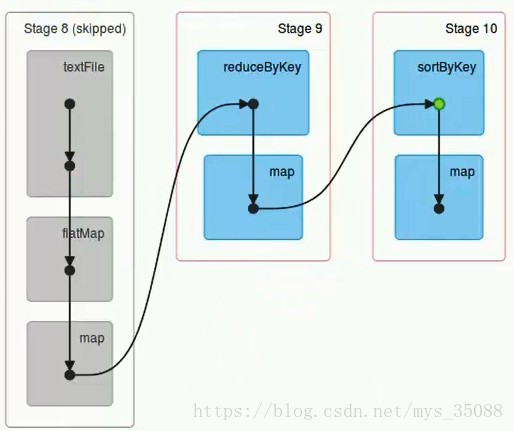
stage根据rdd的分区数决定task数量
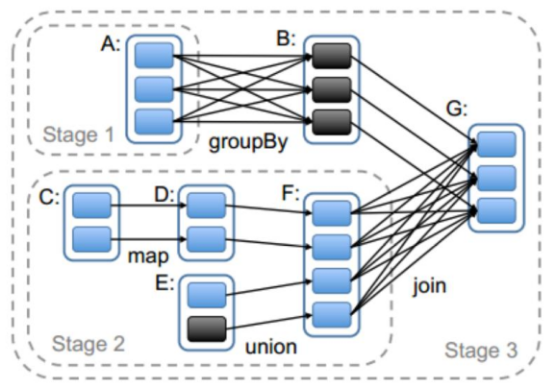
一个task 对应很多record,也就是多少行数据
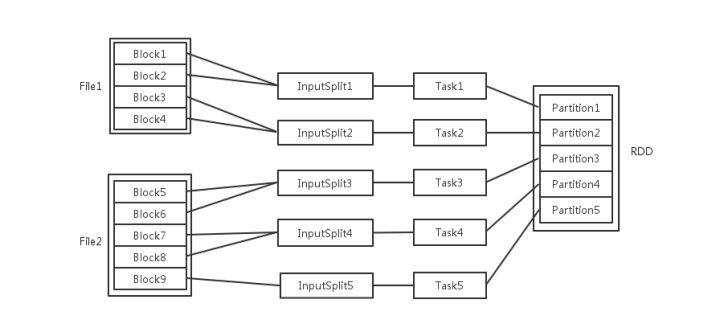
这里应该是 rdd的分区数决定task数量,task数量决定inputsplit数量,然后决定block的组合
https://juejin.cn/post/6844903848536965134
为什么分区?
分区的主要作用是用来实现并行计算,提高效率
分区方式
Spark包含两种数据分区方式:HashPartitioner(哈希分区)和RangePartitioner(范围分区)
分区数设置
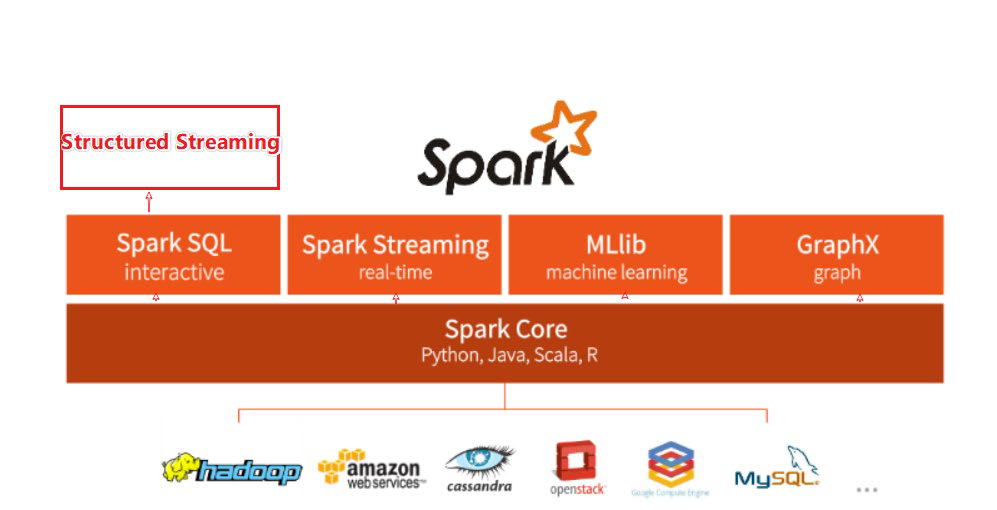
整个Spark 框架模块包含:Spark Core、Spark SQL、Spark Streaming、Spark GraphX、Spark MLlib,而后四项的能力都是建立在核心引擎之上
Spark Core:Spark的核心,Spark核心功能均由Spark Core模块提供,是Spark运行的基础。Spark Core以RDD为数据抽象,提供Python、Java、Scala、R语言的API,可以编程进行海量离线数据批处理计算。
SparkSQL:基于SparkCore之上,提供结构化数据的处理模块。SparkSQL支持以SQL语言对数据进行处理,SparkSQL本身针对离线计算场景。同时基于SparkSQL,Spark提供了StructuredStreaming模块,可以以SparkSQL为基础,进行数据的流式计算。
数据抽象:dataset(Java、Scala) dataframe(Java、Scala、Python、R)
SparkStreaming:以SparkCore为基础,提供数据的流式计算功能。
MLlib:以SparkCore为基础,进行机器学习计算,内置了大量的机器学习库和API算法等。方便用户以分布式计算的模式进行机器学习计算。
GraphX:以SparkCore为基础,进行图计算,提供了大量的图计算API,方便用于以分布式计算模式进行图计算。
https://www.educba.com/mapreduce-vs-spark/
| MapReduce | Spark | |
|---|---|---|
| Product’s Category | From the introduction, we understood that MapReduce enables the processing of data and hence is majorly a data processing engine. | Spark, on the other hand, is a framework that drives complete analytical solutions or applications and hence making it an obvious choice for data scientists to use this as a data analytics engine. |
| Framework’s Performance and Data Processing | In the case of MapReduce, reading and writing operations are performed from and to a disk thus leading to slowness in the processing speed. | In Spark, the number of read/write cycles is minimized along with storing data in memory allowing it to be 10 times faster. But spark may suffer a major degradation if data doesn’t fit in memory. |
| Latency | As a result of lesser performance than Spark, MapReduce has a higher latency in computing. | Since Spark is faster, it enables developers with low latency computing. |
| Manageability of framework | MapReduce being only a batch engine, other components must be handled separately yet synchronously thus making it difficult to manage. | Spark is a complete data analytics engine, has the capability to perform batch, interactive streaming, and similar component all under the same cluster umbrella and thus easier to manage! |
| Real-time Analysis | MapReduce was built mainly for batch processing and hence fails when used for real-time analytics use cases. | Data coming from real-time live streams like Facebook, Twitter, etc. can be efficiently managed and processed in Spark. |
| Interactive Mode | MapReduce doesn’t provide the gamut of having interactive mode. | In spark it is possible to process the data interactively |
| Security | MapReduce has accessibility to all features of Hadoop security and as a result of this, it is can be easily integrated with other projects of Hadoop Security. MapReduce also supports ASLs. | In Spark, the security is by default set to OFF which might lead to a major security fallback. In the case of authentication, only the shared secret password method is possible in Spark. |
| Tolerance to Failure | In case of crash of MapReduce process, the process is capable of starting from the place where it was left off earlier as it relies on Hard Drives rather than RAMs | In case of crash of Spark process, the processing should start from the beginning and hence becomes less fault-tolerant than MapReduce as it relies of RAM usage. |
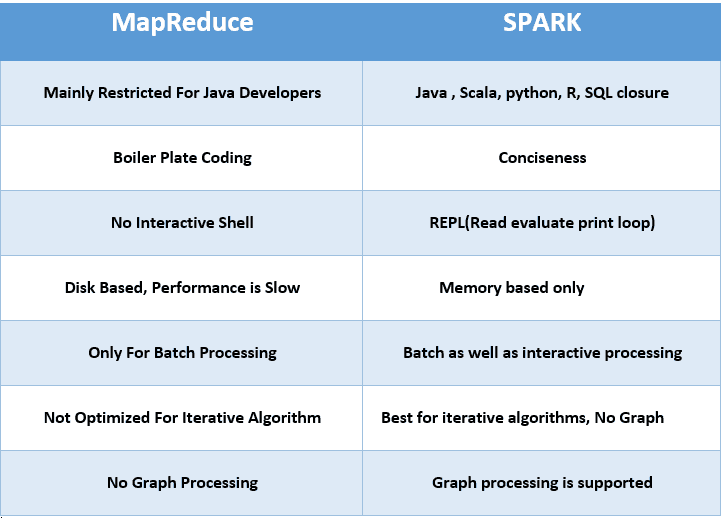
https://blog.csdn.net/JENREY/article/details/84873874
1 spark基于内存 ,mapreduce基于磁盘
指的是中间结果
MapReduce:通常需要将计算的中间结果写入磁盘,然后还要读取磁盘,从而导致了频繁的磁盘IO
Spark:不需要每次将计算的中间结果写入磁盘
2 spark粗粒度资源申请,MapReduce细粒度资源申请
spark 执行task不需要自己申请资源,提交任务的时候统一申请了
MapReduce 执行task任务的时候,task自己申请
3 spark基于多线程,mapreduce基于多进程
https://blog.51cto.com/u_16213328/7866422
优先级

hadoop设置???
https://blog.csdn.net/weixin_43648241/article/details/108917865
SparkSession > SparkContext > HiveContext > SQLContext
SparkSession包含SparkContext
SparkContext包含HiveContext
HiveContext包含SQLContext
1 | SparkSession.builder.\ |
1 非实时 支持从 HDFS、HBase、Hive、ES、MongoDB、MySQL、PostgreSQL、AWS、Ali Cloud 等不同的存储系统、大数据库、关系型数据库中读入和写出数据
2 在实时流计算中可以从 Flume、Kafka 等多种数据源获取数据并执行流式计算。
https://spark.apache.org/docs/latest/submitting-applications.html
The spark-submit script in Spark’s bin directory is used to launch applications on a cluster. It can use all of Spark’s supported cluster managers through a uniform interface so you don’t have to configure your application especially for each one.
1 | ./bin/spark-submit \ |
--class: The entry point for your application (e.g. org.apache.spark.examples.SparkPi)--master: The master URL for the cluster (e.g. spark://23.195.26.187:7077)--deploy-mode: Whether to deploy your driver on the worker nodes (cluster) or locally as an external client (client) (default: client) †--conf: Arbitrary Spark configuration property in key=value format. For values that contain spaces wrap “key=value” in quotes (as shown). Multiple configurations should be passed as separate arguments. (e.g. --conf = --conf =)application-jar: Path to a bundled jar including your application and all dependencies. The URL must be globally visible inside of your cluster, for instance, an hdfs:// path or a file:// path that is present on all nodes.application-arguments: Arguments passed to the main method of your main class, if any当前为客户端,driver在哪取决于deploy mode
应该只能local和client
此时若是代码指定cluster会报错
1 | config("spark.submit.deployMode", "cluster") |
Exception in thread “main” org.apache.spark.SparkException: Cluster deploy mode is not applicable to Spark shells.
应该只能local和clien