常见关系型数据库:
- Oracle
- MySql
- Microsoft SQL Server
- SQLite
- PostgreSQL
- IBM DB2
常见的非关系型数据库:
- 键值数据库:Redis、Memcached、Riak
- 列族数据库:Bigtable、HBase、Cassandra
- 文档数据库:MongoDB、CouchDB、MarkLogic
- 图形数据库:Neo4j、InfoGrid
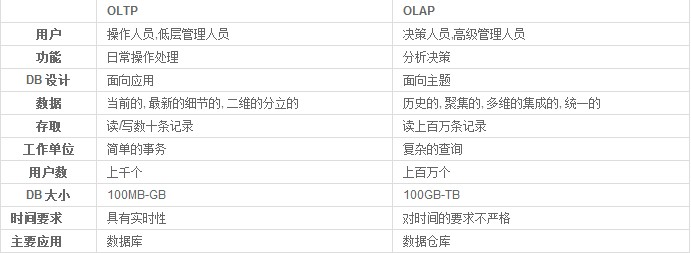
二者区别
非关系型没有表结构,不支持sql
常见关系型数据库:
常见的非关系型数据库:
二者区别
非关系型没有表结构,不支持sql
主键、外键
https://blog.csdn.net/weixin_31642161/article/details/113113942
有可能没有主键
联合主键,复合主键
联合主键:数据库表的主键由两个及以上的字段组成。
复合主键:有争议
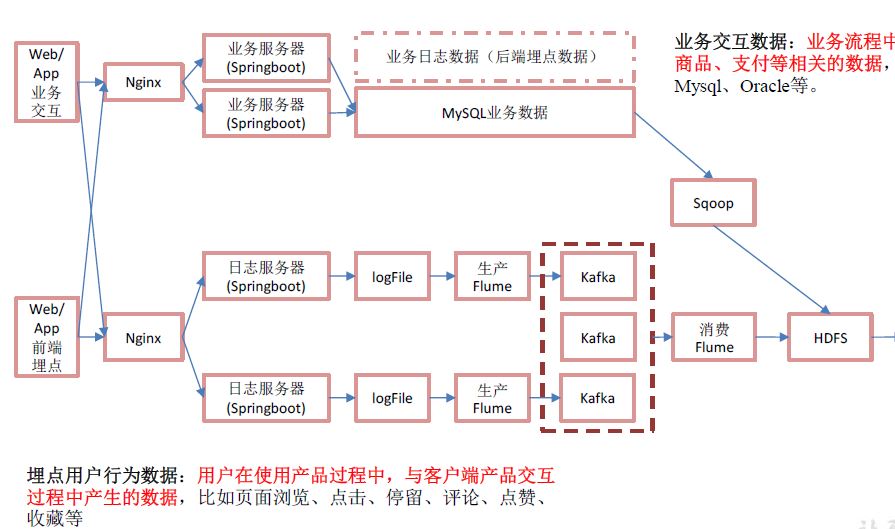
jar-》log-》flume-》kafka-》flume-》hdfs
用户行为数据存储在日志服务器,以.log文件存在,log-》flume-》kafka-》flume-》hdfs
jar-》mysql-》sqoop-》hdfs
业务数据存储在mysql,使用sqoop导入hdfs
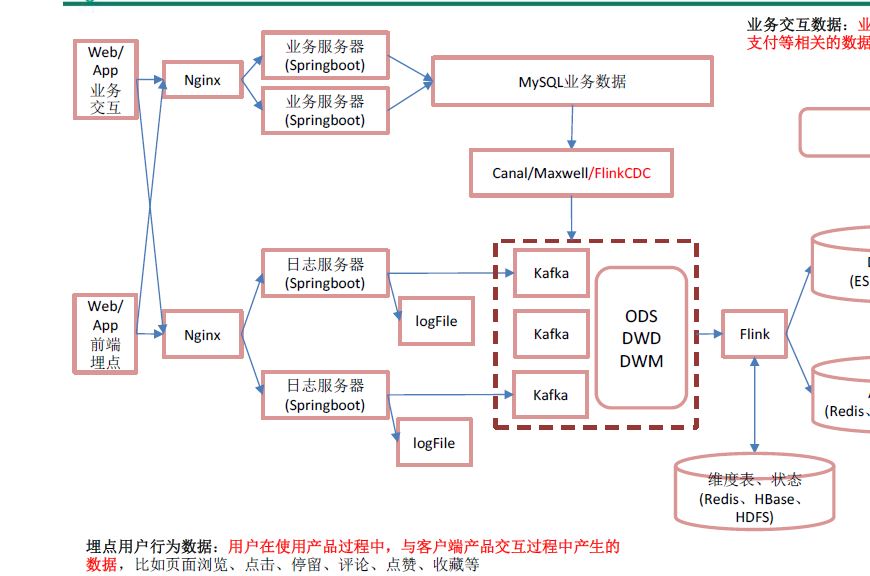
前端-》Nginx-》日志服务器-》)log,Kafka(ods
1 前端埋点数据
通过jar包模拟
2 Nginx
https://blog.csdn.net/qq_40036754/article/details/102463099
负载均衡
3 日志服务器
spring boot搭建
首先,Spring 就是一个java框架,spring boot在 Spring 的基础上演进
4 落盘,整合 Kafka
落盘指的是存在日志服务器
生产者-》kafka-》消费者
生产 消费
jar-》mysql-》flinkcdc-》kafka(ods)
不能使用sqoop,因为sqoop底层为mapreduce,太慢了,改用canal,maxwell或者flinkcdc
数据从mysql读到kafka,不是hdfs
flink-cdc
https://cloud.tencent.com/developer/article/1801766
Change Data Capture(变更数据获取)
https://www.cnblogs.com/yjd_hycf_space/p/7772722.html
https://blog.csdn.net/qq_33269009/article/details/90522087
https://blog.csdn.net/Stubborn_Cow/article/details/48420997
注意:很多人理解的ETL是在经过前两个部分之后,加载到数据仓库的数据库中就完事了。ETL不仅仅是在源数据—>ODS这一步,ODS—>DW, DW—>DM包含更为重要和复杂的ETL过程。
https://cwiki.apache.org/confluence/display/hive/design#Design-HiveArchitecture
https://zhuanlan.zhihu.com/p/87545980
https://blog.csdn.net/oTengYue/article/details/91129850
https://jiamaoxiang.top/2020/06/27/Hive%E7%9A%84%E6%9E%B6%E6%9E%84%E5%89%96%E6%9E%90/
https://www.javatpoint.com/hive-architecture
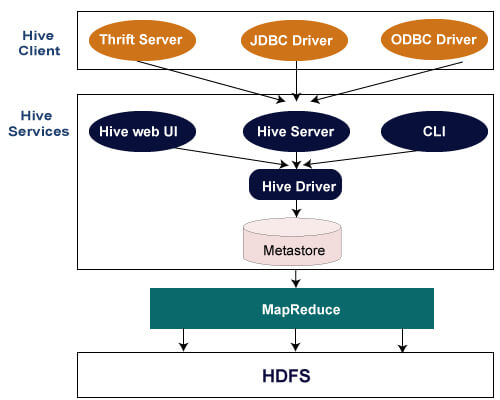
Hive allows writing applications in various languages, including Java, Python, and C++. It supports different types of clients such as:-
The following are the services provided by Hive:-
Hive支持MapReduce、Tez、Spark
https://cloud.tencent.com/developer/article/1893808
https://blog.csdn.net/kwu_ganymede/article/details/52223133
https://cloud.tencent.com/developer/article/1411821
Hive是基于hdfs的,它的数据存储在Hadoop分布式文件系统中。Hive本身是没有专门的数据存储格式,也没有为数据建立索引,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,Hive就可以解析数据。
default数据库中的表的存储位置 /user/hive/warehouse
其他数据库的表自己指定
The Challenges of Data Quality and Data Quality Assessment in the Big Data Era
https://pdfs.semanticscholar.org/0fb3/7330a4170ec63d60eec7dbb2b86e6829a3de.pdf
A Data Quality in Use model for Big Data
Automating LargeScale Data Quality Verification
Data Sets and Data Quality in Software Engineering
Discovering Data Quality Rules
Context-aware Data Quality Assessment for Big Data