Kerberos
1.定义
Kerberos是一种计算机网络认证协议,用来在非安全网络中,对个人通信以安全的手段进行身份认证。这个词又指麻省理工学院为这个协议开发的一套计算机软件。软件设计上采用客户端/服务器结构,并且能够进行相互认证,即客户端和服务器端均可对对方进行身份认证。可以用于防止窃听、防止重放攻击、保护数据完整性等场合,是一种应用对称密钥体制进行密钥管理的系统。
1)KDC(Key Distribute Center):密钥分发中心,负责存储用户信息,管理发放票据。
2)Realm:Kerberos所管理的一个领域或范围。
3)Rrincipal:可以理解为Kerberos中保存的一个账号,其格式通常如下:primary/instance@realm
4)keytab:密钥文件。
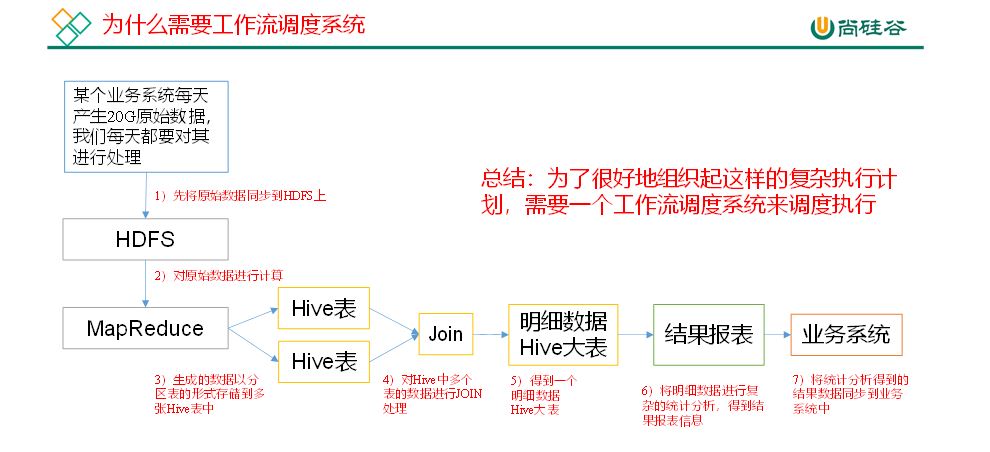
有个疑问 ,对谁认证?是对不同用户吗(root,user1,user2)?
2.认证原理
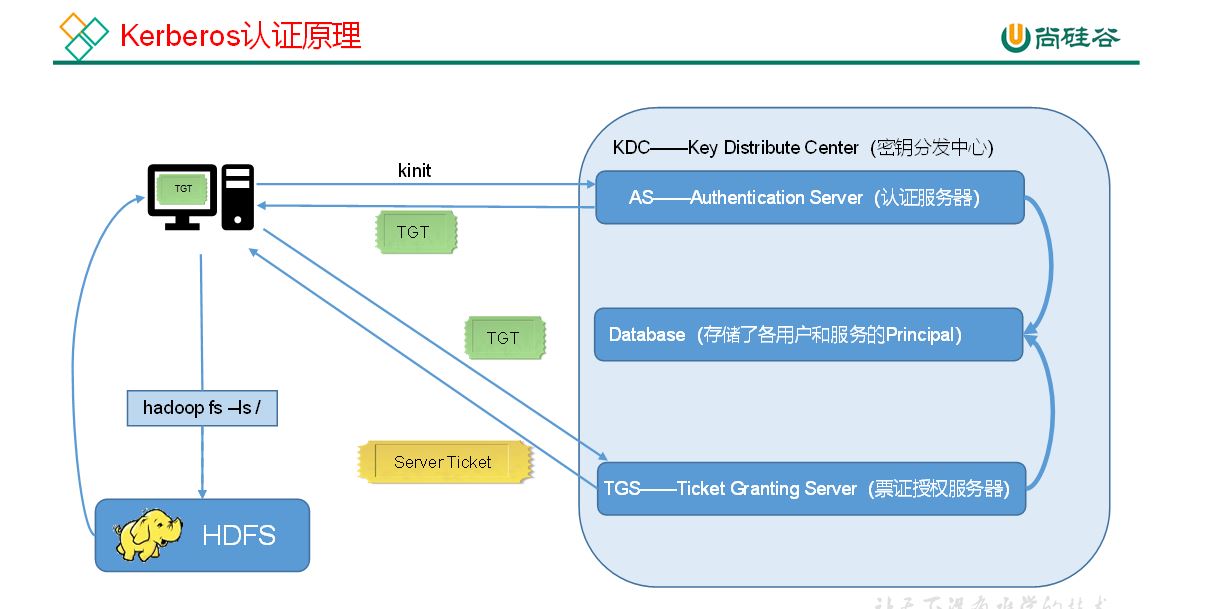
https://cloud.tencent.com/developer/article/1496451
https://blog.csdn.net/jewes/article/details/20792021
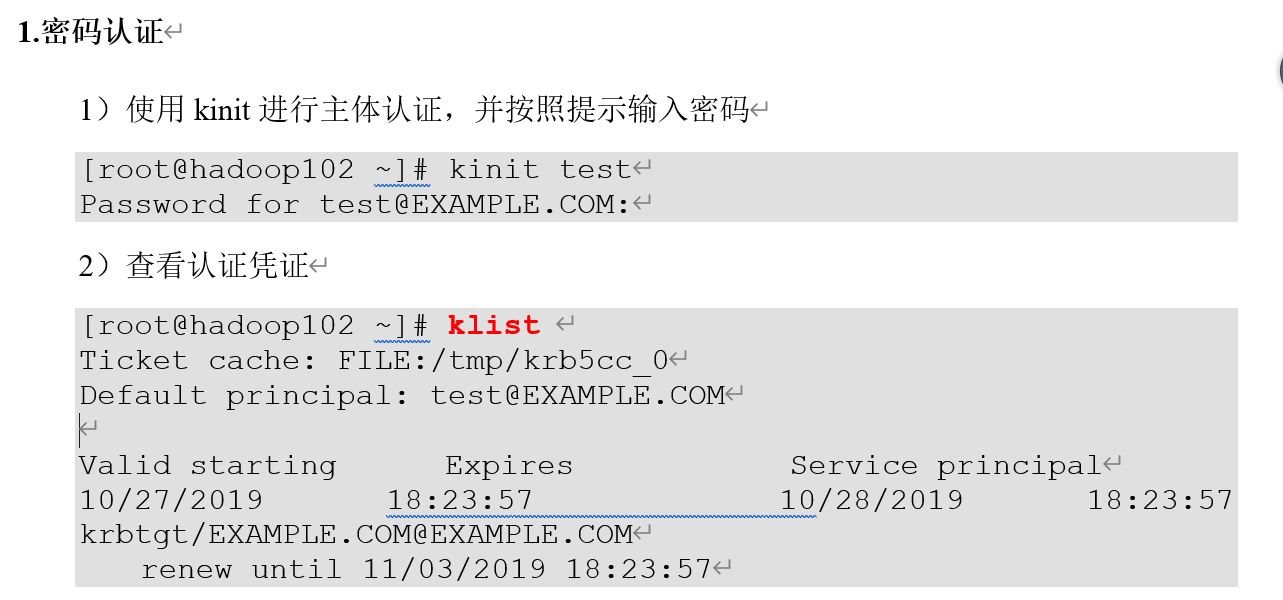
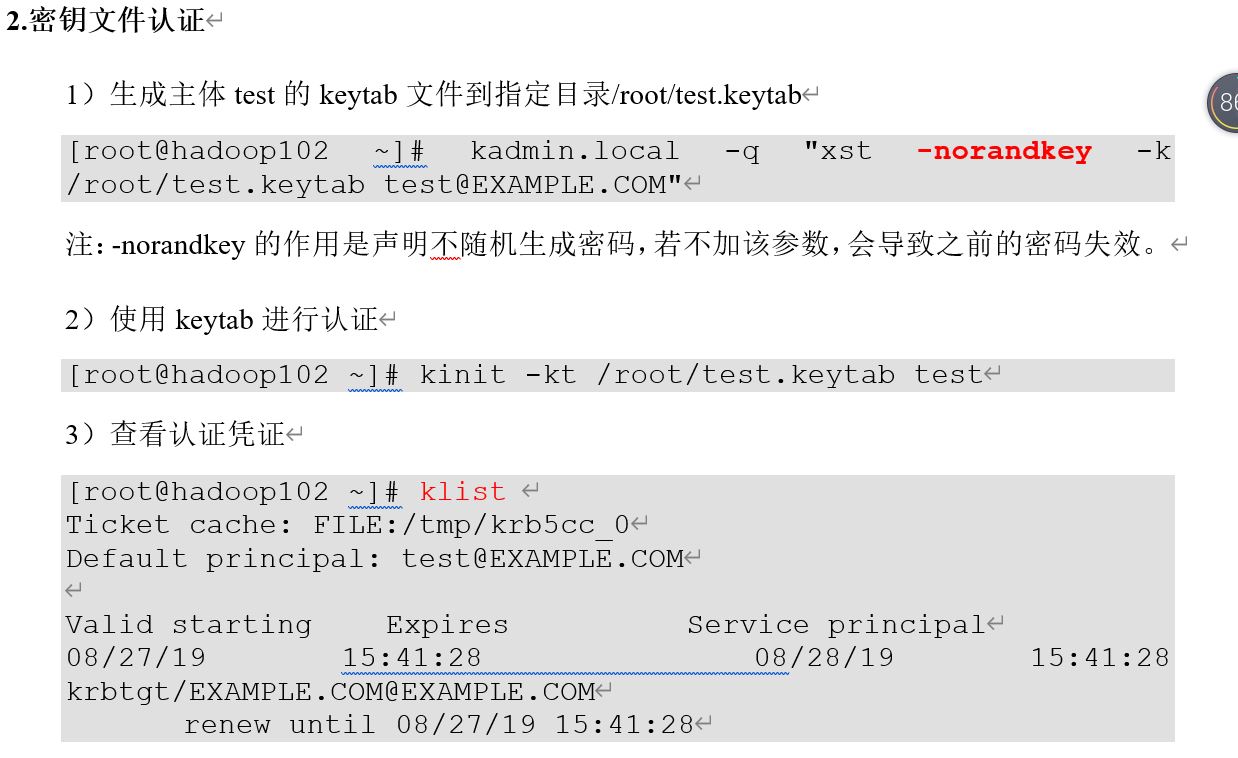
3.基本操作
https://blog.csdn.net/Happy_Sunshine_Boy/article/details/102801386
1 创建管理员用户

2 注册

3 认证

4.HADOOP
配置
https://www.cnblogs.com/yjt1993/p/11769515.html
https://makeling.github.io/bigdata/39395030.html
访问HDFS集群文件
Shell命令
kinit admin/admin
klist
web页面
1.安装Kerberos客户端
2.配置火狐浏览器
3.认证
5.HIVE
配置
https://zhuanlan.zhihu.com/p/137424234
客服端访问
beeline
0.首先需使用hive用户启动hiveserver2
[root@hadoop102 ~]# sudo -i -u hive hiveserver2
1.认证,执行以下命令,并按照提示输入密码
[atguigu@hadoop102 ~]$ kinit atguigu
2.使用beeline客户端连接hiveserver2
[atguigu@hadoop102 ~]$ beeline
3.使用如下url进行连接
1
!connect jdbc:hive2://hadoop102:10000/;principal=hive/hadoop102@EXAMPLE.COM
DataGrip客户端
https://blog.csdn.net/github_39319229/article/details/112692897
经常连接不稳定,连接失败可以尝试重启DataGrip
6.数仓
此处统一将数仓的全部数据资源的所有者设为hive用户,全流程的每步操作均认证为hive用户。
7.即席查询
8.spark
https://www.cnblogs.com/bainianminguo/p/12639887.html
9 hbase
1 hbase shell kerberos认证错误
1 | root:kinit atguigu |