离线数仓搭建例子(电商为例)
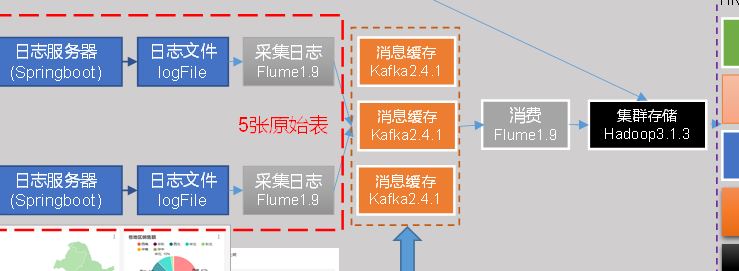
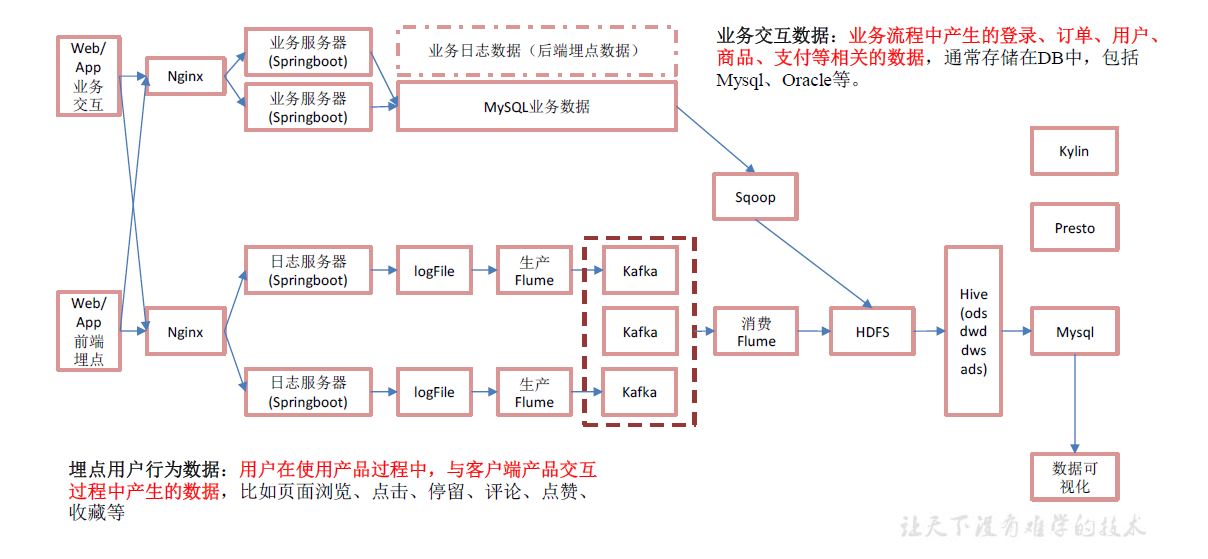
0 架构
1.数据来源
1.1 用户行为数据
用户在使用产品过程中,通过埋点收集与客户端产品交互过程中产生的数据,并发往日志服务器进行保存。比如页面浏览、点击、停留、评论、点赞、收藏等。用户行为数据通常存储在日志文件中。
我们的日志结构大致可分为两类,一是普通页面埋点日志,二是启动日志。
普通页面日志结构如下,每条日志包含了,当前页面的页面信息,所有事件(动作)、所有曝光信息以及错误信息。除此之外,还包含了一系列公共信息,包括设备信息,地理位置,应用信息等,即下边的common字段。
启动日志结构相对简单,主要包含公共信息,启动信息和错误信息。
1.2 业务数据
就是各行业在处理事务过程中产生的数据。比如用户在电商网站中登录、下单、支付等过程中,需要和网站后台数据库进行增删改查交互,产生的数据就是业务数据。业务数据通常存储在MySQL、Oracle等数据库中。
总共47张表,选了27张业务表
2 数据采集
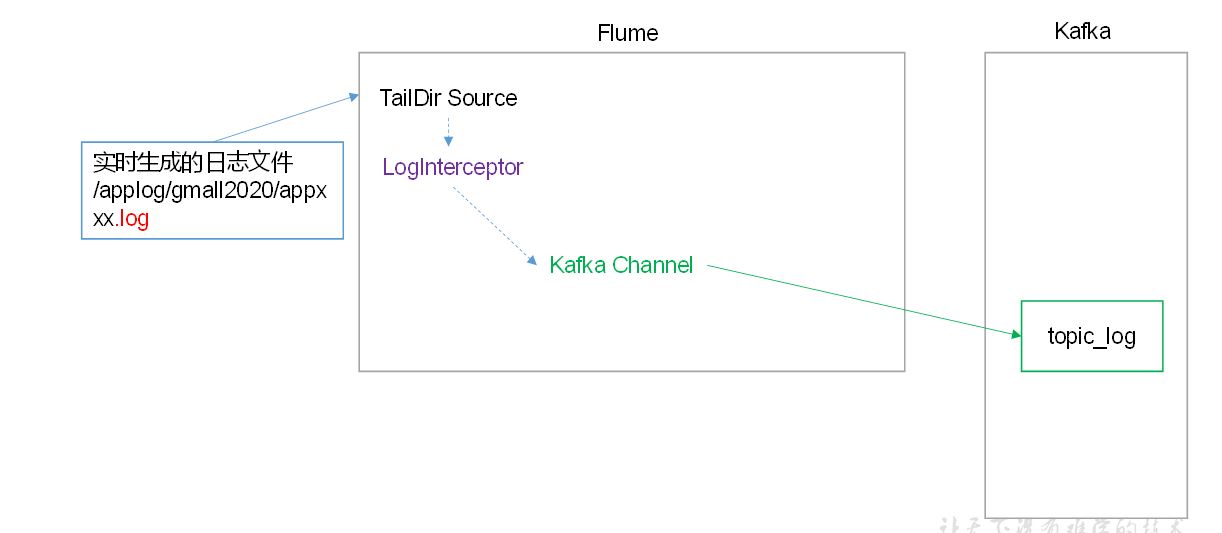
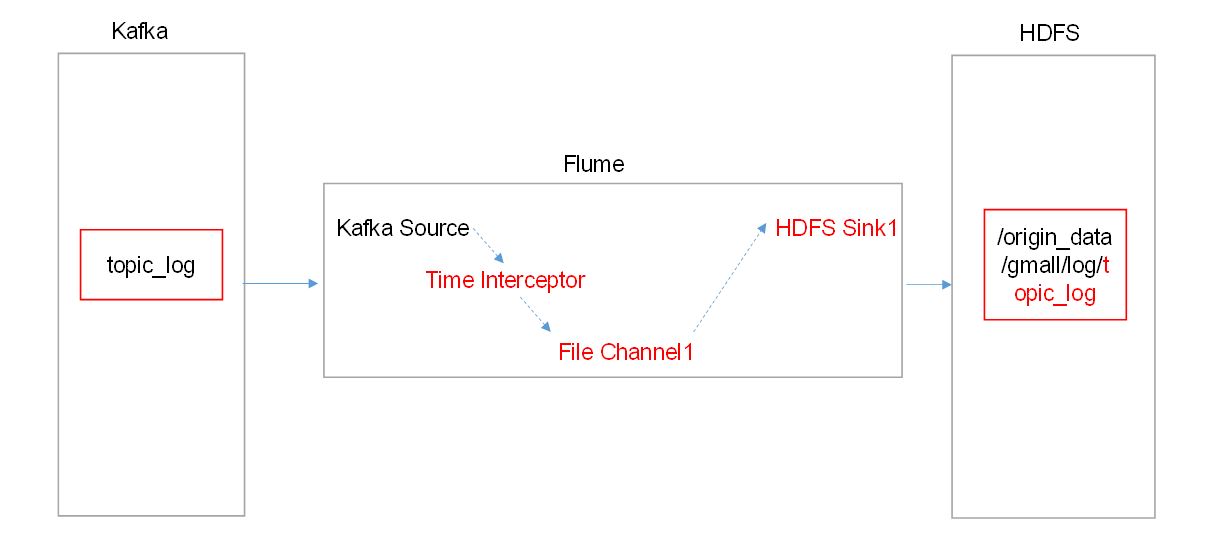
1 用户行为数据
jar-》log(日志服务器)-》flume-》kafka-》flume-》hdfs
2 业务数据
jar-》mysql-》sqoop-》hdfs
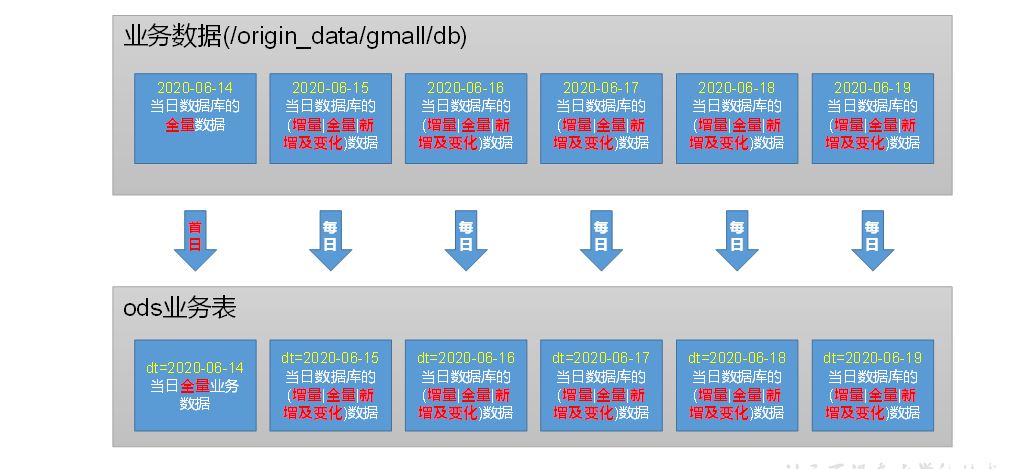
3.ODS
hdfs(ori)-》hdfs(ods)
1 用户行为数据
1张表,topic_log -> ods_log
a.建表
就一个字段”line“
b 分区
首日,每日都是全量
c .数据装载
2 业务数据
27张表
0 整体
b 同步

c .数据装载
1.活动信息表
activity_info -> ods_activity_info
a 建表
少了个“activity_desc”,多了”dt”

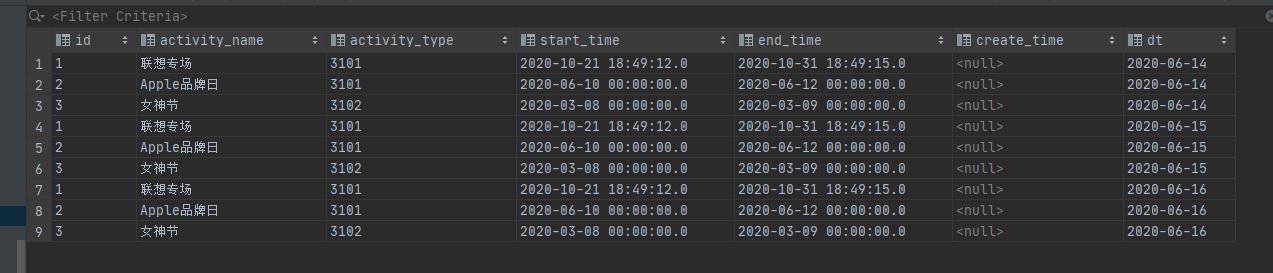
b 同步
首日,每日都是全量
c .数据装载
4.DIM
hdfs(ods)-》hdfs(dim)
构建6张维度表
1 商品维度表
a 建表
b 分区
首日,每日都是全量
c 数据装载
2 优惠券维度表
3 活动维度表
4 地区维度表
b 分区
地区维度表数据相对稳定,变化概率较低,故无需每日装载,首日全量
5 时间维度表
b 分区
通常情况下,时间维度表的数据并不是来自于业务系统,而是手动写入,并且时间维度表数据具有可预见性,无须每日导入,一般首日可一次性导入一年的数据
c 数据装载
1)创建临时表tmp_dim_date_info
2)将数据文件上传到HFDS上临时表指定路径/warehouse/gmall/tmp/tmp_dim_date_info/
3)执行以下语句将其导入时间维度表
1 | insert overwrite table dim_date_info select * from tmp_dim_date_info; |
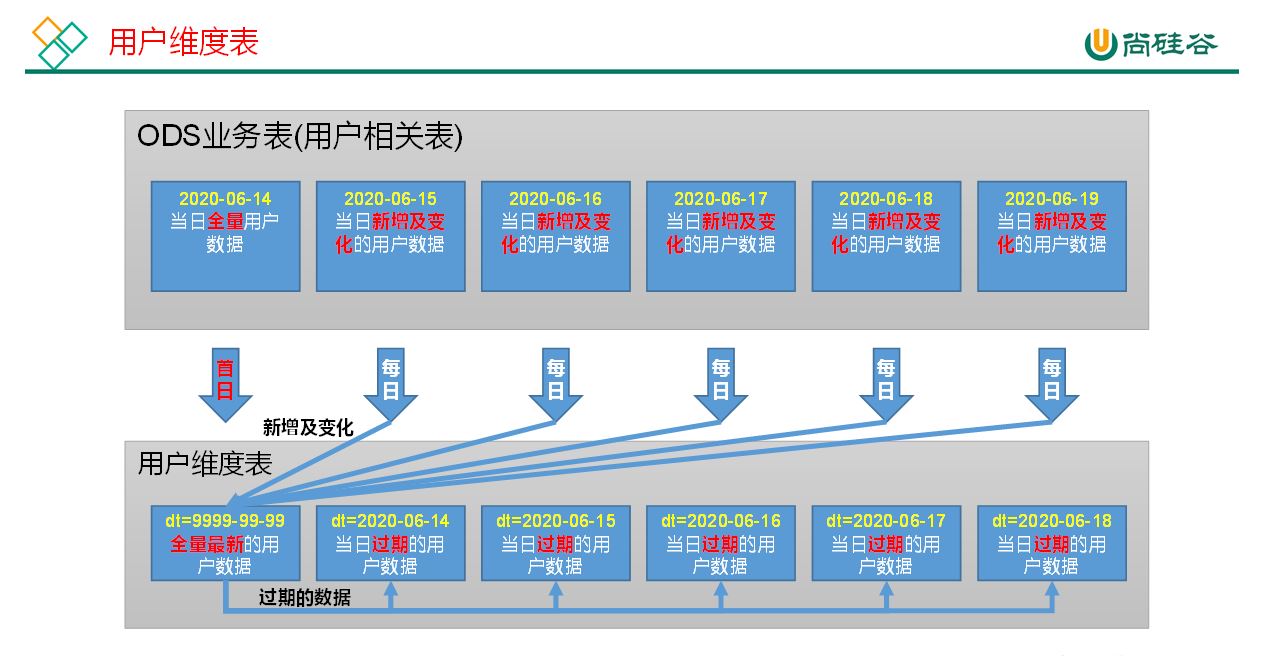
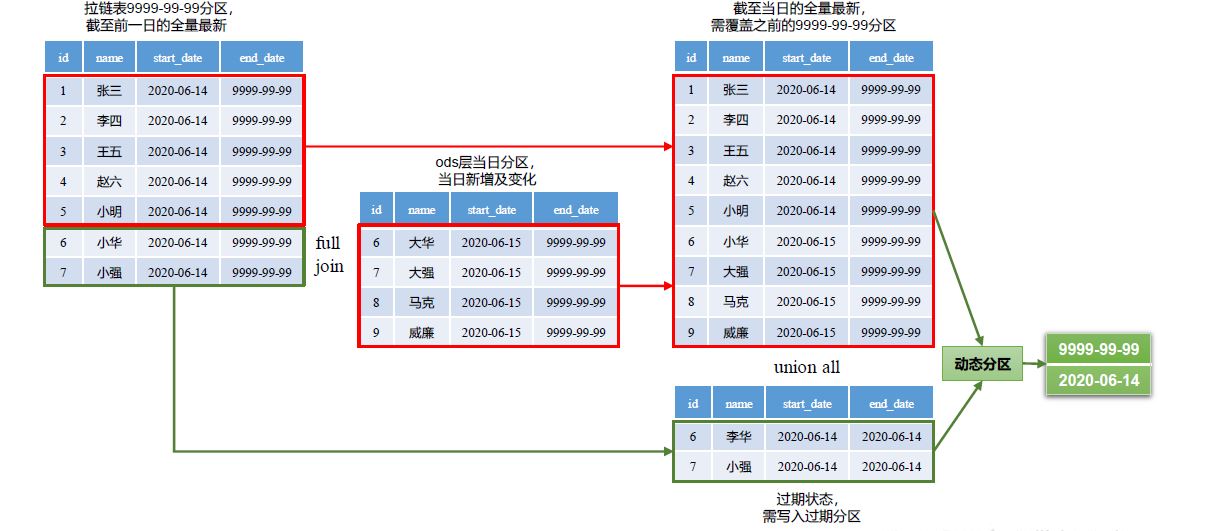
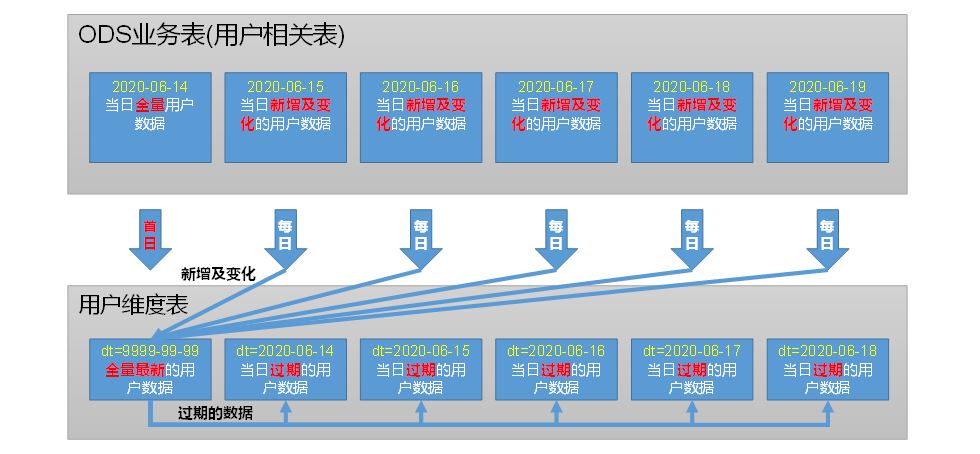
6 用户维度表
b 分区
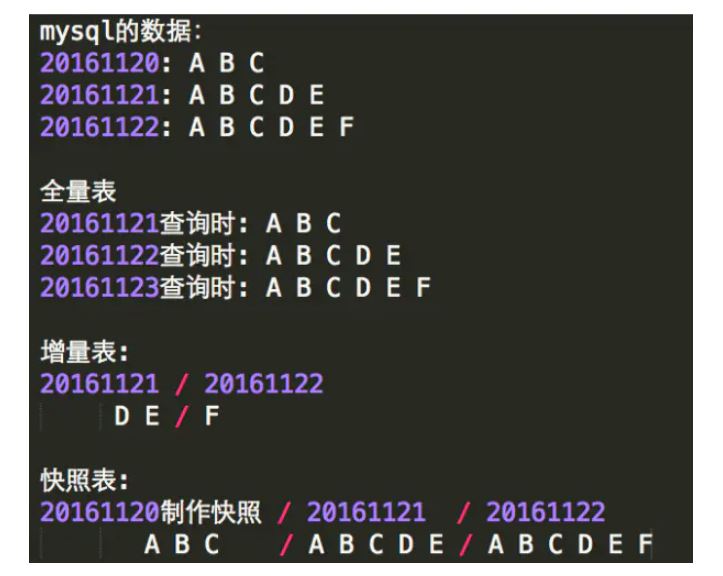
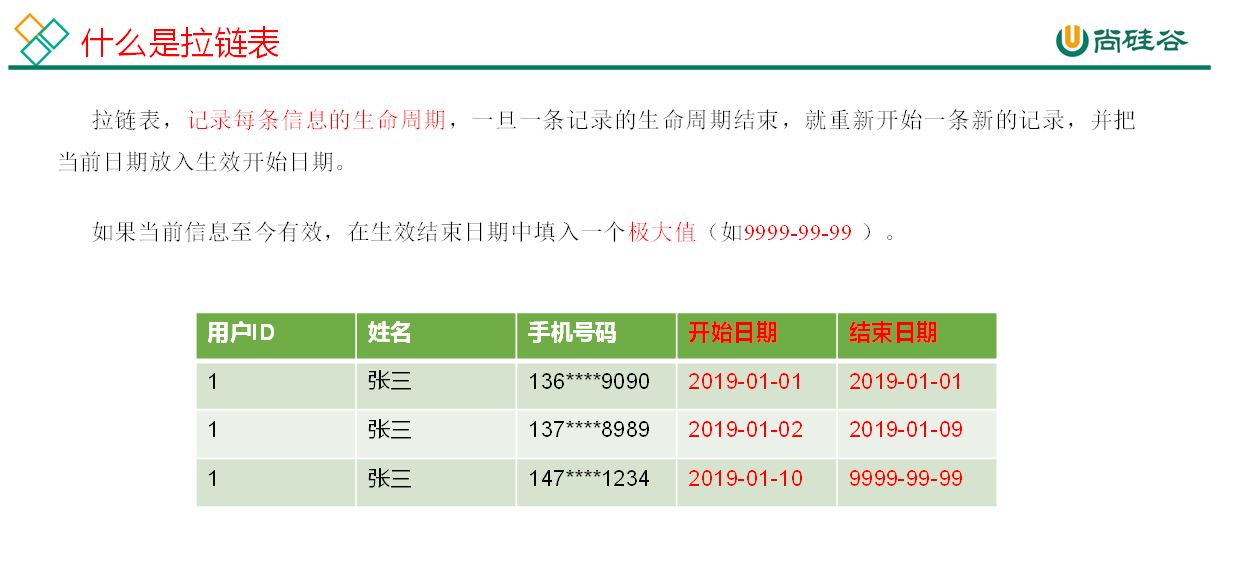
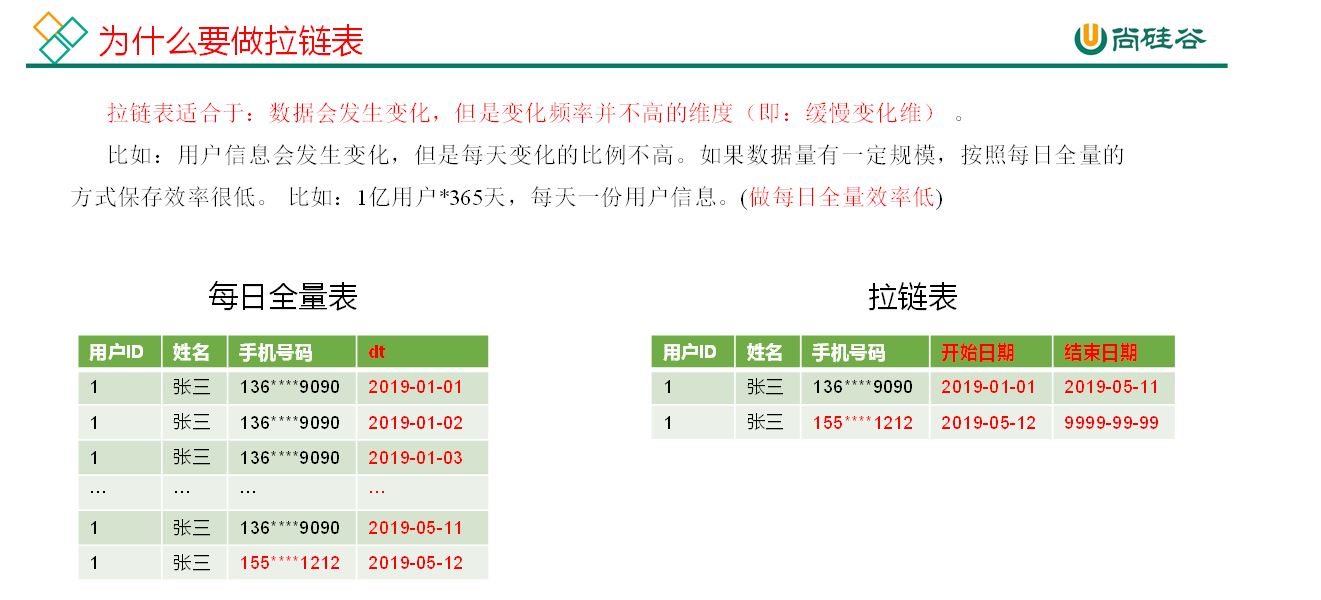
拉链表
https://cloud.tencent.com/developer/article/1752848#

c 数据装载
5.DWD
hdfs(ods)-》hdfs(dwd)
1 用户行为日志
0 日志数据拆解
ods_log由两部分构成,分别为页面日志和启动日志,拆解成5张表
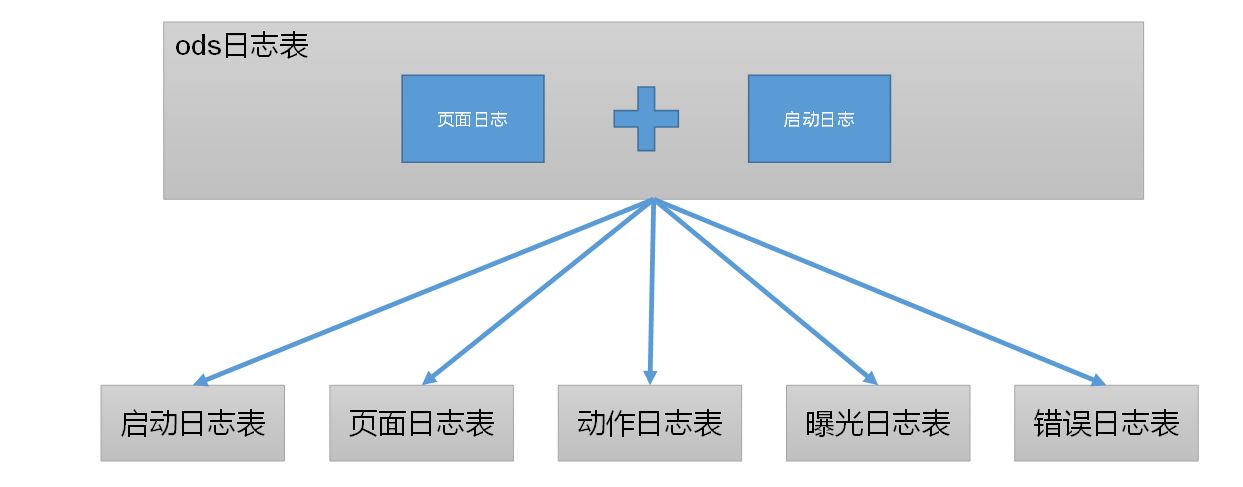
1 启动日志表
b 分区
首日,每日全量
c 数据装载

2 页面日志表
3 动作日志表
4 曝光日志表
5 错误日志表
2 业务数据
1 评价事实表(事务型事实表)
b 分区

c 数据装载
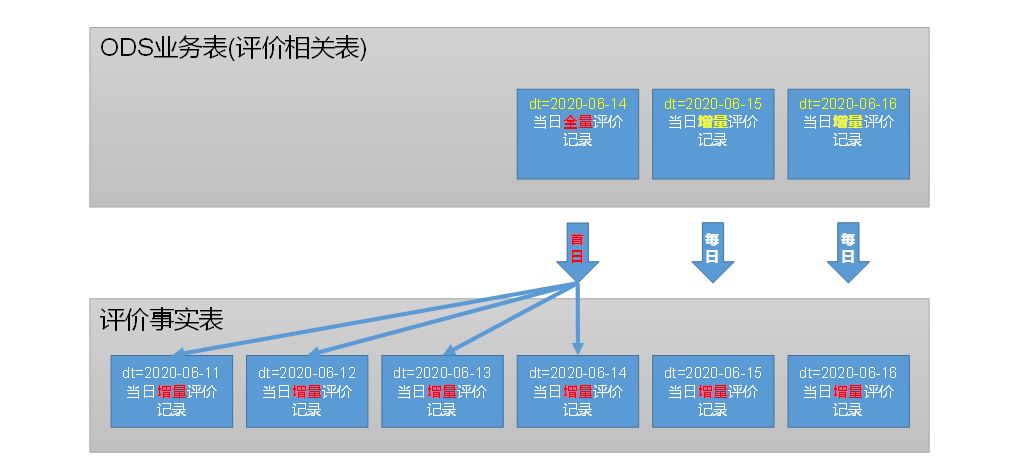
首日,动态分区;每日,静态分区
2 订单明细事实表(事务型事实表)
3 退单事实表(事务型事实表)
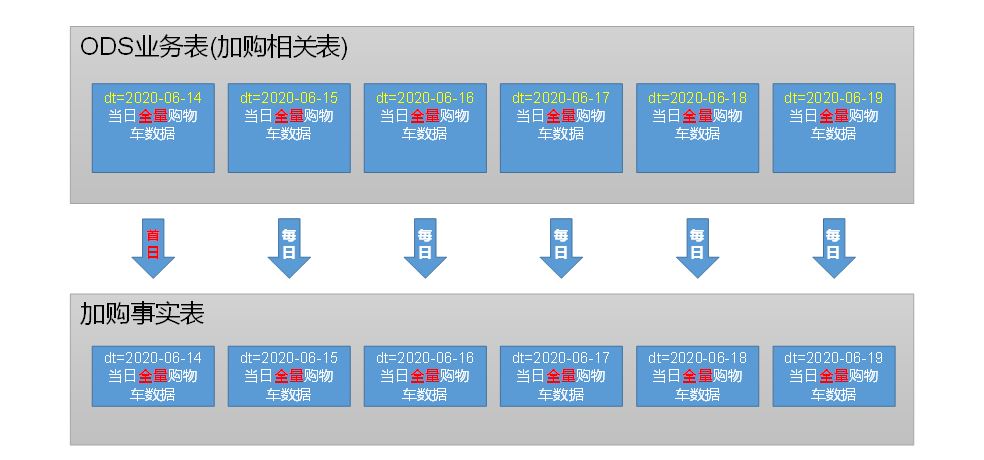
4 加购事实表(周期型快照事实表)
b 分区

c 数据加载
5 收藏事实表(周期型快照事实表)
6 优惠券领用事实表(累积型快照事实表)
b 分区

c 数据加载
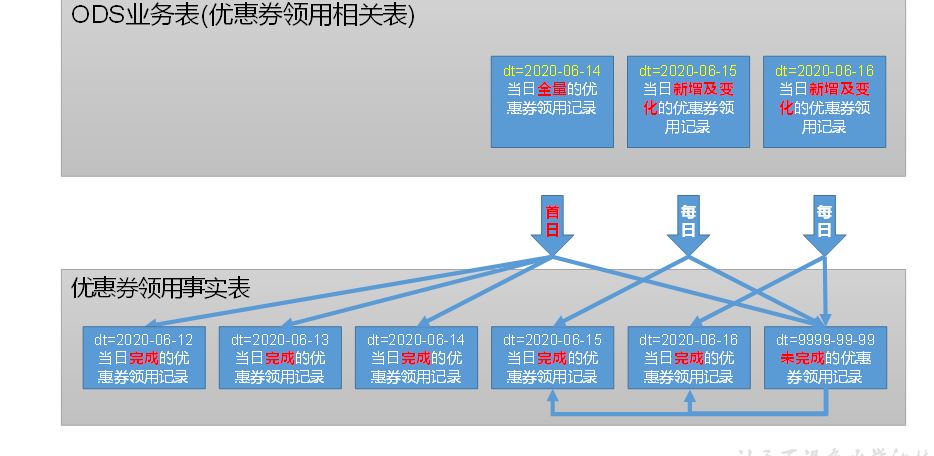
(1)首日
1 | insert overwrite table dwd_coupon_use partition(dt) |
(2)每日
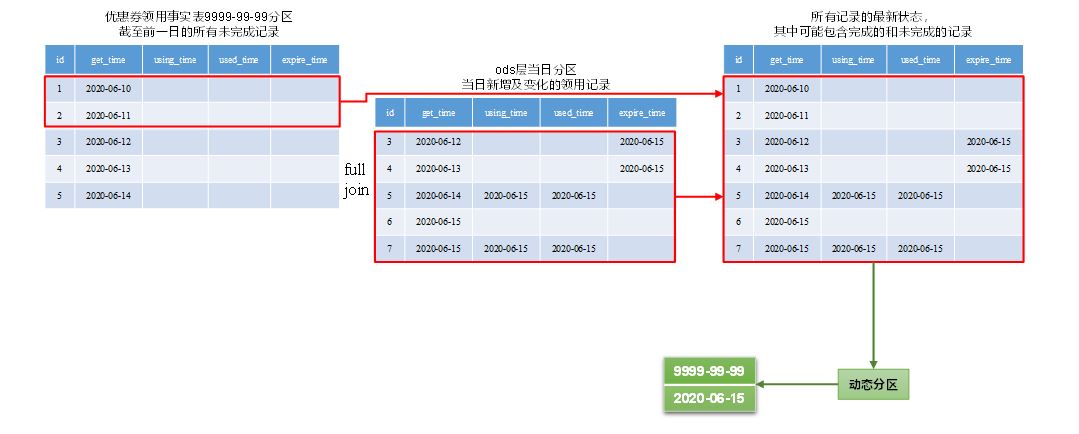
7 支付事实表(累积型快照事实表)
8 退款事实表(累积型快照事实表)
9 订单事实表(累积型快照事实表)
6.DWS
hdfs(dwd)-》hdfs(dws)
0 整体
b 分区

c 数据装载
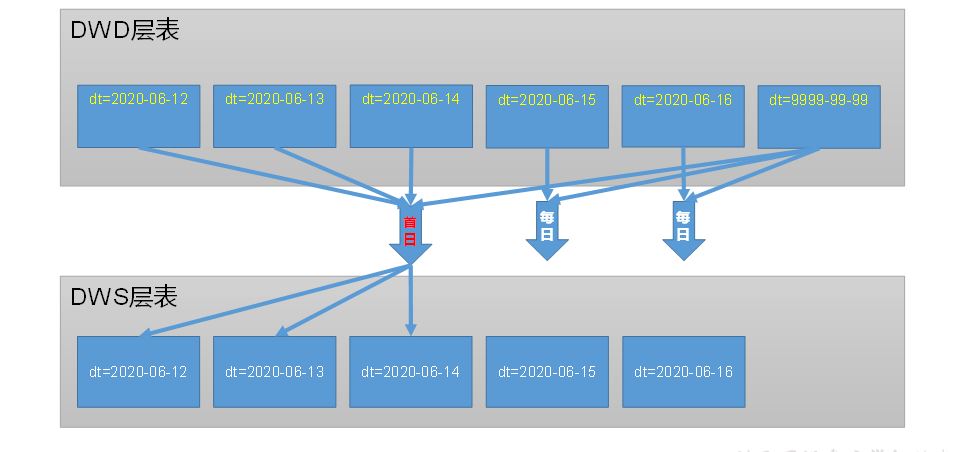
1 访客主题
2 用户主题
3 商品主题
4 优惠券主题
5 活动主题
6 地区主题
7.DWT
hdfs(dws)-》hdfs(DWT)
0 整体
c 数据装载
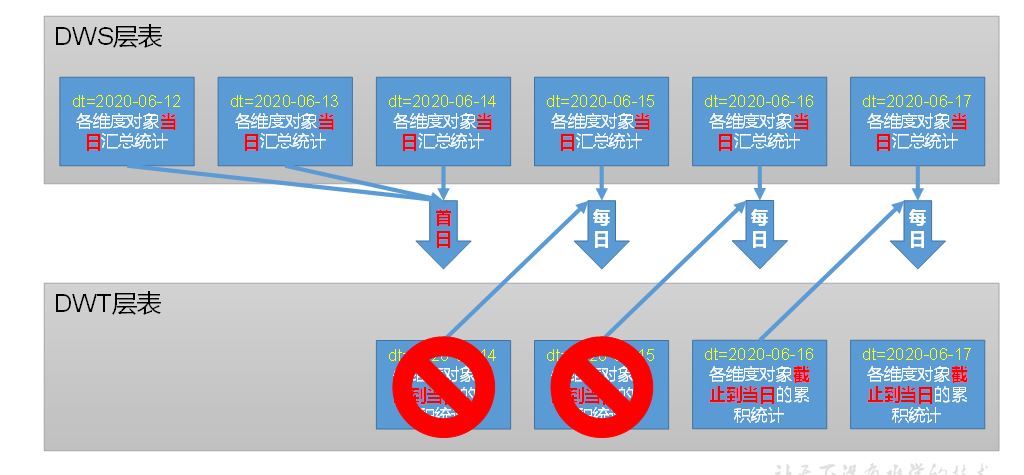
只保留当天和前一天的分区,过时的需要清理掉i
1 访客主题
2 用户主题
3 商品主题
4 优惠券主题
5 活动主题
6 地区主题
8.ADS
hdfs(DWT)-》hdfs(ADS)-》mysql
1 访客主题
1 访客统计
a 建表
| 指标 | 说明 | 对应字段 |
|---|---|---|
| 访客数 | 统计访问人数 | uv_count |
| 页面停留时长 | 统计所有页面访问记录总时长,以秒为单位 | duration_sec |
| 平均页面停留时长 | 统计每个会话平均停留时长,以秒为单位 | avg_duration_sec |
| 页面浏览总数 | 统计所有页面访问记录总数 | page_count |
| 平均页面浏览数 | 统计每个会话平均浏览页面数 | avg_page_count |
| 会话总数 | 统计会话总数 | sv_count |
| 跳出数 | 统计只浏览一个页面的会话个数 | bounce_count |
| 跳出率 | 只有一个页面的会话的比例 | bounce_rate |
b 分区
c 数据装载
第一步:对所有页面访问记录进行会话的划分。
第二步:统计每个会话的浏览时长和浏览页面数。
第三步:统计上述各指标。
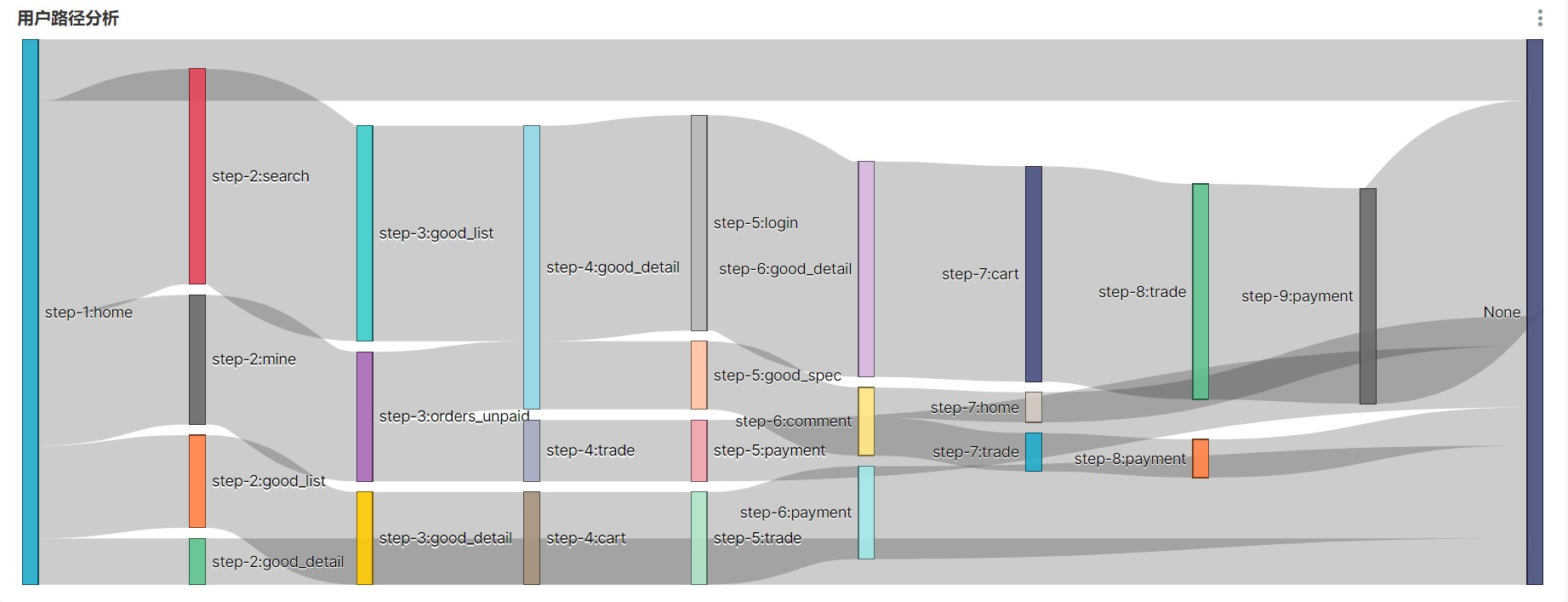
2 路径分析
用户访问路径的可视化通常使用桑基图
2 用户主题
3 商品主题
4 订单主题
5 优惠券主题
6 活动主题
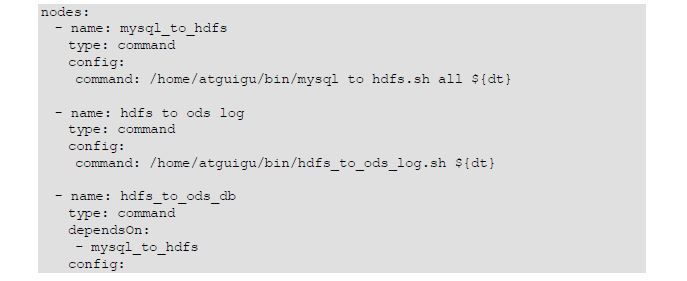
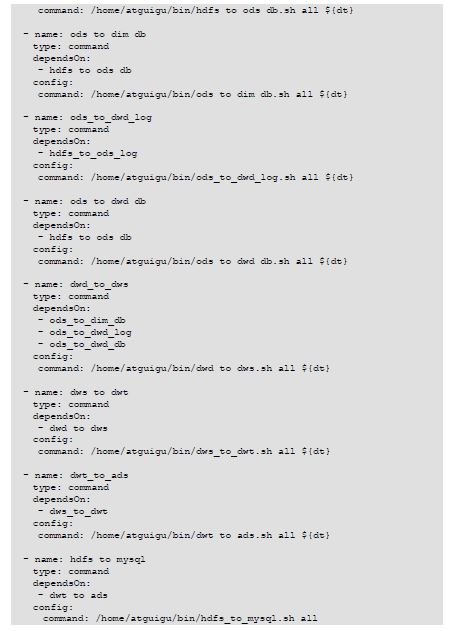
9.Azkaban全流程调度
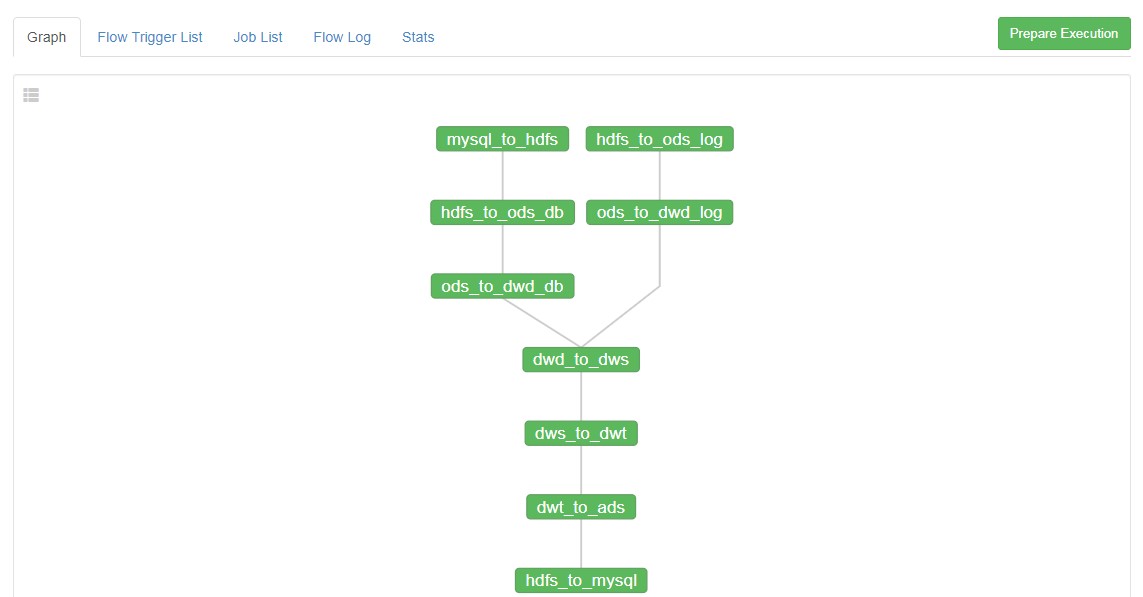
就是将原来写的脚本文件串起来