hadoop架构
1 总览
https://blog.csdn.net/wangxudongx/article/details/104079998
2 hdfs
3 yarn
4 MapReduce
5 RPC
Remote Procdure Call,中文名:远程过程调用
它允许一台计算机程序远程调用另外一台计算机的子程序,而不用去关心底层的网络通信细节
Hadoop的进程间交互都是通过RPC来进行的,比如Namenode与Datanode
https://blog.csdn.net/wangxudongx/article/details/104079998
Remote Procdure Call,中文名:远程过程调用
它允许一台计算机程序远程调用另外一台计算机的子程序,而不用去关心底层的网络通信细节
Hadoop的进程间交互都是通过RPC来进行的,比如Namenode与Datanode
https://blog.csdn.net/aohun0743/article/details/101702331
https://cloud.tencent.com/developer/article/1924241?from=article.detail.1336692
单机运行,只是用来演示一下官方案例。生产环境不用。
也是单机运行,但是具备Hadoop集群的所有功能,一台服务器模拟一个分布式的环境。个别缺钱的公司用来测试,生产环境不用。
多台服务器组成分布式环境。生产环境使用。
搭建:
https://blog.csdn.net/a1786742005/article/details/104104983
HA高可用是Hadoop2.x才开始引入的机制,是为了解决Hadoop的单点故障问题。主要有两种部署方式,一种是NFS(Network File System)方式,另外一种是QJM(Quorum Journal Manager)方式。用得较多的是QJM方式,稳定性更好。实际操作中,生产环境的Hadoop集群搭建一般都会做HA部署。
配置客户端访问集群
https://blog.knoldus.com/spark-rdd-vs-dataframes/
https://blog.csdn.net/hellozhxy/article/details/82660610
https://www.cnblogs.com/lestatzhang/p/10611320.html#Spark_16
https://www.jianshu.com/p/77811ae29fdd
https://zhuanlan.zhihu.com/p/379578271
https://spark.apache.org/docs/3.2.0/sql-programming-guide.html#content
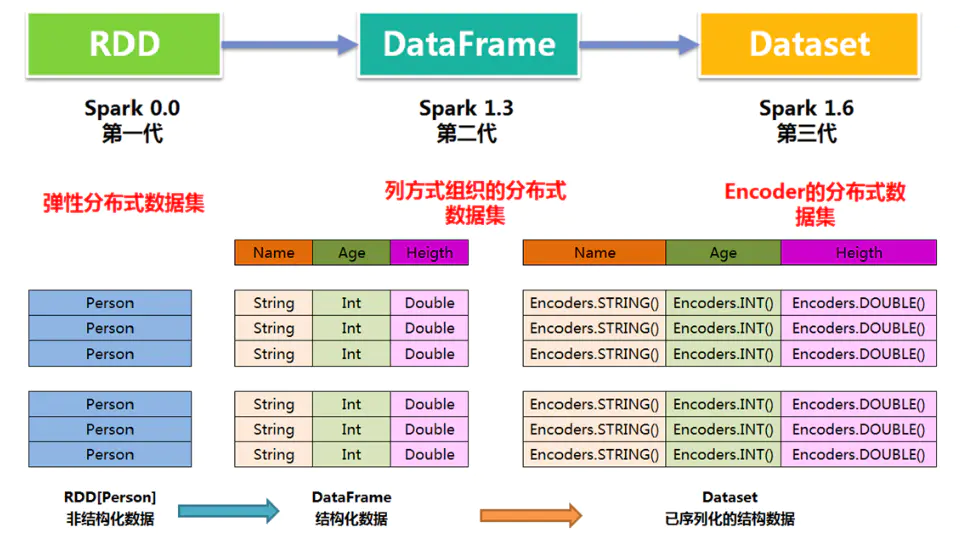
DataFrame 和 RDDs 最主要的区别在于一个面向的是结构化数据,一个面向的是非结构化数据
1.相比DataFrame,Dataset提供了编译时类型检查,对于分布式程序来讲,提交一次作业太费劲了(要编译、打包、上传、运行),到提交到集群运行时才发现错误,实在是想骂人,这也是引入Dataset的一个重要原因。
2.RDD转换DataFrame后不可逆,但RDD转换Dataset是可逆的(这也是Dataset产生的原因)
注意:
The Dataset API is available in Scala and Java. Python does not have the support for the Dataset API. But due to Python’s dynamic nature, many of the benefits of the Dataset API are already available (i.e. you can access the field of a row by name naturally row.columnName).
关系建模和维度建模是两种数据仓库的建模技术。关系建模由Bill Inmon所倡导,维度建模由Ralph Kimball所倡导。目前主流为维度建模。
https://zhuanlan.zhihu.com/p/362991213
1 目的
降低数据的冗余性
2 目前业界范式
第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)、第五范式(5NF)。逐个遵循,一般要求遵循第一,第二,第三范式,也就是三范式。
https://blog.csdn.net/Dream_angel_Z/article/details/45175621
1 建模
关系建模将复杂的数据抽象为两个概念——实体和关系(实体表,关系表),并使用规范化(三范式)的方式表示出来
2 特点
关系模型严格遵循第三范式(3NF),数据冗余程度低,数据的一致性容易得到保证。
由于数据分布于众多的表中,查询会相对复杂,在大数据的场景下,查询效率相对较低。
https://www.jianshu.com/p/daab50a23c56
https://cloud.tencent.com/developer/article/1772027
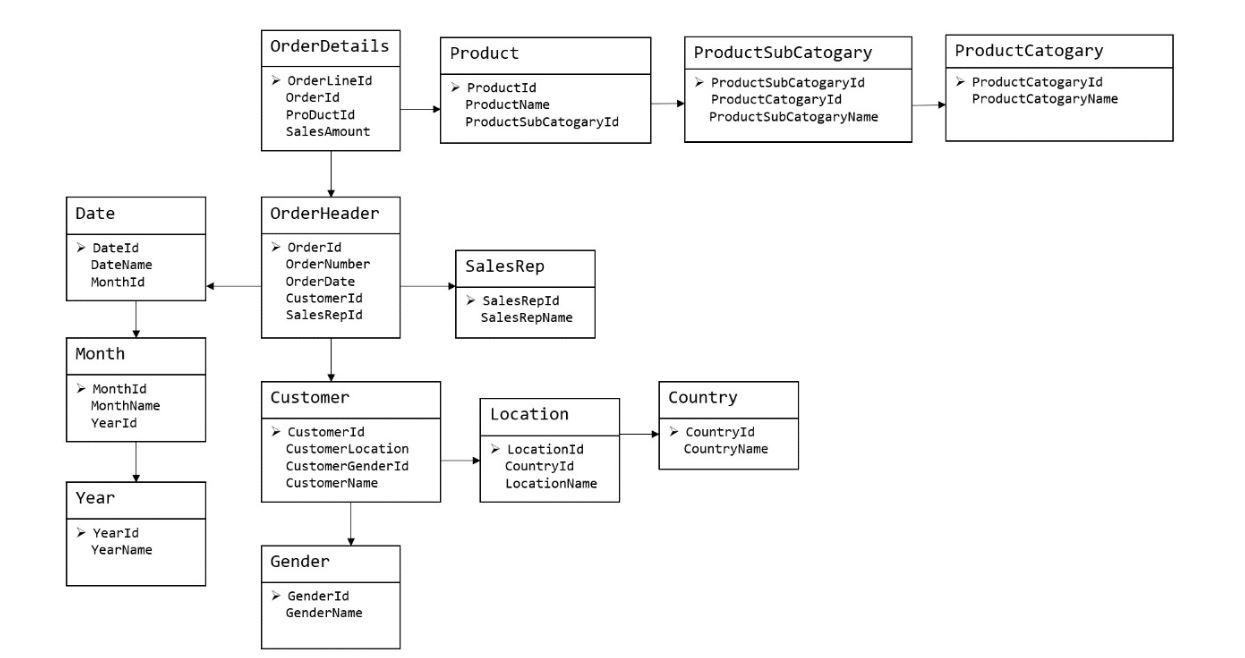
1 事实表
存储业务事实,事实表中的每行数据代表一个业务事件(下单、支付、退款、评价等)。
事实表的特征:
内容相对的窄:列数较少(主要是外键id和度量值)
非常的大
经常发生变化,每天会新增加很多。
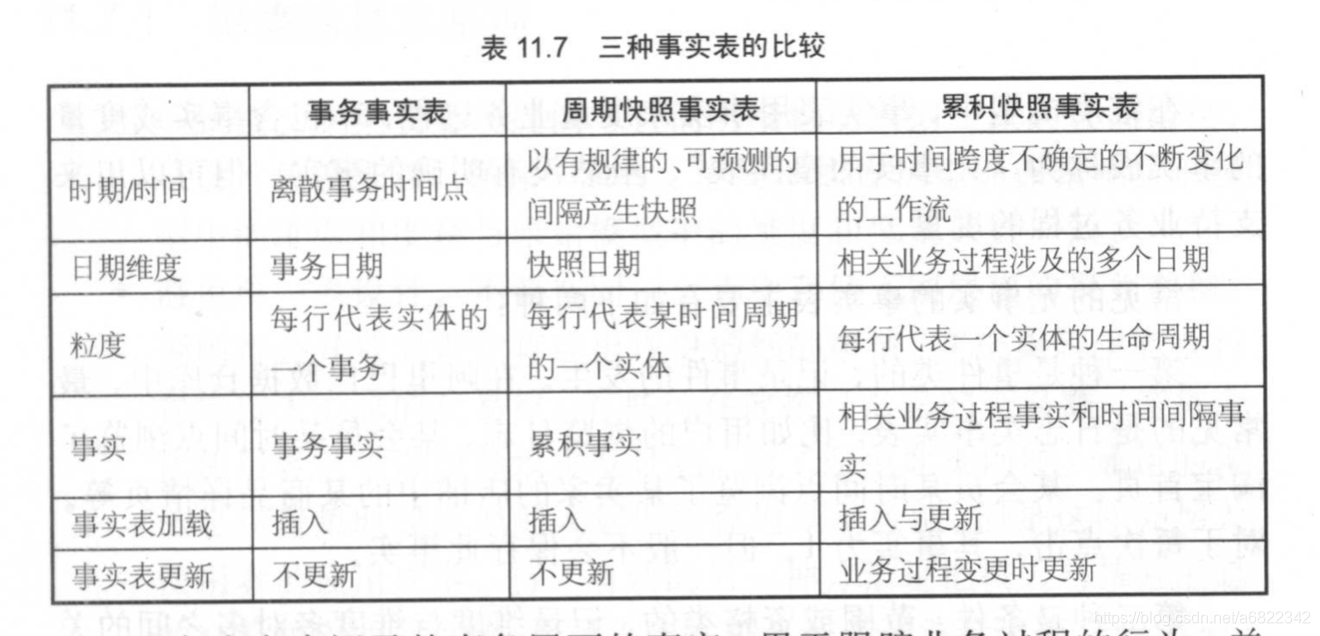
分类:事务型事实表,周期型快照事实表,累积型快照事实表
2 维度表
维度表:一般是对事实的描述信息。每一张维表对应现实世界中的一个对象或者概念。 例如:用户、商品、日期、地区等。
维表的特征:
维表的范围很宽(具有多个属性、列比较多)
跟事实表相比,行数相对较小:通常< 10万条
内容相对固定:编码表
在维度建模的基础上又分为三种模型:星型模型、雪花模型、星座模型。
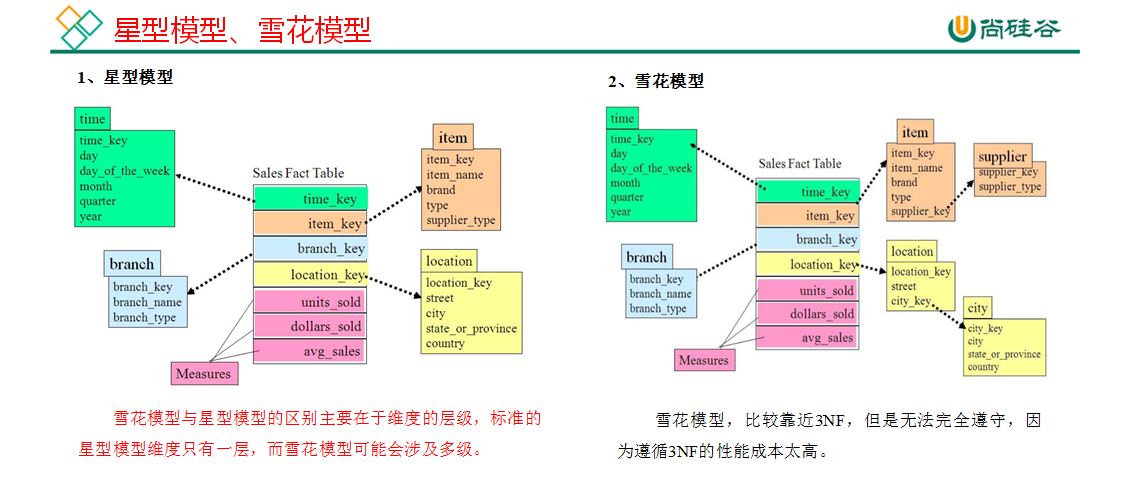
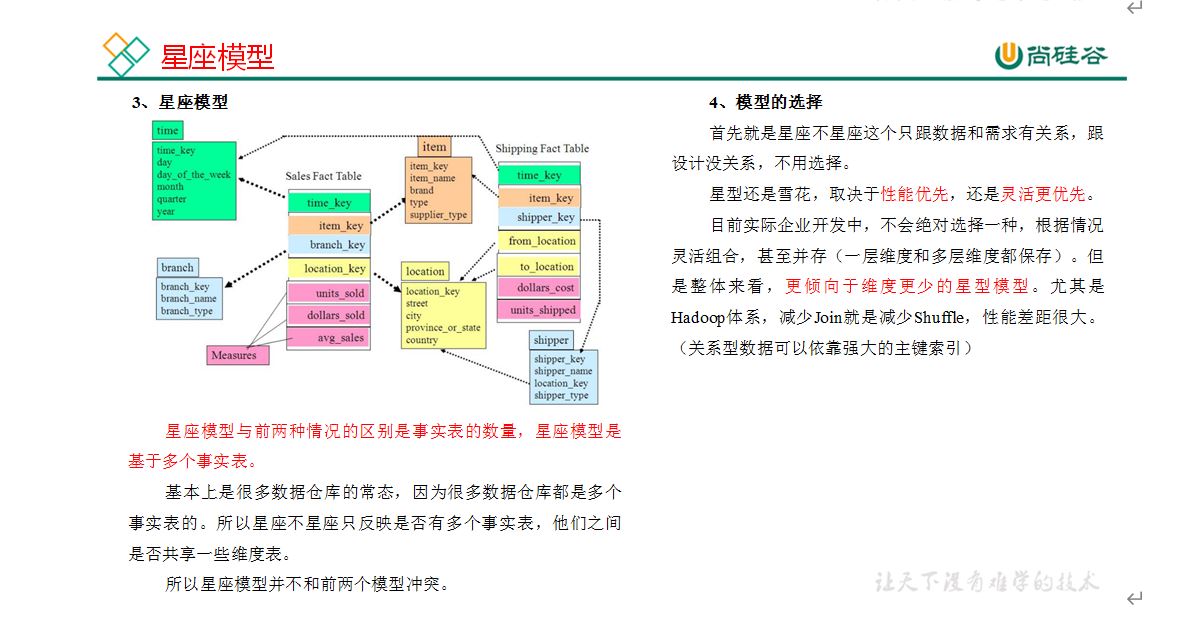
星座模型是多个星型模型交织
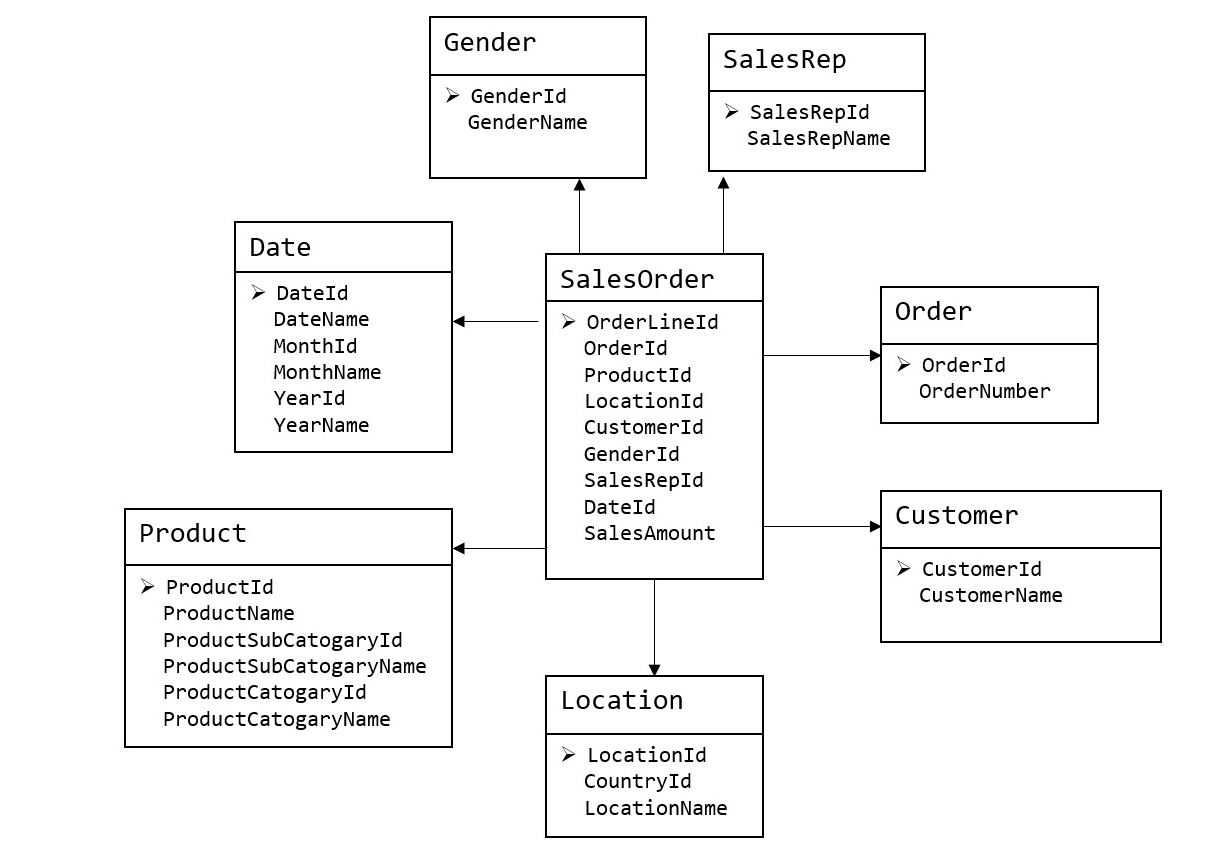
1 建模
维度模型面向业务,将业务用事实表和维度表呈现出来。
步骤:
https://www.cnblogs.com/suheng01/p/13522677.html
选择业务过程→声明粒度→确认维度→确认事实
2 特点
维度模型以数据分析作为出发点,不遵循三范式,故数据存在一定的冗余。
表结构简单,故查询简单,查询效率较高。
https://huggingface.co/docs/transformers/task_summary Language Modeling
https://blog.csdn.net/kaede1209/article/details/81145560
https://tech.meituan.com/2016/05/12/spark-tuning-pro.html
发生在两个过程:
https://arxiv.org/abs/1809.05679
1.build a single text graph for a corpus based on word co-occurrence and document word relations,
2.then learn a Text Graph Convolutional Network (Text GCN) for the corpus. Our Text GCN is initialized with one-hot representation for word and document, it then jointly learns the embeddings for both words and documents, as supervised by the known class labels for documents.
根据rdd的依赖关系构建dag,根据dag划分stage
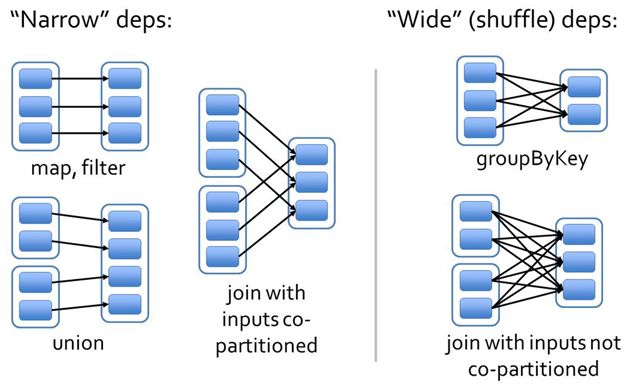
蓝色框是rdd分区
父rdd -> 子rdd
区分宽窄依赖主要就是看父RDD数据流向,要是流向一个的话就是窄依赖,流向多个的话就是宽依赖。
https://blog.csdn.net/weixin_40271036/article/details/79996516
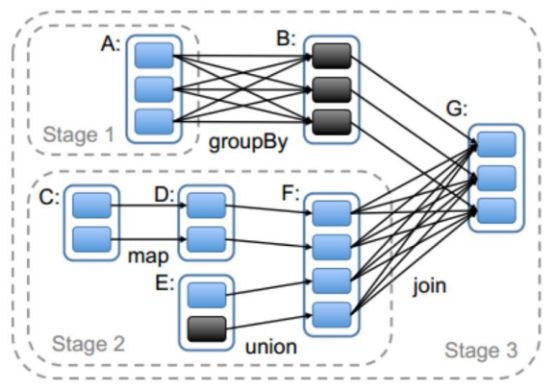
整体思路是:从后往前推,遇到宽依赖就断开,划分为一个stage;遇到窄依赖就将这个RDD加入该stage中
https://www.jianshu.com/p/5c2301dfa360
https://zhuanlan.zhihu.com/p/67068559
https://blog.csdn.net/m0_49834705/article/details/113111596
https://lmrzero.blog.csdn.net/article/details/106015264?spm=1001.2014.3001.5502
为啥宽依赖有shuffle 窄依赖没有shuffle