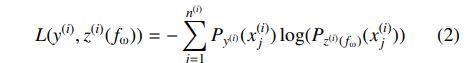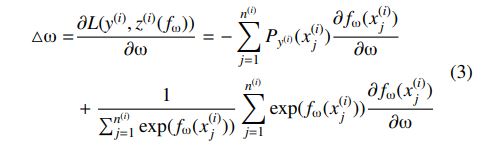消息传递
1.使用内置的消息传递api
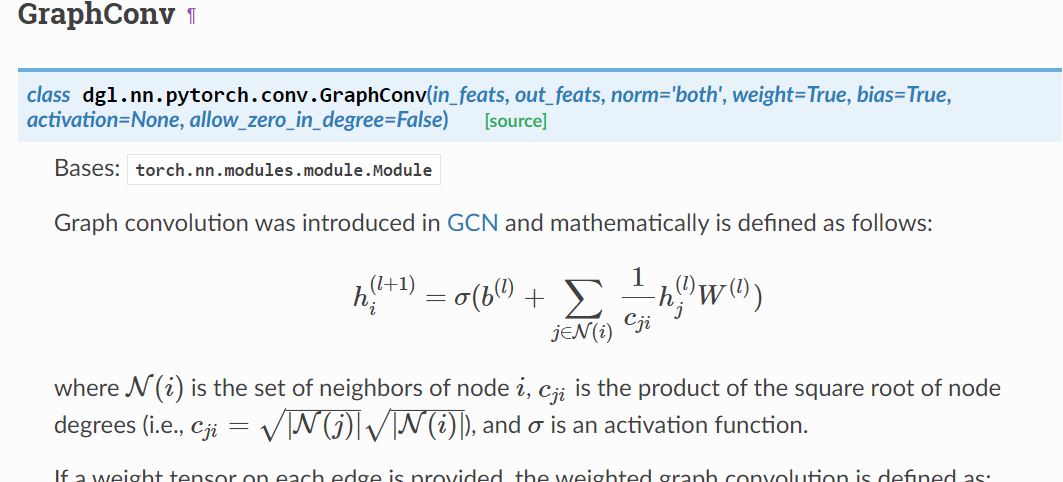
比如GraphConv
2.实现自己的消息传递策略
Write your own GNN module
https://docs.dgl.ai/tutorials/blitz/3_message_passing.html
Message Passing APIs
https://docs.dgl.ai/guide/message-api.html#guide-message-passing-api
https://docs.dgl.ai/guide/message-heterograph.html
Apply Message Passing On Part Of The Graph
https://docs.dgl.ai/guide/message-part.html
message function,Reduce function