图神经工具
PyG, DGL对比
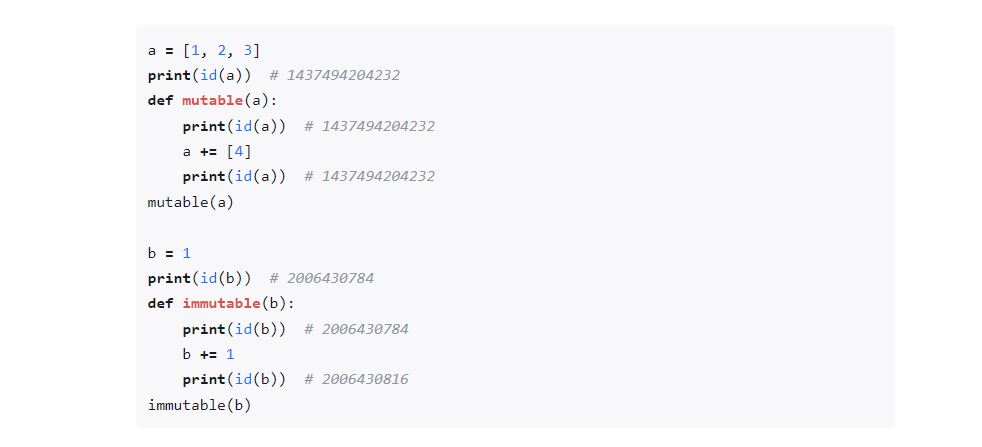
可变对象 改变原来
不可变对象 不改变原来
https://blog.csdn.net/weixin_41972881/article/details/81562731
https://blog.csdn.net/weixin_45775963/article/details/103696945
1 | def fun(va1,va2=[]): |
va2如果没有传参,采用默认的,默认的会变化,不是一直是[]
va2如果是外部的传参,以传参为主,会覆盖
1 *args
def test(*args)
print(args)
test(1,2,3,4)
test(*(1,2,3,4))
(1,2,3,4)
(1,2,3,4)
2 **kwargs
def test(**kwargs)
print(args)
test(x=1,y=2,z=3)
test(**{‘x’:1,’y’:2,’z’:3})
{‘x’:1,’y’:2,’z’:3}
{‘x’:1,’y’:2,’z’:3}
特点:非预训练,参数量少
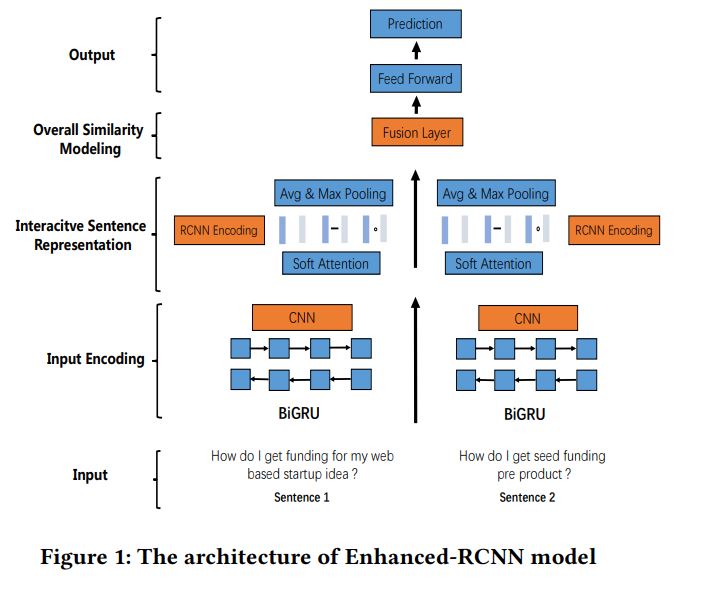
得到两个encoding,RNN Encoding,RCNN Encoding
1 BiGRU
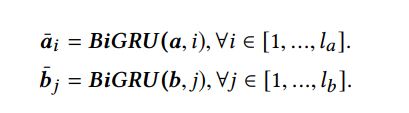
$\textbf{a}=\{a_1,a_2,…,a_{l_a}\},\textbf{a}$ 是句子,$l_a$ 是句子1的长度
得到RNN Encoding,$\overline{\textbf{p}}_i$统一表示$\overline{\textbf{a}}_i,\overline{\textbf{b}}_i$
2 CNN
在 BiGRU 编码的基础上,使用 CNN 来进行二次编码
结构如下,“newtork in network”,k 是卷积核的kernel size,比如k=1,卷积核为$1 \times 1$
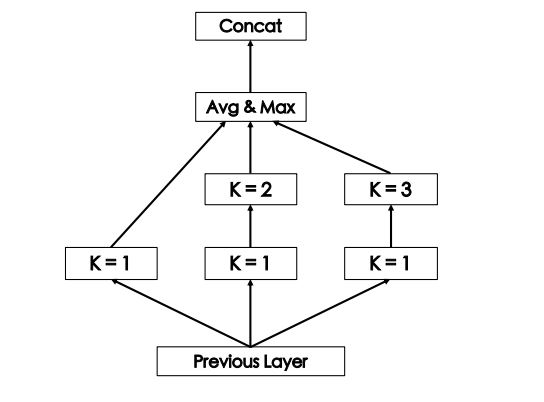
对于每个 CNN 单元,具体的计算过程如下:
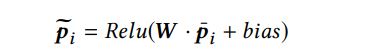
得到 RCNN Encoding $\widetilde{\textbf{p}}_i$
1 Soft-attention Alignment
attention:
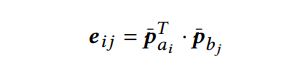
加了attention的rnn encoding:
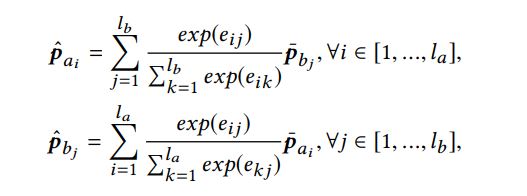
2 Interaction Modeling
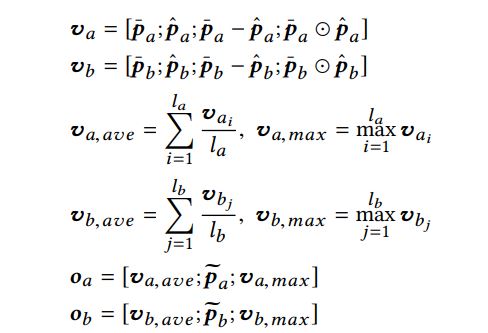
$\overline{\textbf{p}}$是rnn encoding
$\hat{}$是加了attention的rnn encoding
$\widetilde{}$是rcnn encoding
最终得到Interactive Sentence Representation为$\textbf{o}_a,\textbf{o}_b$
1 Fusion Layer
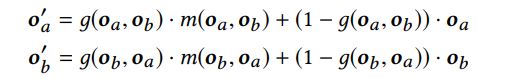
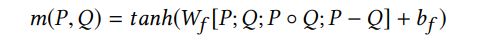
g是门控函数
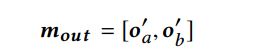
2 Label Prediction
全连接层
交叉熵
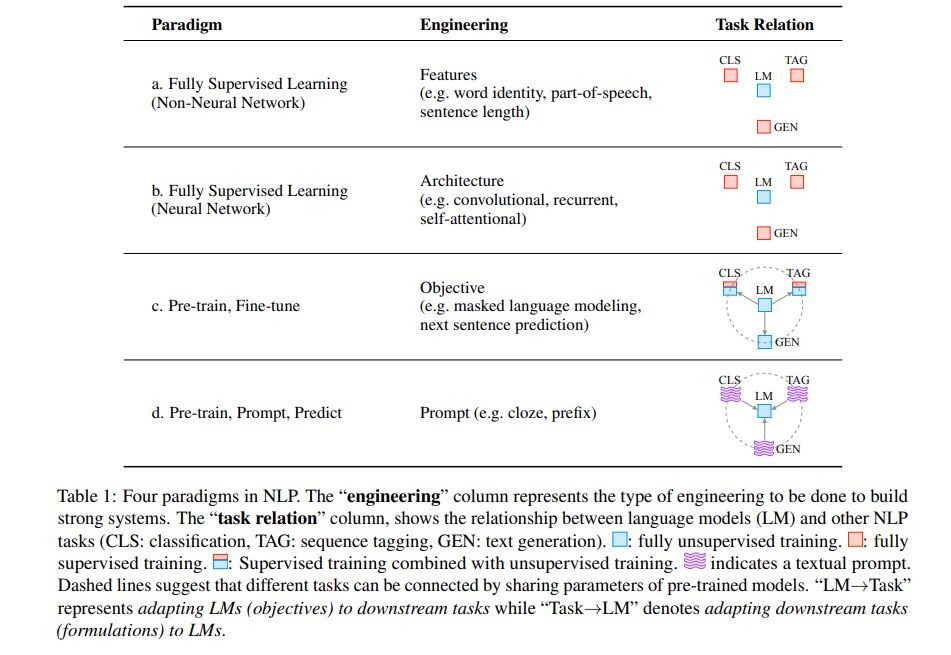

prompt感觉是一种特殊的finetune方式,还是先pre-train然后prompt tuning
目的:prompt narrowing the gap between pre-training and fine-tuning
3步

$x^{‘}=f_{prompt}(x)$ x是input text
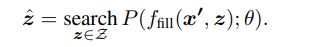
f:fills in the location [Z] in prompt $x^{‘}$ with the potential answer z
Z:a set of permissible values for z
因为上面的 $\hat{z}$ 还不是 $\hat{y}$,比如情感分析,“excellent”, “fabulous”, “wonderful” -》positive
go from the highest-scoring answer $\hat{z}$ to the highest-scoring output $\hat{y}$
原来
“ I love this movie.” -》 positive
现在
1 $x=$ “ I love this movie.” -》模板为: “ [x] Overall, it was a [z] movie.” -》$x^{‘}$为”I love this movie. Overall ,it was a [z] movie.”
2 下一步会进行答案搜索,顾名思义就是LM寻找填在[z] 处可以使得分数最高的文本 $\hat{z}$(比如”excellent”, “great”, “wonderful” )
3 最后是答案映射。有时LM填充的文本并非任务需要的最终形式(最终为positive,上述为”excellent”, “great”, “wonderful”),因此要将此文本映射到最终的输出$\hat{y}$

1 one must first consider the prompt shape,
2 then decide whether to take a manual or automated approach to create prompts of the desired shape
Prompt的形状主要指的是[X]和[Z]的位置和数量。
如果在句中,一般称这种prompt为cloze prompt;如果在句末,一般称这种prompt为prefix prompt。
在实际应用过程中选择哪一种主要取决于任务的形式和模型的类别。cloze prompts和Masked Language Model的训练方式非常类似,因此对于使用MLM的任务来说cloze prompts更加合适;对于生成任务来说,或者使用自回归LM解决的任务,prefix prompts就会更加合适;Full text reconstruction models较为通用,因此两种prompt均适用。另外,对于文本对的分类,prompt模板通常要给输入预留两个空,[x1]和[x2]。
the prompt 作用在文本上
D1: Prompt Mining
D2: Prompt Paraphrasing
D3: Gradient-based Search
D4: Prompt Generation
D5: Prompt Scoring
the prompt 直接作用到模型的embedding空间
C1: Prefix Tuning
C2: Tuning Initialized with Discrete Prompts
C3: Hard-Soft Prompt Hybrid Tuning
two dimensions that must be considered when performing answer
engineering:1 deciding the answer shape and 2 choosing an answer design method.
和Prompt Shape啥区别???
之前在讨论single prompt,现在介绍multiple prompts

1 Training Settings
full-data
few-shot /zero-shot
2 Parameter Update Methods
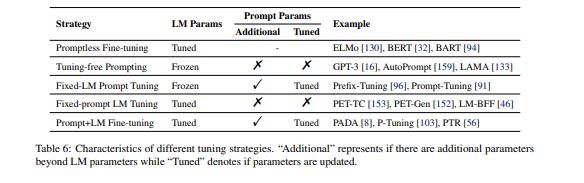
https://arxiv.org/abs/2107.13586
刘鹏飞博士 https://zhuanlan.zhihu.com/p/395115779
https://zhuanlan.zhihu.com/p/399295895
paper: https://arxiv.org/abs/1904.05046
git: https://github.com/tata1661/FSL-Mate/tree/master/FewShotPapers#Applications
原文按应用对FSL做了总结,与NLP相关的有:
子没有重写,则继承父
1 | class A: |
https://blog.csdn.net/weixin_40734030/article/details/122861895
目的:使得子类初始化的时候调用父类的init
例子:
1 | class test1: |
1 |
|
https://blog.csdn.net/HailinPan/article/details/109818774
1 model.load_state_dict(torch.load(path))
2 model=BertModel.from_pretrained
后者的底层为前者
用法不同,前者model为一个对象,然后用load_state_dict加载权重;后者BertModel为一个类,然后用from_pretrained创建对象并加载权重
NLP小帮手,huggingface的transformer
git: https://github.com/huggingface/transformers
paper: https://arxiv.org/abs/1910.03771v5
整体结构
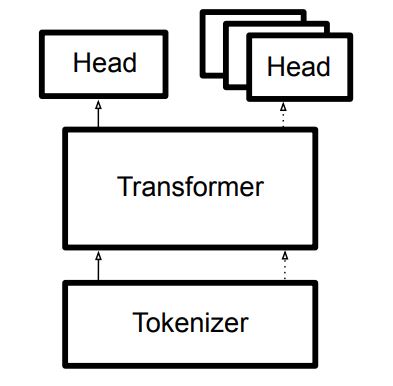
简单教程:
https://blog.csdn.net/weixin_44614687/article/details/106800244
底层为load_state_dict
1 | Some weights of the model checkpoint at ../../../../test/data/chinese-roberta-wwm-ext were not used when initializing listnet_bert: ['cls.predictions.transform.dense.weight', 'cls.seq_relationship.bias', 'cls.predictions.transform.dense.bias', 'cls.predictions.decoder.weight', 'cls.predictions.transform.LayerNorm.bias', 'cls.seq_relationship.weight', 'cls.predictions.bias', 'cls.predictions.transform.LayerNorm.weight'] |
BertModel -> our model
1 加载transformers中的模型
1 | from transformers import BertPreTrainedModel, BertModel,AutoTokenizer,AutoConfig |
2 基于1中的模型搭建自己的结构