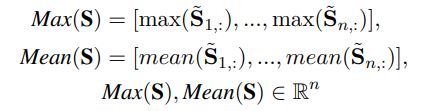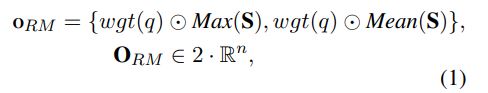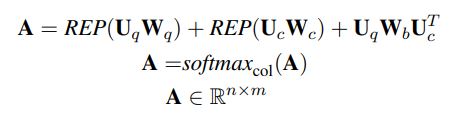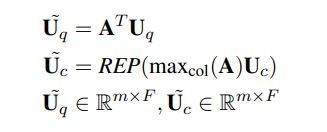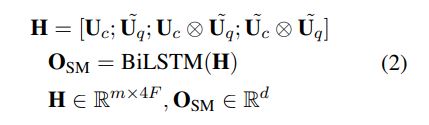https://arxiv.org/abs/1901.02860
Transformers have a potential of learning longer-term dependency, but are limited by a fixed-length context in the setting of language modeling ( memory and computation受限,长度不可能很大 ). propose a novel neural architecture Transformer-XL that enables learning dependency beyond a fixed length without disrupting temporal coherence.
3 Model
3.1 Vanilla Transformer Language Models

问题:In order to apply Transformer or self-attention to language modeling, the central problem is how to train a Transformer to effectively encode an arbitrarily long context into a fixed size representation.通常做法为vanilla model。 vanilla model就是说把长文本分隔成固定长度的seg来处理,如上图。
During training,There are two critical limitations of using a fixed length context. First, the largest possible dependency length is upper bounded by the segment length. Second. simply chunking a sequence into fixed-length segments will lead to the context fragmentation problem
During evaluation, As shown in Fig. 1b, this procedure ensures that each prediction utilizes the longest possible context exposed during training, and also relieves context fragmentation issue encountered in training. However, this evaluation procedure is extremely expensive.
3.2 Segment-Level Recurrence with State Reuse
introduce a recurrence mechanism to the Transformer architecture.
定义变量

转换过程
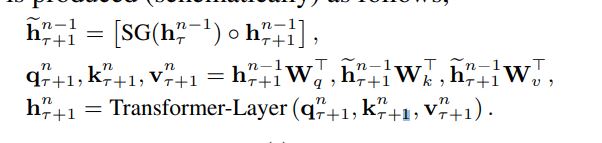
SG() stands for stop-gradient,$\circ$ 表示矩阵拼接
具体过程如下图
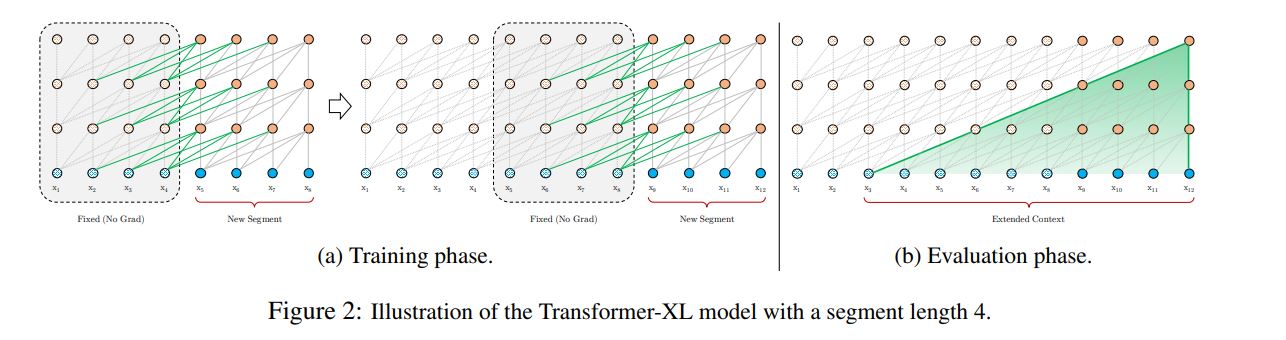
During training, the hidden state sequence computed for the previous segment is fixed and cached to be reused as an extended context when the model processes the next new segment, as shown in Fig. 2a.
during evaluation, the representations from the previous segments can be reused instead of being computed from scratch as in the case of the vanilla model.
3.3 Relative Positional Encodings
how can we keep the positional information coherent when we reuse the states? 如果保留原来的位置编码形式,可以得到如下
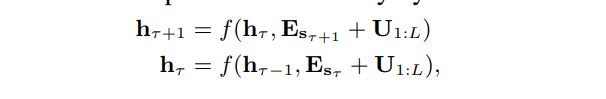
这种方式存在问题:

为了解决这个问题提出了relative positional information。
standard Transformer
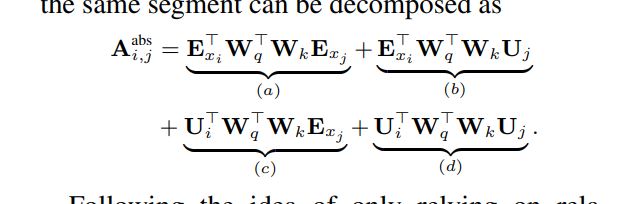
we propose
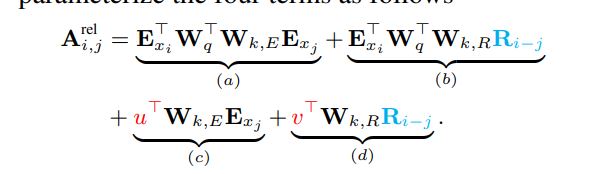
3.4 完整算法流程