时间复杂度计算

pytorch搭建神经网络
0.准备数据,处理数据
1.搭建网络结构
https://www.cnblogs.com/tian777/p/15341522.html
1 | class pointwise_hybird_contrasive(hybird): |
nn.Module
https://www.cnblogs.com/tian777/p/15341522.html
1 init
2 forward
3 loss
pytorch各种交叉熵函数的汇总具体使用
https://blog.csdn.net/comway_Li/article/details/121490170
L2和L1正则化
https://blog.csdn.net/guyuealian/article/details/88426648
优化器固定实现L2正则化,源码注释:weight_decay (:obj:float, optional, defaults to 0):
Weight decay (L2 penalty)
1 | param_optimizer = list(model.named_parameters()) |
4 predict
2.构建训练框架
a.数据加载器
Dataset/TensorDataset -》 Sampler -》 Dataloader
https://zhuanlan.zhihu.com/p/337850513#
https://blog.csdn.net/ljp1919/article/details/116484330
https://blog.csdn.net/qq_39507748/article/details/105385709
b.优化器
https://pytorch.org/docs/stable/optim.html
1 | optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9) |
c 训练
optimizer.zero_grad() 梯度归零, loss.backward() 反向传播 , optimizer.step() 参数更新
https://blog.csdn.net/PanYHHH/article/details/107361827
d. 验证
with torch.no_grad()
验证,测试时候用:可显著减少显存占用
https://wstchhwp.blog.csdn.net/article/details/108405102
https://blog.csdn.net/weixin_44134757/article/details/105775027
e. 评价指标
f. 模型保存
https://blog.csdn.net/m0_37605642/article/details/120325062
https://blog.csdn.net/weixin_41278720/article/details/80759933
g. 可视化
https://blog.csdn.net/Wenyuanbo/article/details/118937790
3.预测
加载模型,输入数据,调用网络结构
参考
text edit
Pre-Training with Whole Word Masking for Chinese BERT
BERT-wwm-ext
wwm:whole word mask
ext: we also use extended training data (mark with ext in the model name)
预训练
1 改变mask策略
Whole Word Masking,wwm
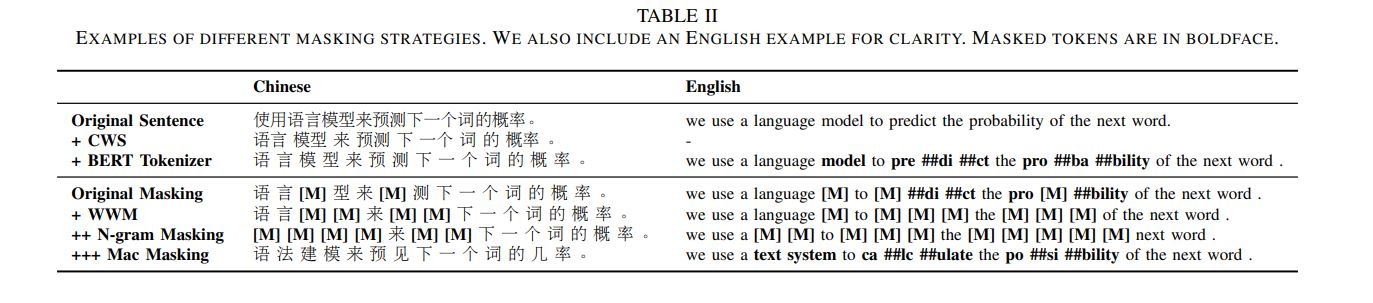
cws: Chinese Word Segmentation
对比四种mask策略
参考
Pre-Training with Whole Word Masking for Chinese BERT
https://arxiv.org/abs/1906.08101v3
Revisiting Pre-trained Models for Chinese Natural Language Processing