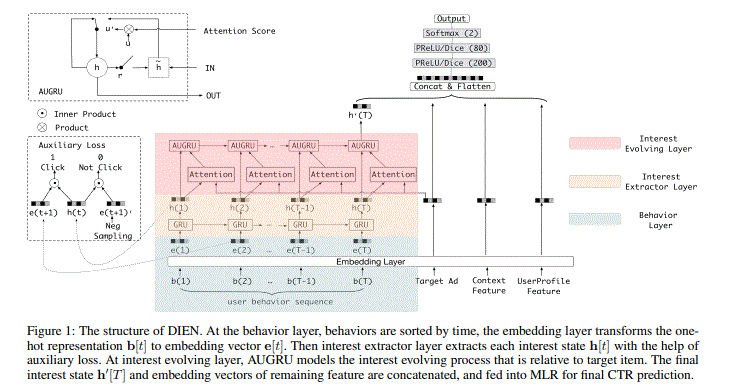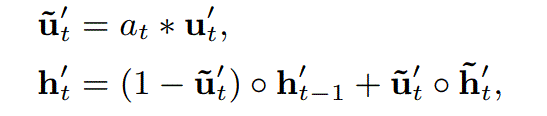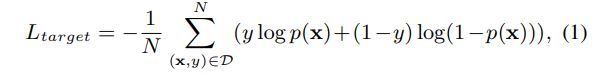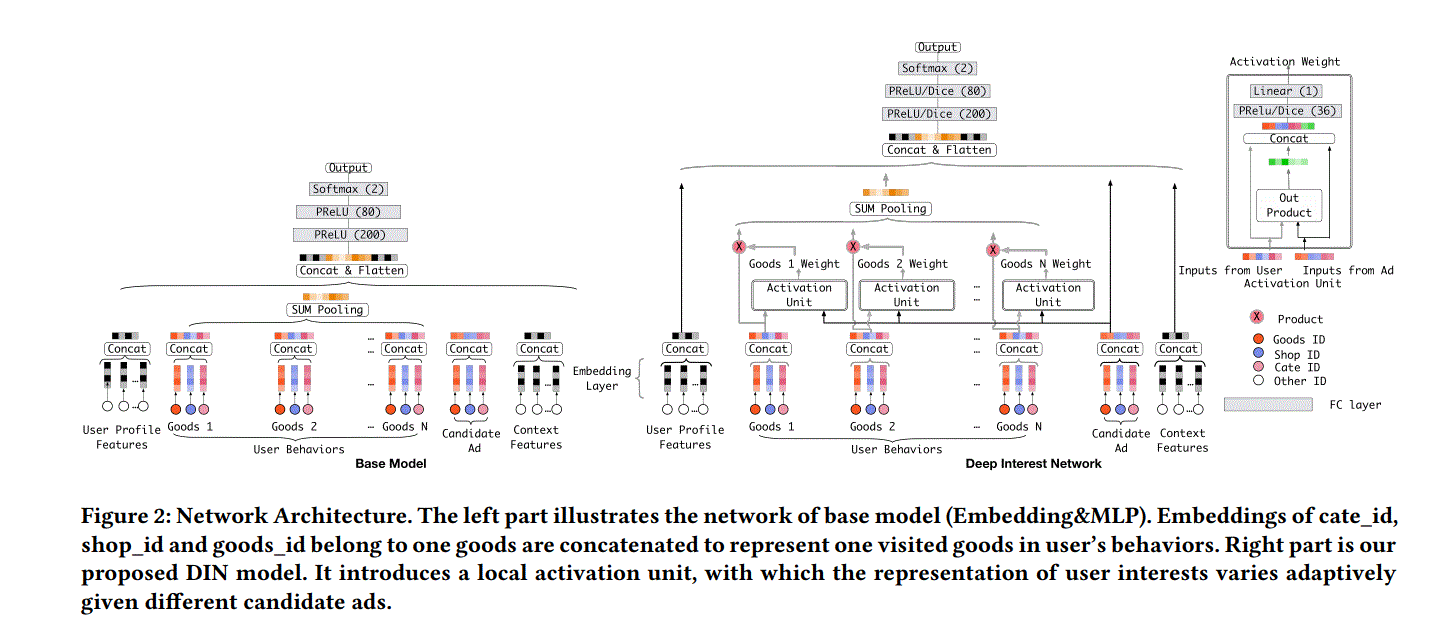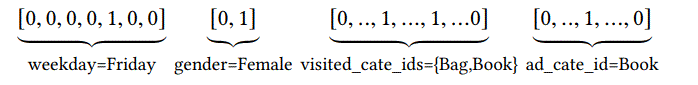
1 输入特征
由4个部分构成,分别为User Profile, User Behavior, Target Item and Context,每个特征都包含子特征,比如User Profile contains user ID, consumption level and so on。最初的表示为one-hot形式,经过embedding层,转成高纬向量,通过查找表来实现。最后4个特征分别表示为$\textbf{x}_p,\textbf{x}_b,\textbf{x}_t,\textbf{x}_c$,以$\textbf{x}_b$来举例,$\textbf{x}_b=[e_1,e_2,…,e_T]\in \mathbb{R}^{T\times d_e}$
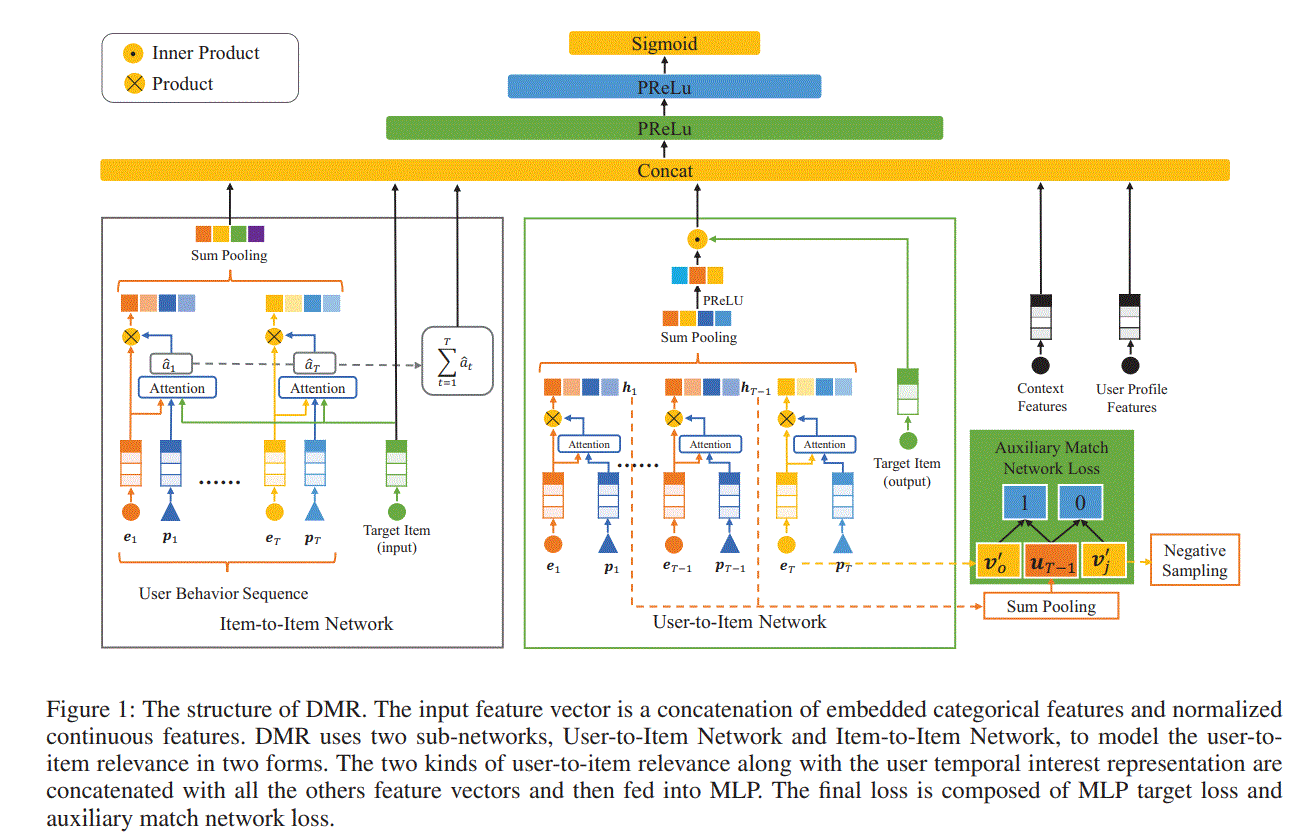
2 User-to-Item Network
we apply attention mechanism with positional encoding as query to adaptively learn the weight for each behavior,where the position of user behavior is the serial number in the behavior sequence ordered by occurred time
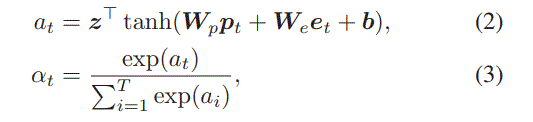
其中$\textbf{z}\in \mathbb{R}^{d_h}$是学习的参数,$\textbf{p}_t\in \mathbb{P}^{d_p}$是位置$t$的embedding
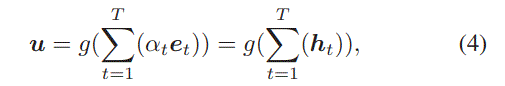
为什么不用$\textbf{x}_t$,而用$\textbf{v}^{‘}$表示Target Item。作者的意思是对于Target Item,有两个查找表,we call $\textbf{V}$ the input representation and $\textbf{V}^{‘}$ the output representation of Target Item。we apply inner product operation to represent the user-to-item relevance

3 Item-to-Item Network
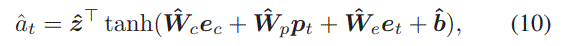

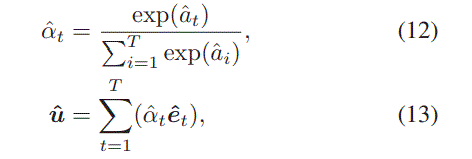
4 final
And the final input of MLP is represented by $\textbf{c}=[\textbf{x}_p,\textbf{x}_t,\textbf{x}_c,\hat{\textbf{u}},r,\hat{r}]$
5 loss
target
The loss for input feature vector $\textbf{x}=[\textbf{x}_p,\textbf{x}_b,\textbf{x}_t,\textbf{x}_c]$ and click label $ y \in \{0, 1\} $is:
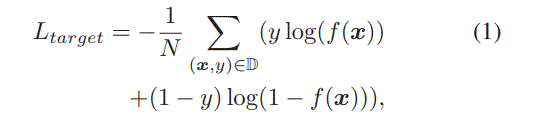
auxiliary match network
主要是提高$r$对于user-to-item relevance的表现能力而引入。
The probability that user with the first $T −1$ behaviors click item $j$ next can be formulated with the softmax function as:
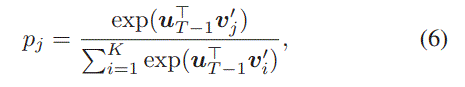
其中$\textbf{v}^{‘}_j$表示第$j$个商品的output representation。With cross-entropy as loss function, we have the loss as follows:
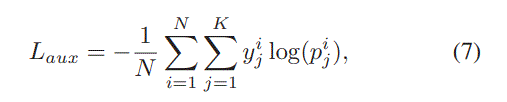
However, the cost of computing $p_j$ in Equation (6) is huge,引入负采样,然后loss为
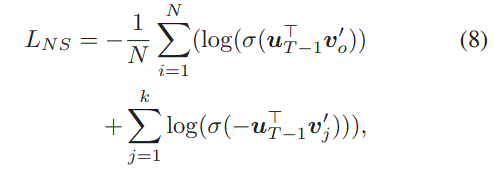
final
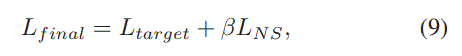
参考
阿里2020年发表在AAAI上的关于CTR的paper,原文链接 https://sci-hub.se/10.1609/aaai.v34i01.5346