import pandas as pd import pickle import os import joblib
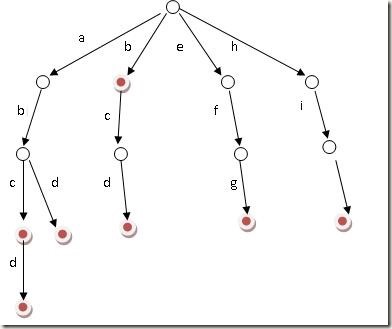
class TrieNode(object): def __init__(self): """ Initialize your data structure here. """ self.data = {}###字母字符 self.data1={}###中文 self.is_word = False###标识是否汉字
class Trie(object):
def __init__(self): self.root = TrieNode()
def insert(self, word,word1): """ Inserts a word into the trie. :type word: str :rtype: void """ node = self.root for letter in word: child = node.data.get(letter) if not child: node.data[letter] = TrieNode() node = node.data[letter] node.is_word = True if word1 not in node.data1: node.data1[word1]=1 else: node.data1[word1]+=1
def search(self, word): """ Returns if the word is in the trie. :type word: str :rtype: bool """ node = self.root for letter in word: node = node.data.get(letter) if not node: return False return node.is_word
def starts_with(self, prefix): """ Returns if there is any word in the trie that starts with the given prefix. :type prefix: str :rtype: bool """ node = self.root for letter in prefix: node = node.data.get(letter) if not node: return False return True
def get_start(self, prefix): """ Returns words started with prefix :param prefix: :return: words (list) """ def _get_key(pre, pre_node): words_list = [] if pre_node.is_word: words_list.append([pre,pre_node.data1]) for x in pre_node.data.keys(): words_list.extend(_get_key(pre + str(x), pre_node.data.get(x))) return words_list
words = [] if not self.starts_with(prefix): return words # if self.search(prefix): # words.append(prefix) # return words node = self.root for letter in prefix: node = node.data.get(letter) return _get_key(prefix, node)
def find_result(self,string): result =self.get_start(string) result = sort_by_value(result[0][1]) result.reverse() return result[0] def sort_by_value(d): return sorted(d.items(), key=lambda k: k[1]) # k[1] 取到字典的值。
def build_tree(data,save_path):
trie = Trie() for element in data.values: trie.insert(element[0], element[1]) joblib.dump(trie, save_path) return