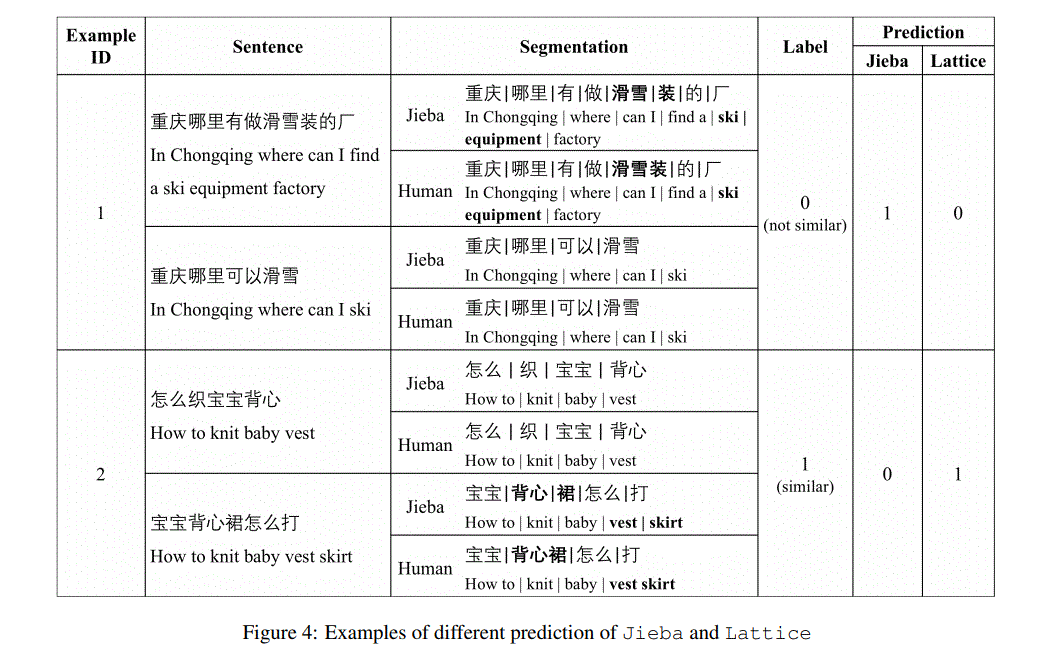
文本匹配
1.无监督
1.1 编辑距离
定义
编辑距离,英文名字为Levenshtein distance,通过描述一个字符串A需要多少次基本操作可以变成字符串B,来衡量两个字符串的相似度。
基本操作包括:增、删、改
增:字符串A为“AS”,字符串B为“ ASD“,字符串A->字符串B需要增加一个字符“D”
删:字符串A为“ASD”,字符串B为“ AS“,字符串A->字符串B需要删除一个字符“D”
改:字符串A为“ASX”,字符串B为“ ASD“,字符串A->字符串B需要将字符“X”变成字符“D”
代码
实现过程使用动态规划,递推公式为
$i$和$j$分别表示字符串$a$和字符串$b$的下标,$lev_{a,b}(i,j)$表示子串$a[:i]$到子串$b[:j]$的编辑距离。
1 | def lev(str_a,str_b): |
1.2 TF-IDF
原理
(1)TF
针对某个doc
越大,这个term在doc中越普通
$TF_{term}=\frac{term在doc中出现的次数}{doc所有词的总数}$
(2)IDF
针对所有doc
越大,这个term在doc集合中越稀有
$IDF_{term}=log(\frac{doc总数}{包含该term的doc数+1})$
(3)TF-IDF
综合上面
$TF-IDF_{term}=TF_{term}*IDF_{term}$
(4)TF-IDF VEC
现有句子A:”今天天气真好”,对句子A做分词得到[“今天”,”天气”,”真好”],词库包含[“今天”,”天气”,”真好”,”天气”,”不错呀”]
$VEC_{A}=[TF-IDF_{今天},TF-IDF_{天气},TF-IDF_{真好},0,0]$
(5)计算两句话的文本相似度
假设词库包含[“今天”,”天气”,”真好”,”天气”,”不错呀”],现有句子A:”今天天气真好”,对句子A做分词得到[“今天”,”天气”,”真好”],句子B:”天气不错呀”,分词后[“天气”,”不错呀”]
利用(3)得到句子A的TF-IDF VEC $VEC_{A}$,句子B的TF-IDF VEC $VEC_B$,利用余弦相似度计算文本相似度
代码
1 | import pandas as pd |
2.有监督
基于表示的匹配方法:使用深度学习模型分别表征Query和Doc,通过计算向量相似度来作为语义匹配分数。微软的DSSM[26]及其扩展模型属于基于表示的语义匹配方法,美团搜索借鉴DSSM的双塔结构思想,左边塔输入Query信息,右边塔输入POI、品类信息,生成Query和Doc的高阶文本相关性、高阶品类相关性特征,应用于排序模型中取得了很好的效果。此外,比较有代表性的表示匹配模型还有百度提出 SimNet[27],中科院提出的多视角循环神经网络匹配模型(MV-LSTM)[28]等。
基于交互的匹配方法:这种方法不直接学习Query和Doc的语义表示向量,而是在神经网络底层就让Query和Doc提前交互,从而获得更好的文本向量表示,最后通过一个MLP网络获得语义匹配分数。代表性模型有华为提出的基于卷积神经网络的匹配模型ARC-II[29],中科院提出的基于矩阵匹配的的层次化匹配模型MatchPyramid[30]。
基于表示的匹配方法优势在于Doc的语义向量可以离线预先计算,在线预测时只需要重新计算Query的语义向量,缺点是模型学习时Query和Doc两者没有任何交互,不能充分利用Query和Doc的细粒度匹配信号。基于交互的匹配方法优势在于Query和Doc在模型训练时能够进行充分的交互匹配,语义匹配效果好,缺点是部署上线成本较高。
匹配不同于排序,匹配是1对1的,排序是1对多
2.1基于表示
https://zhuanlan.zhihu.com/p/138864580
https://blog.csdn.net/qq_27590277/article/details/121391770