文本生成评价指标
1.BLEU
BLEU,全称为bilingual evaluation understudy,一般用于机器翻译和文本生成的评价,比较候选译文和参考译文里的重合程度,重合程度越高就认为译文质量越高,取值范围为[0,1]。
优点
- 它的易于计算且速度快,特别是与人工翻译模型的输出对比;
- 它应用范围广泛,这可以让你很轻松将模型与相同任务的基准作对比。
缺点
- 它不考虑语义,句子结构
- 不能很好地处理形态丰富的语句(BLEU原文建议大家配备4条翻译参考译文)
- BLEU 指标偏向于较短的翻译结果(brevity penalty 没有想象中那么强)
1.1 完整式子
BLEU完整式子为:
1.2 $BP$
目的:$n-gram$匹配度可能会随着句子长度的变短而变好,比如,只翻译了一个词且对了,那么匹配度很高,为了避免这种评分的偏向性,引入长度惩罚因子
Brevity Penalty为长度惩罚因子,其中$l_c$表示机器翻译的译文长度,$l_s$表示参考答案的有效长度
1.3 $P_n$
人工译文表示为$s_j$,其中$j \in M$,$M$表示共有$M$个参考答案
翻译译文表示$c_i$,其中$i \in E$,$E$表示共有$E$个翻译
$n-gram$表示$n$个单词长度的词组集合,令$k$ 表示第$k$ 个词组,总共$K$个
$h_k(c_i)$表示第$k$个词组在翻译译文$c_i$出现的次数
$h_k(s_{j})$表示第$k$个词组在参考答案$s_{j}$出现的次数
举例如下,例如:
原文:今天天气不错
机器译文:It is a nice day today
人工译文:Today is a nice day
$1-gram$:

可以看到机器译文一共6个词,有5个词语都命中的了参考译文,$P_1=\frac{5}{6}$
$3-gram$:

机器译文一共可以分为4个$3-gram$的词组,其中有2个可以命中参考译文,那么$P_3=\frac{2}{4}$
1.4 $W_n$
$W_n$表示$P_n$的权重,一般为加权平均,即$W_n=\frac{1}{N}$,其中$N$为$gram$的数量,一般不大于4
2 ROUGE
Recall-Oriented Understudy for Gisting Evaluation,可以看做是BLEU 的改进版,专注于召回率而非精度。换句话说,它会查看有多少个参考译句中的 n 元词组出现在了输出之中。
ROUGE大致分为四种(常用的是前两种): - ROUGE-N (将BLEU的精确率优化为召回率) - ROUGE-L (将BLEU的n-gram优化为公共子序列) - ROUGE-W (将ROUGE-L的连续匹配给予更高的奖励) - ROUGE-S (允许n-gram出现跳词(skip))
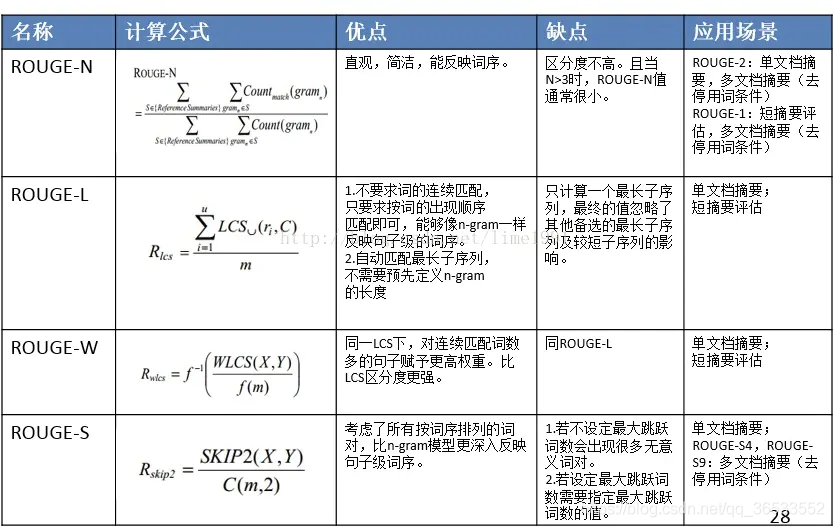
注意:
关于rouge包给出三个结果,而论文只有一个值,比如
1 | [{'rouge-1': {'r': 1.0, 'p': 1.0, 'f': 0.999999995}, 'rouge-2': {'r': 0.0, 'p': 0.0, 'f': 0.0}, 'rouge-l': {'r': 1.0, 'p': 1.0, 'f': 0.999999995}}] |
用“r”,recall就好了
3 NIST
4 METEOR
5 TER
参考文献
https://blog.csdn.net/qq_36533552/article/details/107444391
https://zhuanlan.zhihu.com/p/144182853
https://arxiv.org/pdf/2006.14799.pdf
https://www.cnblogs.com/by-dream/p/7679284.html
https://blog.csdn.net/qq_30232405/article/details/104219396