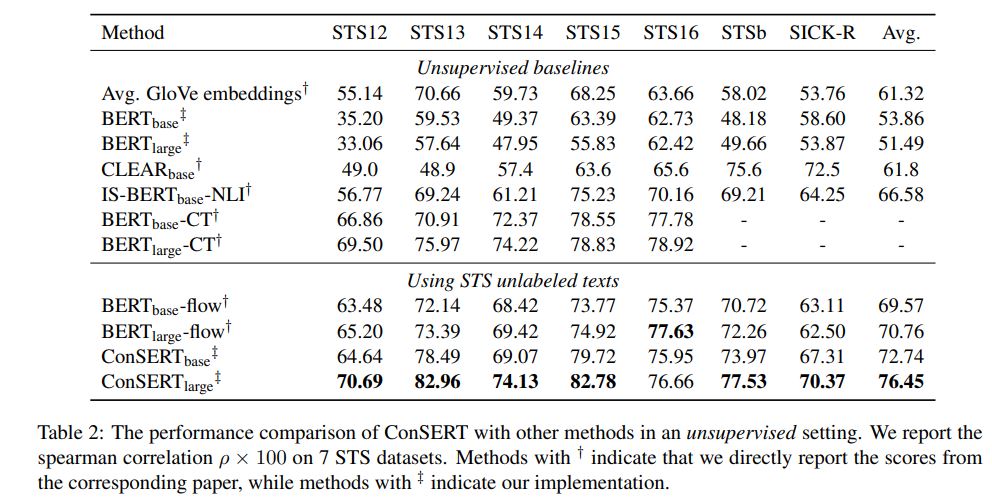
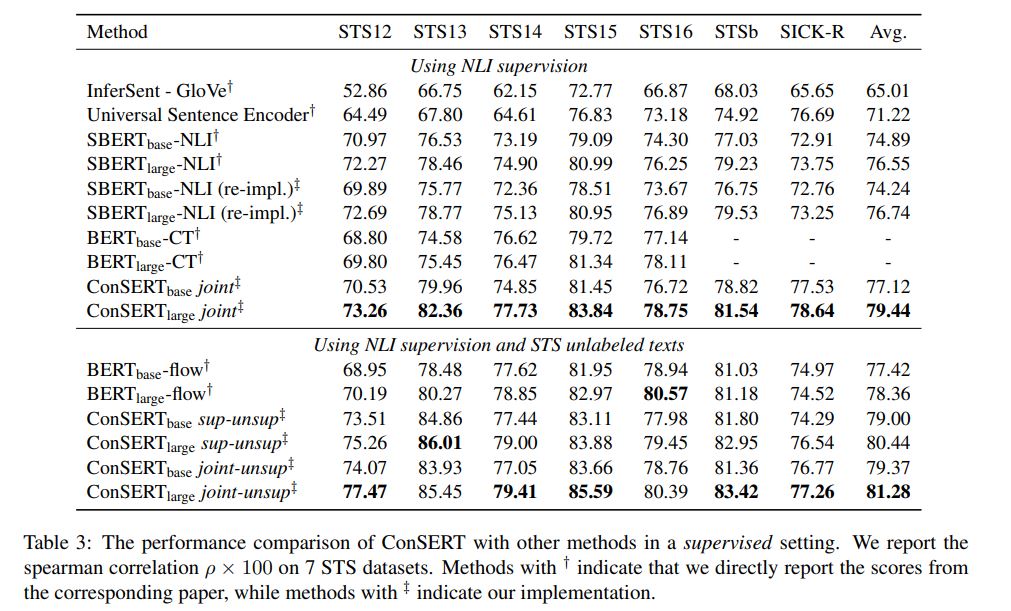
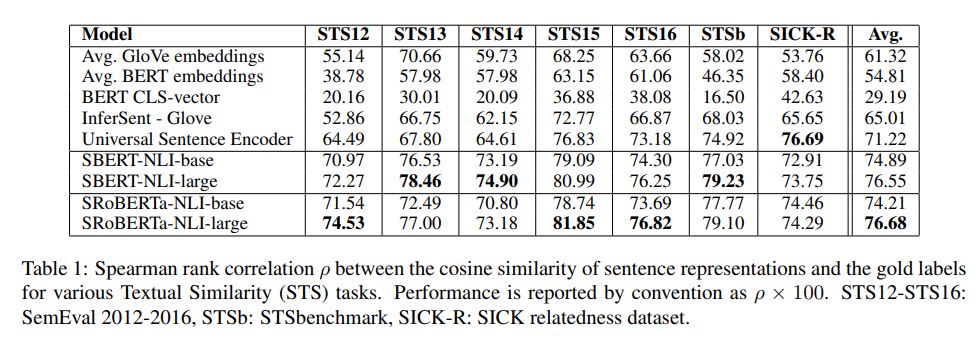
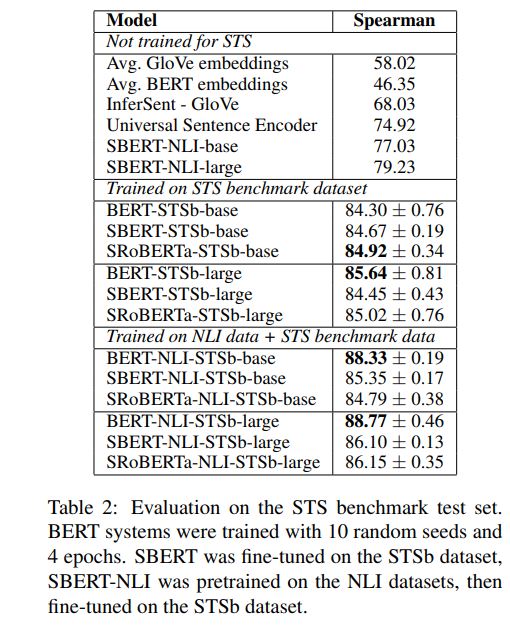
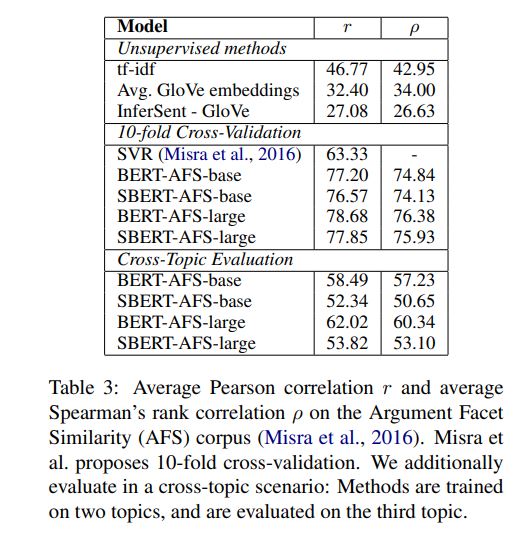
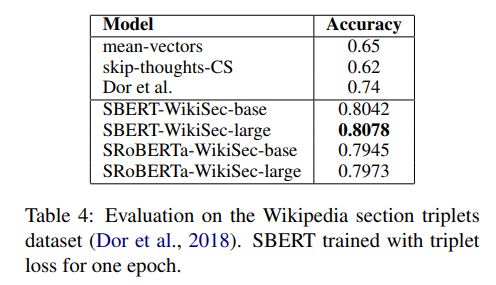
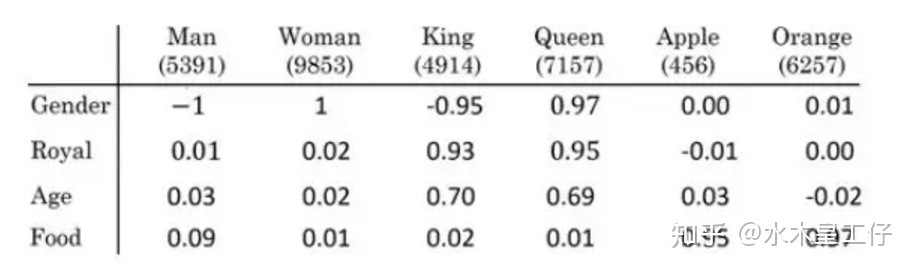
SimCSE Simple Contrastive Learning of Sentence Embeddings
https://arxiv.org/pdf/2104.08821.pdf
1.背景
1 target
对于$D=\{(x_i,x_i^{+})\}_{i=1}^{m}$,where $x_i$ and $x_i^{+}$ are semantically related. xi,xj+ are not semantically related
x->h
Contrastive learning aims to learn effective representation by pulling semantically close neighbors together and pushing apart non-neighbors
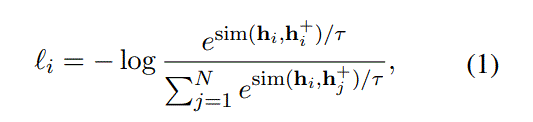
N is mini-batch size,分子是正样本,分母为负样本(有一个正样本,感觉是可以忽略)
分母会包含分子的项吗?从代码看,会的
loss
https://www.jianshu.com/p/d73e499ec859
1 | def loss(self,y_pred,y_true,lamda=0.05): |
2 representations评价指标
Alignment: calculates expected distance between embeddings of the paired instances(paired instances就是正例)
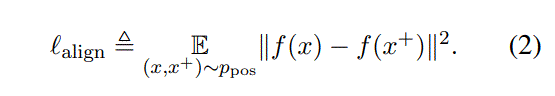
uniformity: measures how well the embeddings are uniformly distributed
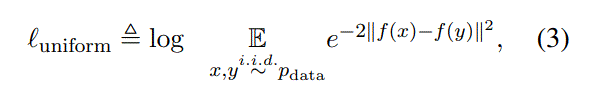
2.结构
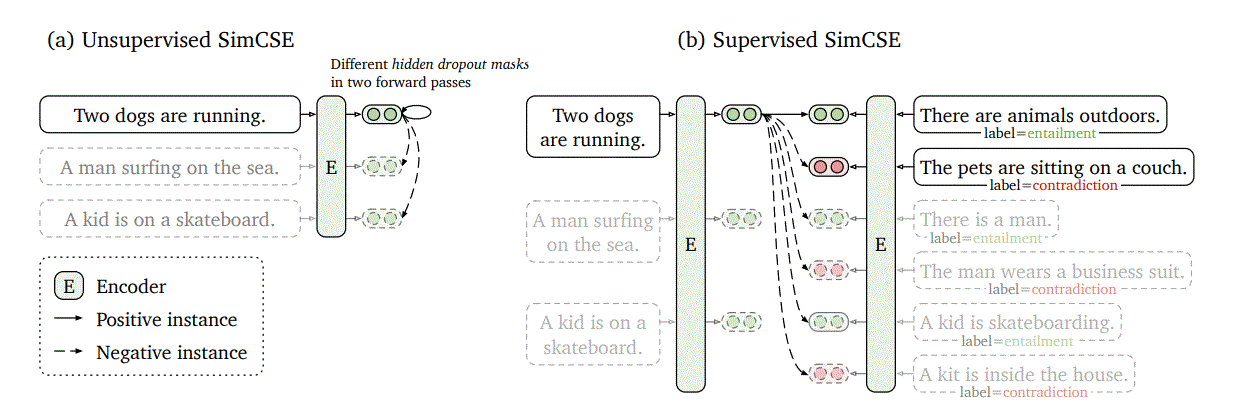
2.1 Unsupervised
$x_i->h_i^{z_i},x_i->h_i^{z_i^{‘}}$
z is a random mask for dropout,loss为
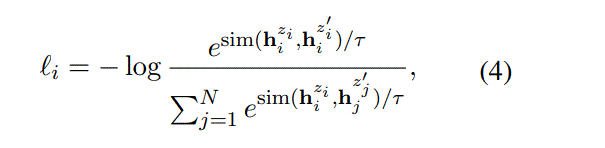
2.2 Supervised
引入非目标任务的有标签数据集,比如NLI任务,$(x_i,x_i^{+},x_i^{-})$,where $x_i$ is the premise, $x_i^{+}$and $x_i^{-}$are entailment and contradiction hypotheses.
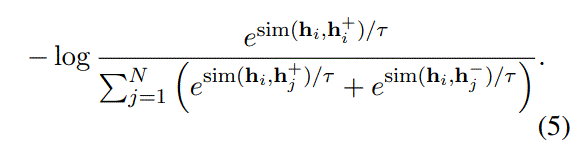
$(h_i,h_j^{+})$为normal negatives,$(h_i,h_j^{-})$为hard negatives