极大似然估计
1.定义
就是利用已知的样本结果信息,反推最具有可能导致这些样本结果出现的模型参数值。换句话说,即:“模型已定,结果已知,反推参数”。
2.极大似然构造损失函数
大多数常见的损失函数就是基于极大似然推导的。例子参考 https://www.cnblogs.com/hello-ai/p/11000899.html
判别模型下的极大似然估计
最大似然估计很容易扩展到估计条件概率$P\left (y|x;\theta \right)$,从而给定$x$预测$y$。实际上这是最常见的情况,因为这构成了大多数监督学习的基础。如果$X$表示所有的输入,$Y$表示我们观测到的目标,那么条件最大似然估计是:
如果假设样本是独立同分布的,那么这可以分解成
生成模型下的极大似然估计
考虑一组含有m个样本的数据集$X = \left \{ x^{(1)}, …, x^{(m)} \right \}$,由$p_{data}(x)$生成,独立同分布
对独立同分布的样本,生成样本集$X$的概率如下:
对$\theta$的最大似然估计被定义为:
多个概率的乘积公式会因很多原因不便于计算。例如,计算中很可能会因为多个过小的数值相乘而出现数值下溢。为了得到一个便于计算的等价优化问题,两边取对数:
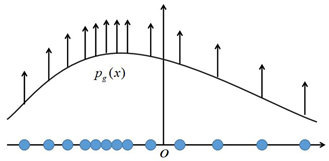
可以发现,使用极大似然估计时,每个样本$x^{(i)}$都希望拉高它所对应的模型概率值$p_{model}(x^{(i)};\theta)$,如上图所示,但是由于所有样本的密度函数$p_{model}(x^{(i)};\theta)$的总和必须是1,所以不可能将所有样本点都拉高到最大的概率,一个样本点的概率密度函数值被拉高将不可避免的使其他点的函数值被拉低,最终的达到一个平衡态。我们也可以将上式除以$m$,便可以看到极大似然法最大化的目标是在经验分布$\widehat{p}_{data}$下样本概率对数的期望值,即
参考
https://zhuanlan.zhihu.com/p/26614750
https://www.cnblogs.com/hello-ai/p/11000899.html