数仓分层
https://blog.csdn.net/BeiisBei/article/details/105723188#_19
https://www.saoniuhuo.com/article/detail-72.html
https://www.dianjilingqu.com/20890.html
https://www.i4k.xyz/article/wjt199866/115184169#ODS__100
1.为什么要分层
1.清晰数据结构:每一个数据分层都有它的作用域,这样我们在使用表的时候能更方便地定位和理解。
2.数据血缘追踪:简单来讲可以这样理解,我们最终给业务呈现的是一张能直接使用的张业务表,但是它的来源有很多,如果有一张来 源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。
3.减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
4.把复杂问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。
5.屏蔽原始数据的异常:屏蔽业务的影响,不必改一次业务就需要重新接入数据。
2.分层结构
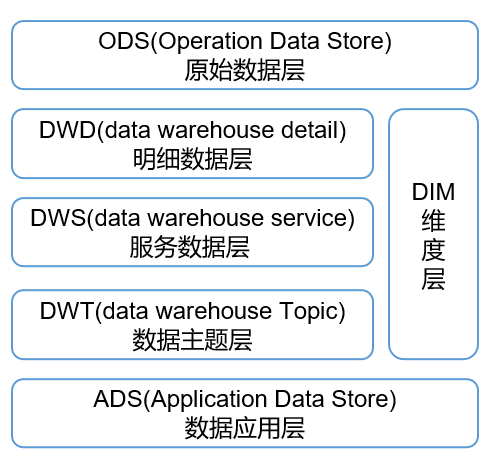
2.1 ODS层
作用
https://blog.csdn.net/xuebo_911/article/details/8156016#
起到备份数据的作用
构建
1 直接加载原始日志、数据,保持原貌不做处理
2.2 DIM层
dim存放维度表,dwd存放事实表
作用
维度表可以看作是用户来分析数据的窗口,维度表中包含事实数据表中事实记录的特性,有些特性提供描述性信息,有些特性指定如何汇总事实数据表数据,以便为分析者提供有用的信息,维度表包含帮助汇总数据的特性的层次结构。
构建
https://help.aliyun.com/document_detail/137615.html
1 构建维度表,主要是对业务事实的描述信息,例如何人,何时,何地等
2.3 DWD层
作用
保存业务事实明细,一行信息代表一次业务行为,例如一次下单。
构建
1 对ODS层数据进行清洗(去除空值,脏数据,超过极限范围的数据、脱敏等)
2 构建事实表
https://help.aliyun.com/document_detail/114457.html
2.4 DWS
作用
避免重复计算
1)问题引出
两个需求,统计每个省份订单的个数、统计每个省份订单的总金额,都是将省份表和订单表进行join,group by省份,然后计算。同样数据被计算了两次,实际上类似的场景还会更多。
2) 那怎么设计能避免重复计算呢?
针对上述场景,可以设计一张地区宽表,其主键为地区ID,字段包含为:下单次数、下单金额、支付次数、支付金额等。上述所有指标都统一进行计算,并将结果保存在该宽表中,这样就能有效避免数据的重复计算。
构建
https://help.aliyun.com/document_detail/126913.html
0 分主题
1 构建宽表
2 以DWD为基础,按天进行轻度汇总。DWS层存放的所有主题对象当天的汇总行为,例如每个地区当天的下单次数,下单金额等
2.5 DWT
和DWS区别
DWS按天进行轻度汇总,DWT累积汇总
作用
避免重复计算
构建
0 分主题
1 构建宽表
2 以DWS为基础,对数据进行累积汇总。DWT层存放的是所有主题对象的累积行为,例如每个地区最近7天(15天、30天、60天)的下单次数、下单金额等
2.6 ADS层
作用
为各种统计报表提供数据
构建
1 由于这层的数据量不大,所有没有分区,列式存储,压缩
3.构建过程
借助hive,主要就是写SQL,核心步骤就是:
1.建表
2.分区规划
按什么分区,比如说按天,按月
注意数据同步策略,全量,增量等
3.数据装载
注意首日,每日
联系业务和不同层的要求
4.全流程调度
Azkaban