正则化
是机器学习中对原始损失函数引入额外信息,以便防止过拟合和提高模型泛化性能的一类方法的统称。
1.L1正则(Lasso回归)
L1正则化可以使得参数稀疏化,即得到的参数是一个稀疏矩阵,可以用于特征选择。
L1是每次减去一个常数的收敛,所以L1更容易收敛到0。
2.L2正则(Ridge回归)
L2正则化使得参数平滑。
L2是每次乘上一个小于1的倍数进行收敛,所以L2使得参数平滑。
3.dropout
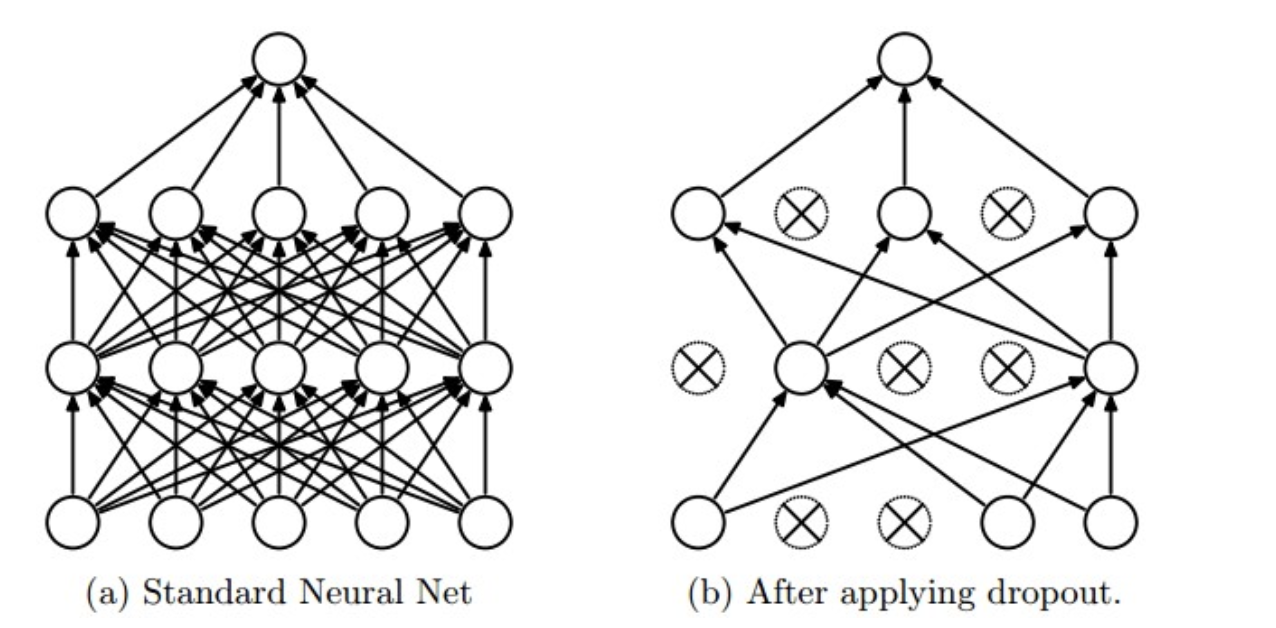
使用:在训练时,每个神经单元以概率$p$被保留(Dropout丢弃率为$1−p$);在预测阶段,每个神经单元都是存在的。
原理:神经网络通过Dropout层以一定比例随即的丢弃神经元,使得每次训练的网络模型都不相同,多个Epoch下来相当于训练了多个模型,同时每一个模型都参与了对最终结果的投票,从而提高了模型的泛化能力,类似bagging。
参考
https://www.cnblogs.com/zingp/p/11631913.html