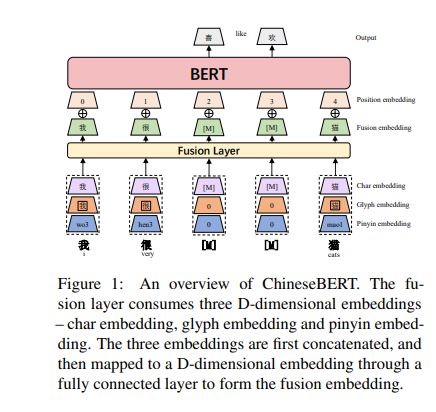
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| >>> from datasets.bert_dataset import BertDataset
>>> from models.modeling_glycebert import GlyceBertModel
>>> tokenizer = BertDataset([CHINESEBERT_PATH])
>>> chinese_bert = GlyceBertModel.from_pretrained([CHINESEBERT_PATH])
>>> sentence = '我喜欢猫'
>>> input_ids, pinyin_ids = tokenizer.tokenize_sentence(sentence)
>>> length = input_ids.shape[0]
>>> input_ids = input_ids.view(1, length)
>>> pinyin_ids = pinyin_ids.view(1, length, 8)
>>> output_hidden = chinese_bert.forward(input_ids, pinyin_ids)[0]
>>> print(output_hidden)
tensor([[[ 0.0287, -0.0126, 0.0389, ..., 0.0228, -0.0677, -0.1519],
[ 0.0144, -0.2494, -0.1853, ..., 0.0673, 0.0424, -0.1074],
[ 0.0839, -0.2989, -0.2421, ..., 0.0454, -0.1474, -0.1736],
[-0.0499, -0.2983, -0.1604, ..., -0.0550, -0.1863, 0.0226],
[ 0.1428, -0.0682, -0.1310, ..., -0.1126, 0.0440, -0.1782],
[ 0.0287, -0.0126, 0.0389, ..., 0.0228, -0.0677, -0.1519]]],
grad_fn=<NativeLayerNormBackward>)
|