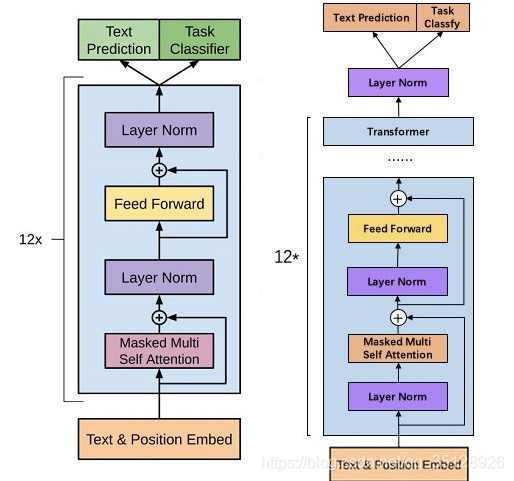
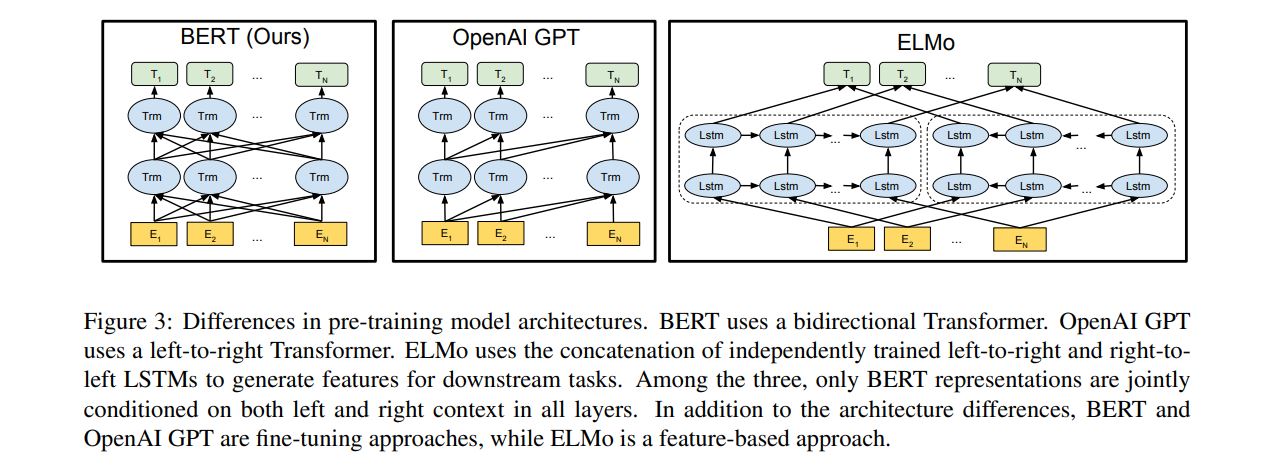
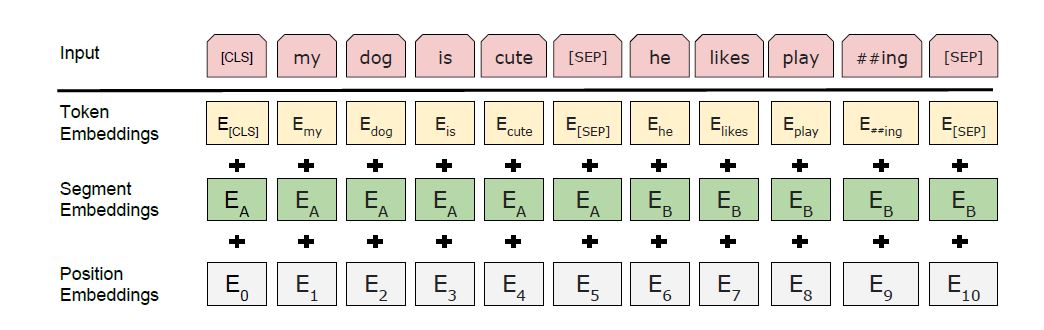
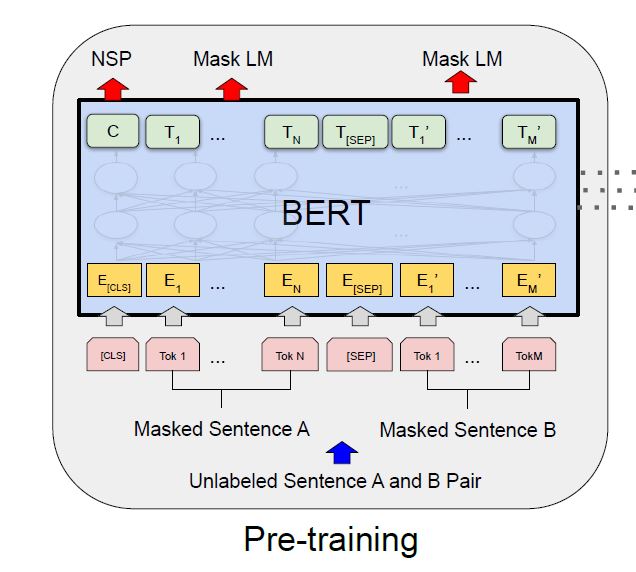
原文内容很丰富,慢慢学习更新。
摘要
这篇综述从language representation learning入手,然后全面的阐述Pre-trained Models的原理,结构以及downstream任务,最后还罗列了PTM的未来发展方向。该综述目的旨在为NLP小白,PTM小白做引路人,感人。
1.Introduction
随着深度学习的发展,许多深度学习技术被应用在NLP,比如CNN,RNN,GNN以及attention。
尽管NLP任务的取得很大成功,但是和CV比较,性能提高可能不是非常明显。这主要是因为NLP任务的数据集都非常小(除了机器翻译),然而深度网络参数非常多,没有足够的数据支撑网络训练会导致过拟合问题。
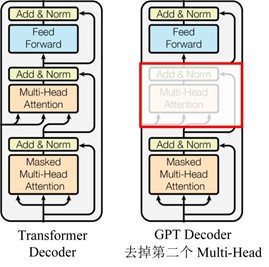
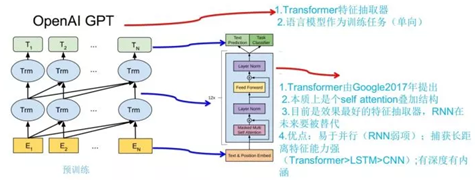
最近,大量工作表明,预先训练的模型(PTMs),在大型语料库上可以学习通用语言表示,这有利于下游NLP任务可以避免从零开始训练新模型。随着算力的发展,深度模型(例如,transformer)的出现和训练技巧的不断调高,PTM的结构从浅层发展成深层。第一代PTM被用于Non-contextual word Embedding。由于下游任务不需要这些模型本身,只需要训练好的词向量矩阵,因此对于现在的算力,这些模型非常浅层,比如Skip-Gram和GloVe。虽然这些预训练词向量可以捕获词语的语义,但它们不受上下文限制,无法捕获上下文中的高级含义,某些任务会失效,例如多义词,句法结构,语义角色、回指。第二代PTM关注Contextual word embeddings,比如BERT,GPT等。这些编码器任然需要通过下游任务在上下文中表示词语。
2.Background
2.1 Language Representation Learning
The core idea of distributed representation is to describe the meaning of a piece of text by low-dimensional real-valued vectors. And each dimension of the vector has no corresponding sense, while the whole represents a concrete concept.
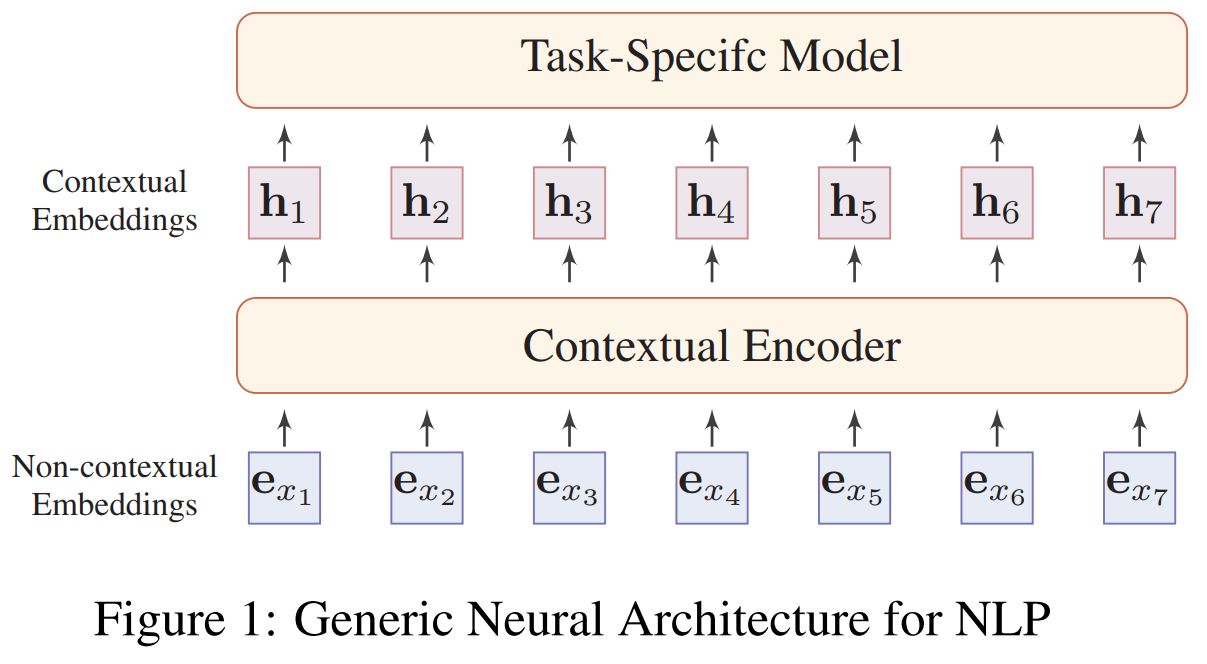
Non-contextual Embeddings
这一步主要是将分割的字符,比如图中的$x$,变成向量表达$e_x \in \mathbb{R}^{D_e}$,$D_e$是词向量维度。向量化过程就是基于一个离线训练的词向量矩阵$E\in \mathbb{R}^{D_e\times |\mathcal{V}|} $做查找,$\mathcal{V}$是词汇表。
这个过程主要有两个问题。第一个是这个词向量是静态的,没有考虑上下文含义,无法处理多义词。第二个是oov问题,许多算法可以缓解这个问题,比如基于character level,比如基于subword,subword算法有BPE,CharCNN等。
Contextual Embeddings
To address the issue of polysemous and the context-dependent nature of words, we need distinguish the semantics of words in different contexts:
其中$f_{enc}(\cdot)$为深度编码器。$\textbf{h}_t$就是contextual embedding或者dynamical embedding。
2.2 Neural Contextual Encoders
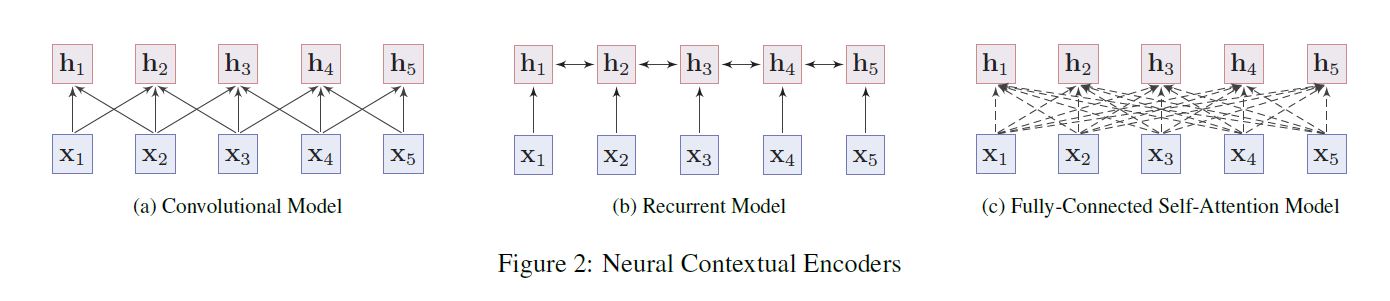
可以分成两类,sequence models and non-sequence models。
2.2.1 sequence models
sequence models 分为两类,Convolutional Models和Recurrent Models,见上图。
Convolutional
Convolutional models take the embeddings of words in the input sentence and capture the meaning of a word by aggregating the local information from its neighbors by convolution operations
Recurrent
Recurrent models capture the contextual representations of words with short memory, such as LSTMs and GRUs . In practice, bi-directional LSTMs or GRUs are used to collect information from both sides of a word, but its performance is often affected by the long-term dependency problem.
2.2.2 non-sequence models
transformer: model the relation of every two words
2.2.3 Analysis
Sequence models:
1.Sequence models learn the contextual representation of the word with locality bias and are hard to capture the long-range interactions between words.
2.Nevertheless, sequence models are usually easy to train and get good results for various NLP tasks.
fully-connected self-attention model:
1.can directly model the dependency between every two words in a sequence, which is more powerful and suitable to model long range dependency of language
2.However, due to its heavy structure and less model bias, the Transformer usually requires a large training corpus and is easy to overfit on small or modestly-sized datasets
结论:the Transformer has become the mainstream architecture of PTMs due to its powerful capacity.
2.3 Why Pre-training?
- Pre-training on the huge text corpus can learn universal language representations and help with the downstream tasks.
- Pre-training provides a better model initialization,which usually leads to a better generalization performance and speeds up convergence on the target task.
- Pre-training can be regarded as a kind of regularization to avoid overfitting on small data
3 Overview of PTMs
3.1 Pre-training Tasks
预训练任务对于学习通用语言表示至关重要。通常,这些预训练任务应具有挑战性,并拥有大量训练数据。在本节中,我们将预训练任务分成三个类别:Supervised learning、Unsupervised learning和Self-Supervised learning。
Self-Supervised learning: is a blend of supervised learning and unsupervised learning. The learning paradigm of SSL is entirely the same as supervised learning, but the labels of training data are generated automatically. The key idea of SSL is to predict any part of the input from other parts in some form. For example, the masked language model (MLM) is a self-supervised task that attempts to predict the masked words in a sentence given the rest words.
接下来基于介绍常用的基于Self-Supervised learning的预训练任务。
3.1.1 Language Modeling (LM)
3.1.2 Masked Language Modeling (MLM)
3.1.3 Permuted Language Modeling (PLM)
3.1.4 Denoising Autoencoder (DAE)
3.1.5 Contrastive Learning (CTL)
nsp也属于CTL
https://zhuanlan.zhihu.com/p/360892229
3.1.6 Others
3.2 Taxonomy of PTMs
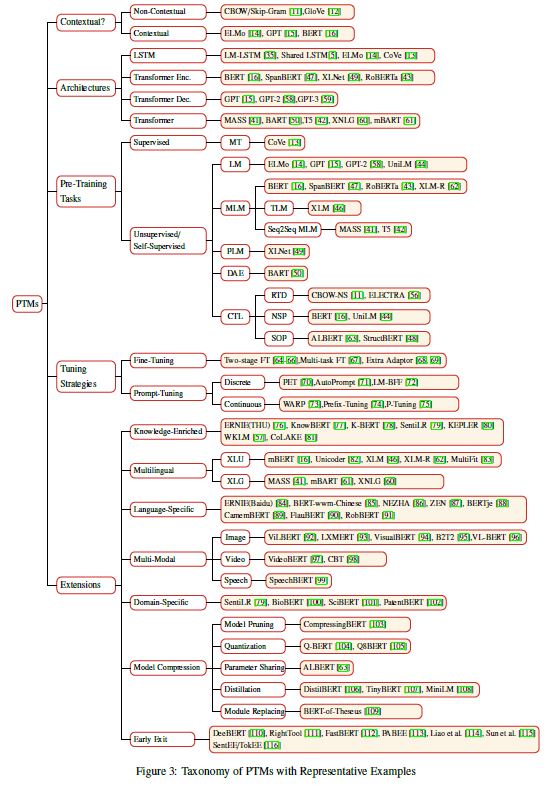
作者从以下四个角度,即Representation Type,Architectures,Pre-Training Task Types,Extensions,对现有的PTM分类,分类结果如上。图和这里有一点不统一,是作者没注意?图里有5个类别,多了Tuning Strategies,而且Representation Type在图中为Contextual?。
3.3 Model Analysis
4 Extensions of PTMs
4.1 Knowledge-Enriched PTMs
4.2 Multilingual and Language-Specific PTMs
4.3 Multi-Modal PTMs
4.4 Domain-Specific and Task-Specific PTMs
4.5 Model Compression
5 Adapting PTMs to Downstream Tasks
虽然PTM学习了很多通用知识,但是如何将这些知识有效应用到下游任务是个挑战。
5.1 Transfer Learning
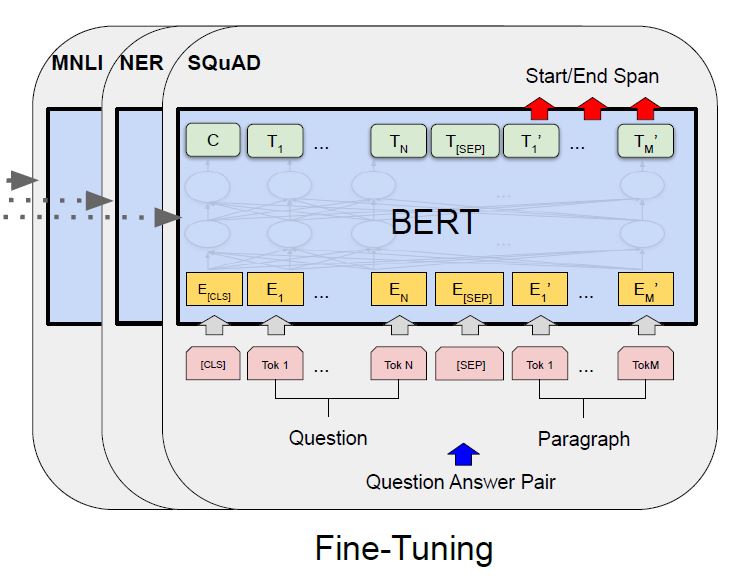
Transfer learning is to adapt the knowledge from a source task (or domain) to a target task (or domain).如下图。
5.2 How to Transfer?
5.2.1 Choosing appropriate pre-training task, model architecture and corpus
5.2.2 Choosing appropriate layers
使用哪些层参与下游任务
选择的层model1+下游任务model2
对于深度模型的不同层,捕获的知识是不同的,比如说词性标注,句法分析,长期依赖,语义角色,协同引用。对于RNN based的模型,研究表明多层的LSTM编码器的不同层对于不同任务的表现不一样。对于transformer based 的模型,基本的句法理解在网络的浅层出现,然而高级的语义理解在深层出现。
用$\textbf{H}^{l}(1<=l<=L)$表示PTM的第$l$层的representation,$g(\cdot)$为特定的任务模型。有以下几种方法选择representation:
a) Embedding Only
choose only the pre-trained static embeddings,即$g(\textbf{H}^{1})$
b) Top Layer
选择顶层的representation,然后接入特定的任务模型,即$g(\textbf{H}^{L})$
c) All Layers
输入全部层的representation,让模型自动选择最合适的层次,然后接入特定的任务模型,比如ELMo,式子如下
其中$\alpha$ is the softmax-normalized weight for layer $l$ and $\gamma$ is a scalar to scale the vectors output by pre-trained model
5.2.3 To tune or not to tune?
总共有两种常用的模型迁移方式:feature extraction (where the pre-trained parameters are frozen), and fine-tuning (where the pre-trained parameters are unfrozen and fine-tuned).
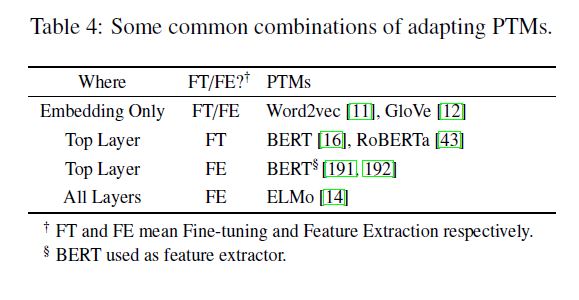
选择的层model1参数是否固定,model2一定要训练
bert 只有top layer finetune????
5.3 Fine-Tuning Strategies
Two-stage fine-tuning
第一阶段为中间任务,第二阶段为目标任务
Multi-task fine-tuning
multi-task learning and pre-training are complementary technologies.
Fine-tuning with extra adaptation modules
The main drawback of fine-tuning is its parameter ineffciency: every downstream task has its own fine-tuned parameters. Therefore, a better solution is to inject some fine-tunable adaptation modules into PTMs while the original parameters are fixed.
Others
self-ensemble ,self-distillation,gradual unfreezing,sequential unfreezing
参考
https://arxiv.org/pdf/2003.08271v4.pdf