Spark vs MapReduce
对比
https://www.educba.com/mapreduce-vs-spark/
| MapReduce | Spark | |
|---|---|---|
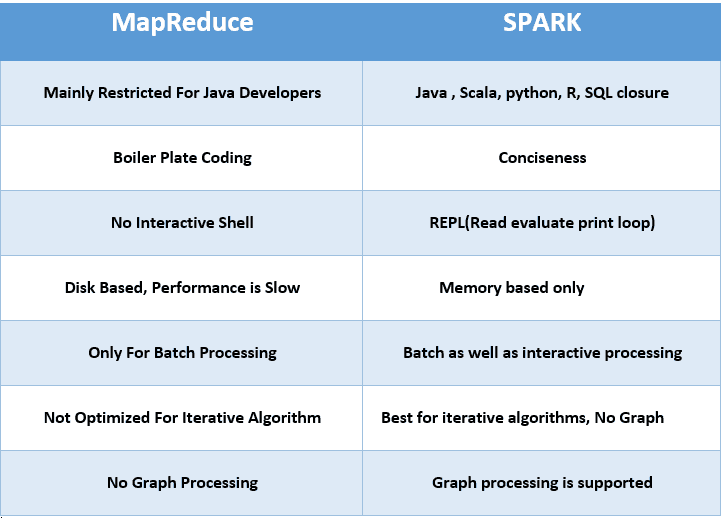
| Product’s Category | From the introduction, we understood that MapReduce enables the processing of data and hence is majorly a data processing engine. | Spark, on the other hand, is a framework that drives complete analytical solutions or applications and hence making it an obvious choice for data scientists to use this as a data analytics engine. |
| Framework’s Performance and Data Processing | In the case of MapReduce, reading and writing operations are performed from and to a disk thus leading to slowness in the processing speed. | In Spark, the number of read/write cycles is minimized along with storing data in memory allowing it to be 10 times faster. But spark may suffer a major degradation if data doesn’t fit in memory. |
| Latency | As a result of lesser performance than Spark, MapReduce has a higher latency in computing. | Since Spark is faster, it enables developers with low latency computing. |
| Manageability of framework | MapReduce being only a batch engine, other components must be handled separately yet synchronously thus making it difficult to manage. | Spark is a complete data analytics engine, has the capability to perform batch, interactive streaming, and similar component all under the same cluster umbrella and thus easier to manage! |
| Real-time Analysis | MapReduce was built mainly for batch processing and hence fails when used for real-time analytics use cases. | Data coming from real-time live streams like Facebook, Twitter, etc. can be efficiently managed and processed in Spark. |
| Interactive Mode | MapReduce doesn’t provide the gamut of having interactive mode. | In spark it is possible to process the data interactively |
| Security | MapReduce has accessibility to all features of Hadoop security and as a result of this, it is can be easily integrated with other projects of Hadoop Security. MapReduce also supports ASLs. | In Spark, the security is by default set to OFF which might lead to a major security fallback. In the case of authentication, only the shared secret password method is possible in Spark. |
| Tolerance to Failure | In case of crash of MapReduce process, the process is capable of starting from the place where it was left off earlier as it relies on Hard Drives rather than RAMs | In case of crash of Spark process, the processing should start from the beginning and hence becomes less fault-tolerant than MapReduce as it relies of RAM usage. |
spark为什么比MapReduce快
https://blog.csdn.net/JENREY/article/details/84873874
1 spark基于内存 ,mapreduce基于磁盘
指的是中间结果
MapReduce:通常需要将计算的中间结果写入磁盘,然后还要读取磁盘,从而导致了频繁的磁盘IO
Spark:不需要每次将计算的中间结果写入磁盘
2 spark粗粒度资源申请,MapReduce细粒度资源申请
spark 执行task不需要自己申请资源,提交任务的时候统一申请了
MapReduce 执行task任务的时候,task自己申请
3 spark基于多线程,mapreduce基于多进程