Learning to Rank From Pairwise Approach to Listwise Approach(listnet)
https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/tr-2007-40.pdf
https://blog.csdn.net/Mr_tyting/article/details/80554849
核心思想为:
- Given two lists of scores(模型和人)
- we can first calculate two permutation probability distributions from them(简化到用top1)
- and then calculate the distance between the two distributions as the listwise loss function.(交叉熵)
4. Probability Models
4.1. Permutation Probability

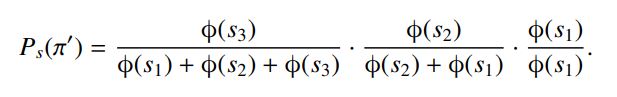
$\pi=(2,3,1) $指的是对象2排在第一位
上面是topn的形式
因为总共有n!次排序组合
4.2. Top One Probability
topk:
总共有N ! / ( N − k ) ! 种不同排列,大大减少了计算复杂度
top1:

此时有n种不同排列情况
概率分布的含义:对于每个j,分别都处于第一的概率是多少
5.Learning Method: ListNet
We employ a new learning method for optimizing the listwise loss function based on top one probability, with Neural Network as model and Gradient Descent as optimization algorithm. We refer to the method as ListNet.

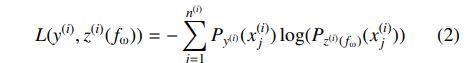
$y^{(i)}$是真实的score list,有个疑问就是$y^{(i)}$怎么得到?关于这个,应该是先有真实的score list(人打),然后基于score list得到排序,参考 https://zhuanlan.zhihu.com/p/66514492
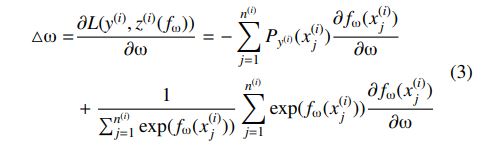

核心步骤
1.打标得到真实的score list,模型得到预测的score list
2.然后用softmax得到真实的和预测的score list的概率分布
3.然后用交叉熵计算两种概率分布的差距