rdd
0.分类
算子就是分布式集合对象的api
rdd算子分为两类:1.transformation 2.action
https://blog.csdn.net/weixin_45271668/article/details/106441457
1 共享变量
https://blog.csdn.net/Android_xue/article/details/79780463
https://chowdera.com/2022/02/202202091419262471.html
两种共享变量:广播变量(broadcast variable)与累加器(accumulator)
广播变量解决了什么问题?
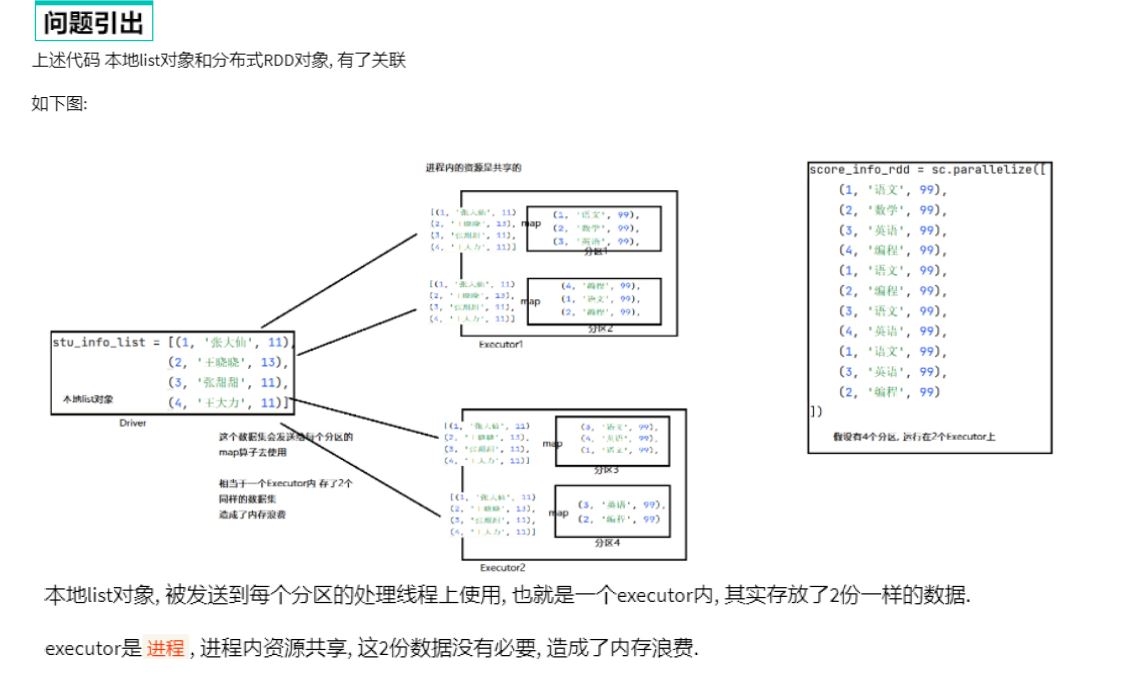
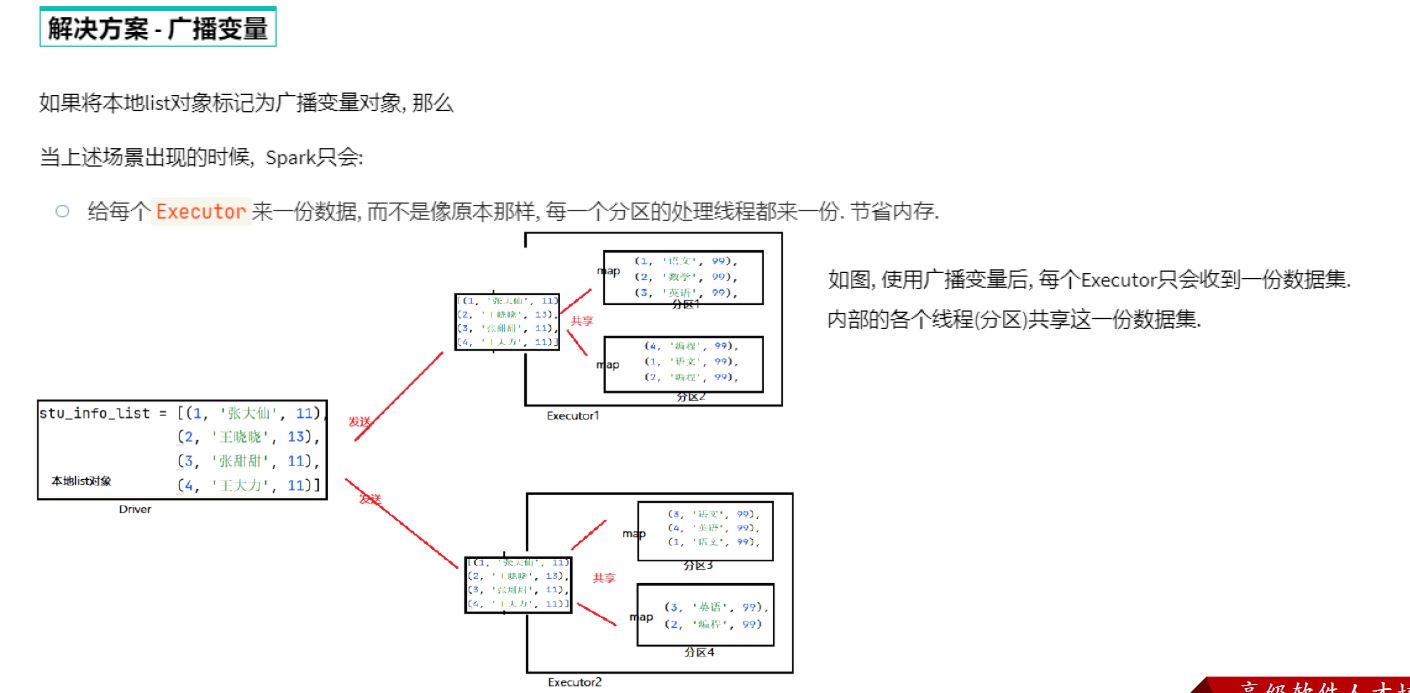
分布式集合RDD和本地集合进行关联使用的时候, 降低内存占用以及减少网络IO传输, 提高性能.
累加器解决了什么问题?
分布式代码执行中, 进行全局累加
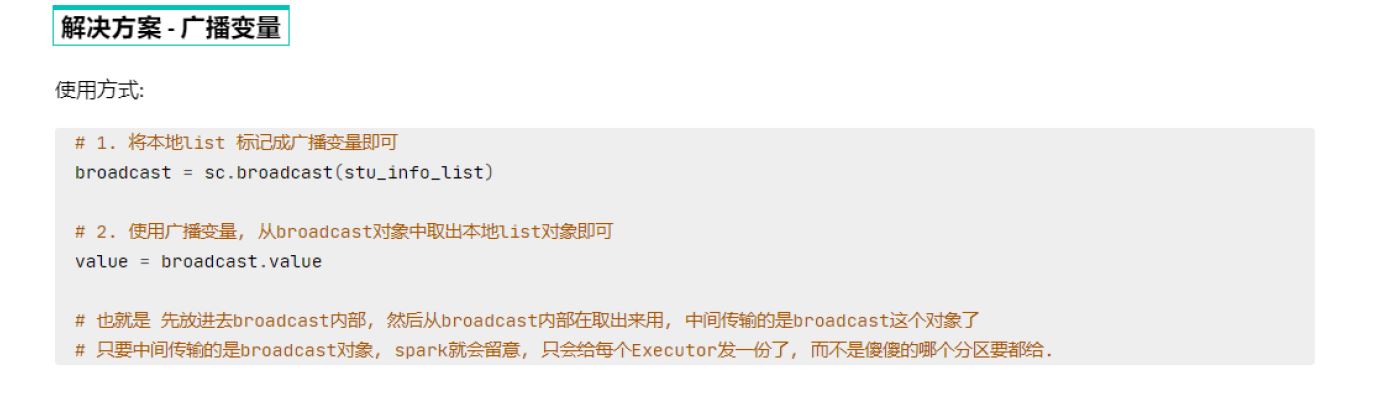
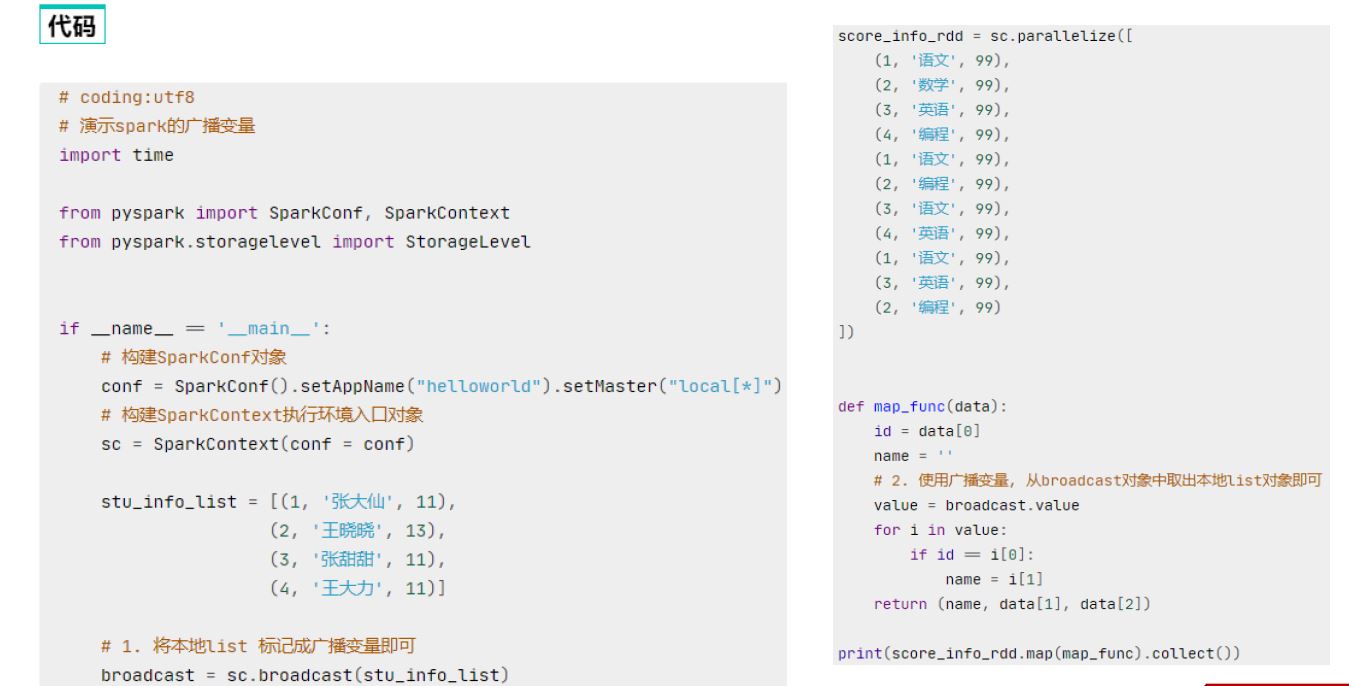
1.广播变量

2.累加器

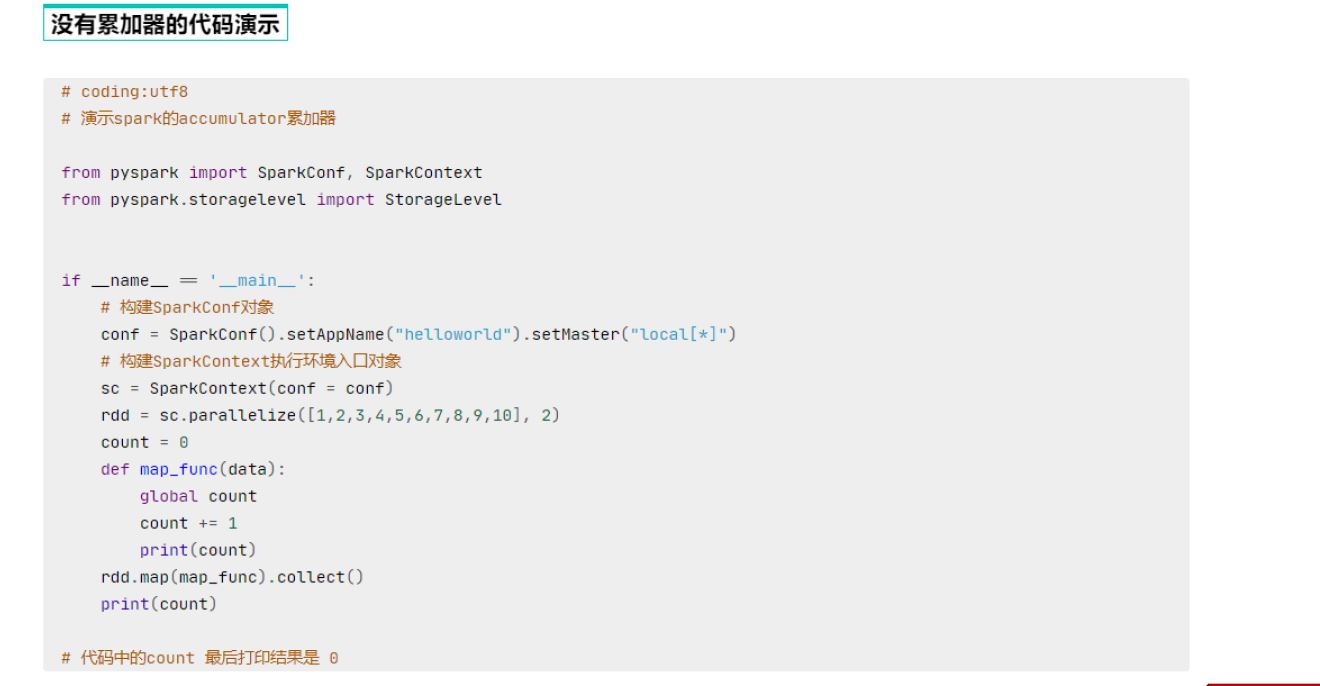


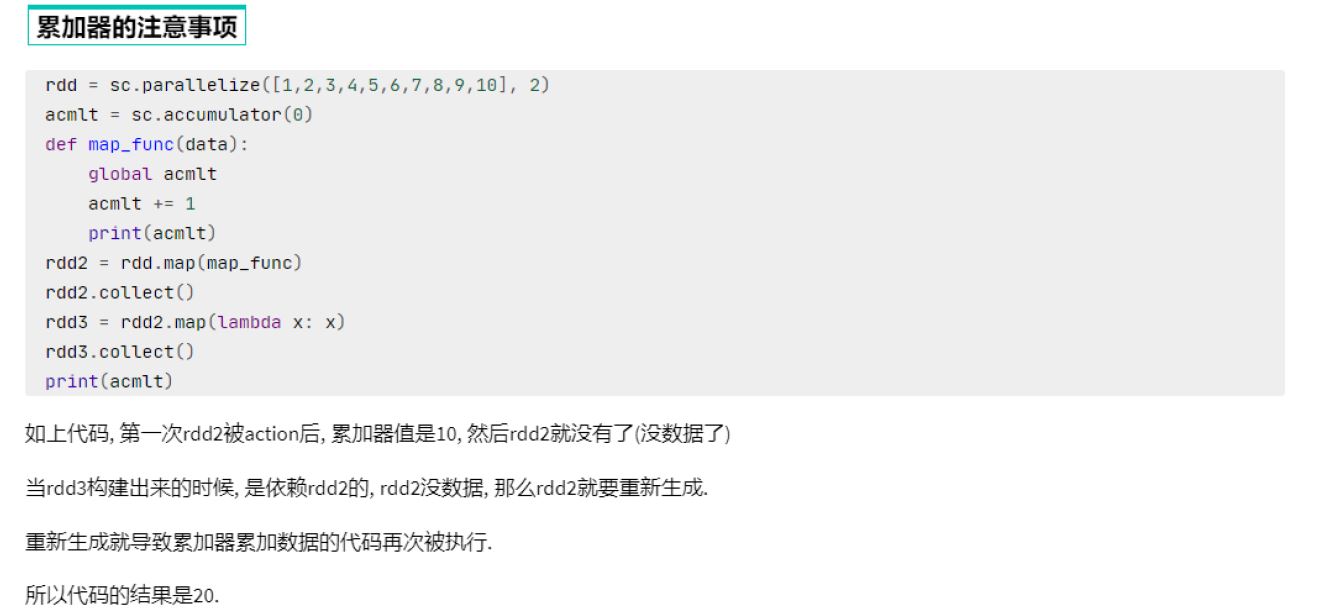
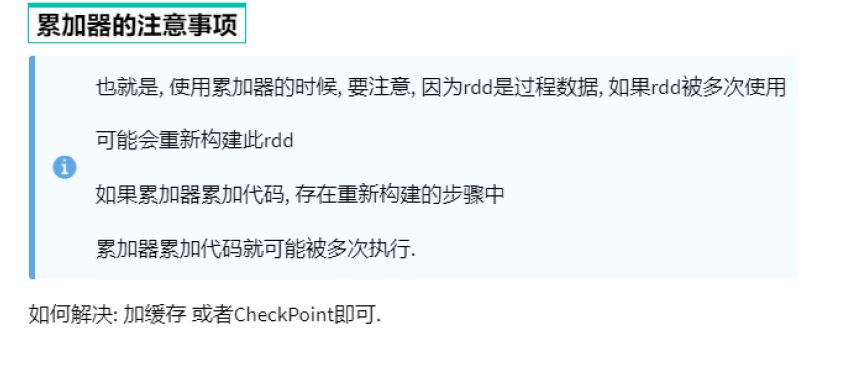
1 | sc = spark.sparkContext |
1 | 55 |
累加器和reduce都可以得到聚合结果,效率???谁先执行 谁短,怎么衡量
2 *ByKey 操作
https://blog.csdn.net/weixin_43810802/article/details/120772452
https://blog.csdn.net/zhuzuwei/article/details/104446388
https://blog.csdn.net/weixin_40161254/article/details/103472056
Use reduceByKey instead of groupByKey
groupByKey creates a lot of shuffling which hampers the performance, while reduceByKey does not shuffle the data as much
3 reduce
1 | in: |
聚合的作用
注意点就是 a,b 操作后的数据类型和a,b保持一致,举个例子 a+b 和a ,b类型一致,否则(a+b)+c会报错
4 collect、 take、top、first,foreach
1 collect
collect()
返回包含此RDD中的所有元素的列表
注意:因为所有数据都会加载到driver,所有只适用于数据量不大的情况
2 first
first()
返回RDD中的第一个元素
3 take
take(num)
取RDD的前num个元素
4 top
top(num, key=None)
排序
Get the top N elements from an RDD
5 foreach
foreach(f)
Applies a function to all elements of this RDD 分区输出
1 | def f(x): |