基于问题在段落中寻找答案
1
2
3
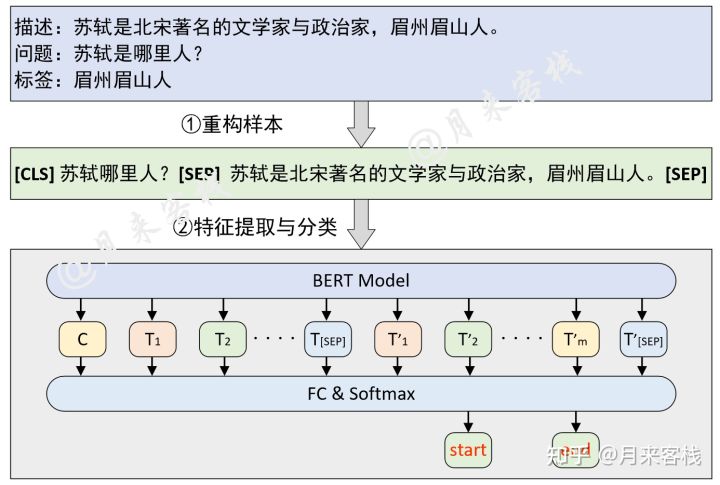
| 1 问题:苏轼是哪里人?
2 描述:苏轼是北宋著名的文学家与政治家,眉州眉山人。
3 标签:眉州眉山人
|
bert中的SQuAD问答任务
标签
引入start 和 end 标签
结构
损失
1
2
3
4
5
6
7
8
9
| sequence_output = all_encoder_outputs[-1] #[src_len, batch_size, hidden_size]
logits = self.qa_outputs(sequence_output) # [src_len, batch_size,2]
start_logits, end_logits = logits.split(1, dim=-1)
start_logits = start_logits.squeeze(-1).transpose(0, 1) # [batch_size,src_len]
end_logits = end_logits.squeeze(-1).transpose(0, 1) # [batch_size,src_len]
loss_fct = nn.CrossEntropyLoss(ignore_index=ignored_index)
start_loss = loss_fct(start_logits, start_positions)
end_loss = loss_fct(end_logits, end_positions)
final_loss=(start_loss + end_loss) / 2
|
模型输出为: [src_len, batch_size,2]
两个(start 和 end )src_len分类的平均
预测
假设候选文本长度为n,输出n个2分类结果,选出最大的start概率和end概率最为start和end label
参考
https://zhuanlan.zhihu.com/p/77868938
https://blog.csdn.net/guangyacyb/article/details/105526482
https://zhuanlan.zhihu.com/p/473157694