transformer(attention is all your need)
1.We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely.
2.Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train.
![]()
1 Positional Encoding
in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence. There are many choices of positional encodings, learned and fixed [9]. In this work, we use sine and cosine functions of different frequencies:
详细可参考 https://wmathor.com/index.php/archives/1453/
2 Attention
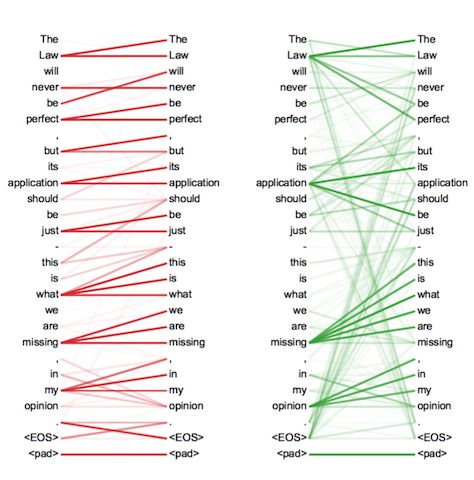
其中不同颜色表示不同head,颜色深浅表示词的关联程度。
不同head表示不同应用场景 ,单一head表示某个场景下,各个字之间的关联程度
1 Scaled Dot-Product Attention
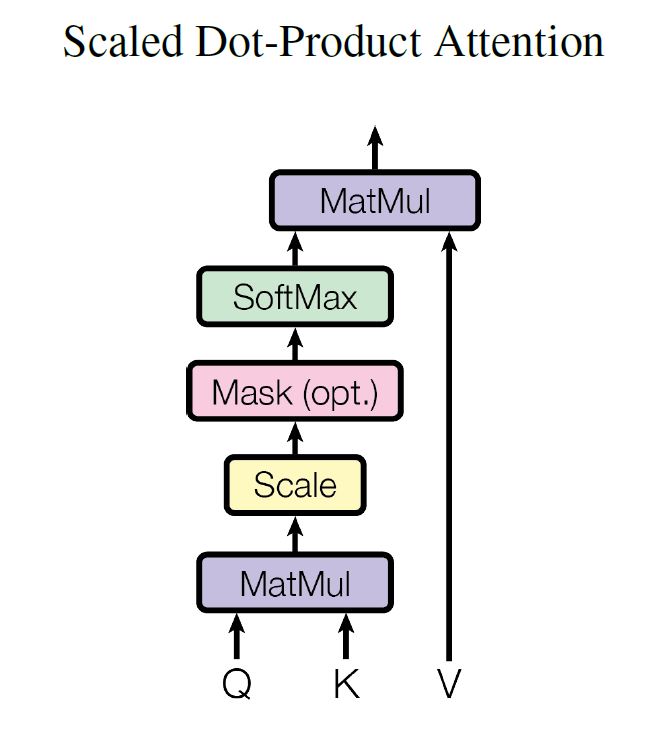
$d_{k}$ : keys of dimension
为什么scale?We suspect that for large values of dk, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients.
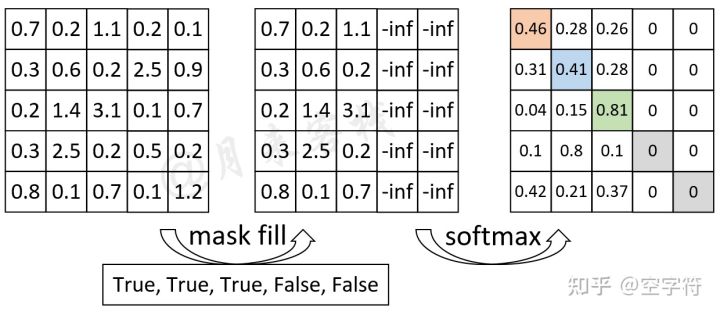
Mask
可以分为两类:Attention Mask和Padding Mask,接下来具体讲解。
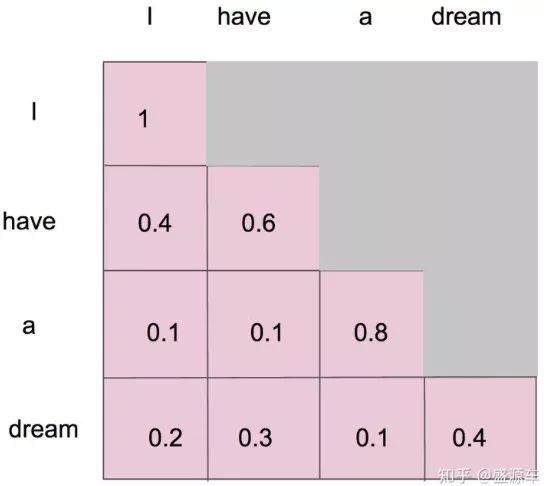
1.Attention Mask
ensures that the predictions for position i can depend only on the known outputs at positions less than i.
sotfmax前要mask,上三角mask掉
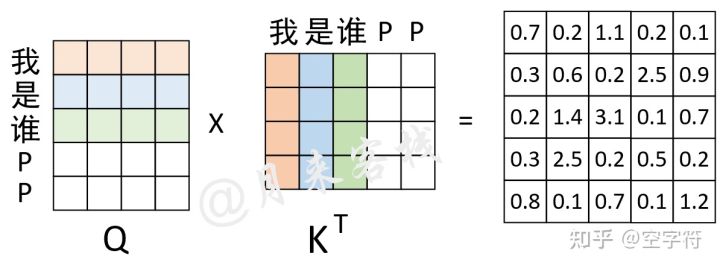
2.Padding Mask
Padding位置上的信息是无效的,所以需要丢弃。
过程如下图示:
2 Multi-Head Attention
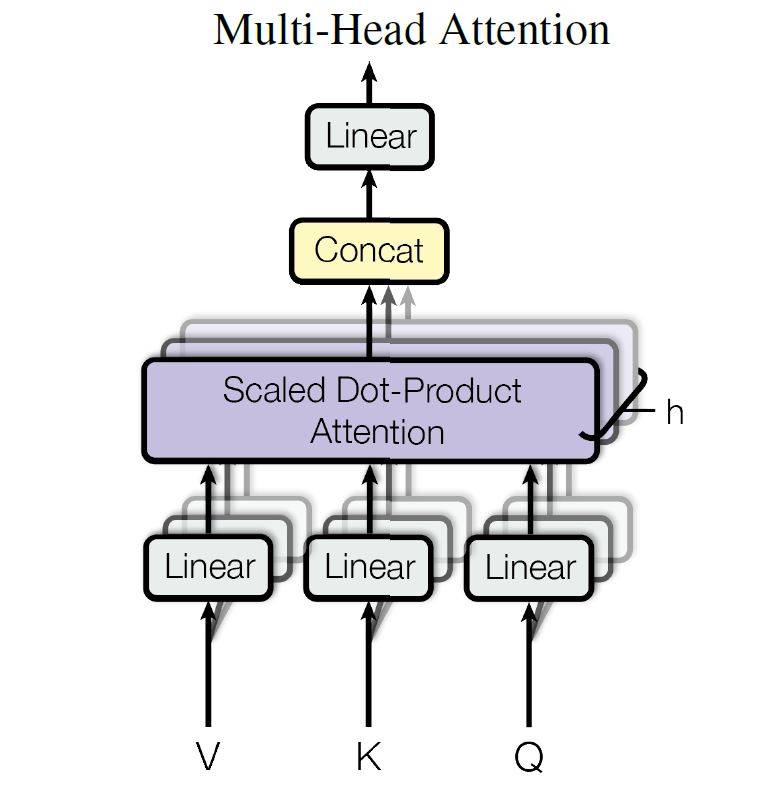
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.
3 Applications of Attention in our Model
1.encoder-decoder attention layers
结构:queries come from the previous decoder layer,and the memory keys and values come from the output of the encoder.
目的:This allows every position in the decoder to attend over all positions in the input sequence.
2.encoder contains self-attention layers
结构:keys, values and queries come from the same place
目的:Each position in the encoder can attend to all positions in the previous layer of the encoder.
3.self-attention layers in the decoder
结构:keys, values and queries come from the same place
目的:allow each position in the decoder to attend to all positions in the decoder up to and including that position
3 Encoder and Decoder Stacks
1 encoder
1).Input Embedding与Positional Encoding
2). multi-head attention
3). 残差连接与 Layer Normalization
4). FeedForward
5). 残差连接与 Layer Normalization
其中$ X_{hidden} \in \mathbb{R}^{batch_size \ \ seq_len \ \ embed_dim} $
2 decoder
我们先从 HighLevel 的角度观察一下 Decoder 结构,从下到上依次是:
- Masked Multi-Head Self-Attention
- Multi-Head Encoder-Decoder Attention
- FeedForward Network
4 常见问题
1 并行化
训练encoder,decoder都并行,测试encoder并行,decoder不是并行
https://zhuanlan.zhihu.com/p/368592551
2 self-attention和普通attention的区别
取决于query和key是否在一个地方
3 Why Self-Attention
Motivating our use of self-attention we consider three desiderata.
1.One is the total computational complexity per layer.
2.Another is the amount of computation that can be parallelized, as measured by the minimum number of sequential operations required.
3.The third is the path length between long-range dependencies in the network